Blackfin Speedway Presentation Core, Memory, and Peripherals
660 likes | 876 Vues
Blackfin Speedway Presentation Core, Memory, and Peripherals. Blackfin as a Convergent Processor. Commonly asked questions: What makes Blackfin a “convergent” processor? What architectural features enable convergent processing?

Blackfin Speedway Presentation Core, Memory, and Peripherals
E N D
Presentation Transcript
Blackfin as a Convergent Processor Commonly asked questions: What makes Blackfin a “convergent” processor? What architectural features enable convergent processing? What type of performance can Blackfin achieve from a networking standpoint?
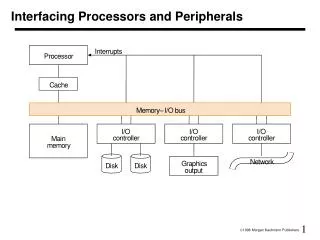
Agenda • Blackfin “Convergent Processing” • Blackfin Core Details • Registers • ALU, MAC, Shifter • Sequencer, Pipeline, Event Controller • Blackfin Memory • Memory Architecture • Cache • Peripherals • General Peripherals (UART,SPORT, SPI, TWI, WD, RTC) • Ethernet, CAN • PPI • DMA
What architectural features enable convergent processing? • Integrated instruction set architecture • Single instruction set for signal processing and control • Programmable interrupt levels • Real-time tasks get the highest priority level • Memory protection with an MMU • Regions of memory can be protected from access • Networked peripherals in addition high speed connectivity to ADC, DAC and video peripherals • Unified address space and byte addressable • Support for User and Supervisor modes • Robust ALU including both signal processing functions as well as traditional MPC/MPU functions
What makes Blackfin a Convergent Processor? • Blackfin has a mature compiler that produces highly optimized code (with an option to produce “dense code” for control applications) • Blackfin processors come with a full suite of C-based device drivers for peripherals • Fully documented, common APIs • Blackfin beats the competition in terms of DSP benchmarks and it is on par with ARM code density benchmarks • Blackfin is scalable across a broad set of applications • ADSP-BF531 on the low end • Dual-core ADSP-BF561 on the high end • Latest peripheral integration expands connectivity to network-based applications • Large set of options for OS and kernel support, including uCLinux
Blackfin Architecture Basics Core Registers ALU, MAC, Shifter Data Addressing Modes Program Sequencer Event Controller Peripherals Instruction Set Overview Memory Architecture Cache
Accessing Registers • Blackfin processors are register-intensive devices • All computations are performed on data contained in registers • All peripherals are setup using registers • Memory is accessed using pointers in address registers • There are two types of Blackfin processor registers • Core registers • Memory-mapped registers (MMRs)
Blackfin Core Registers • Core registers are accessed directly by name • Data Registers: R0-R7 • Accumulator Registers: A0, A1 • Pointer Registers: P0-P5, FP, SP,USP • DAG Registers: I0-I3, M0-M3, B0-B3, L0-L3 • Cycle Counters: CYCLES, CYCLES2 • Program Sequencer: SEQSTAT • System Configuration Register: SYSCFG • Loop Registers: LT[1:0], LB[1:0], LC[1:0] • Interrupt Return Registers: RETI, RETX, RETN, RETE Example: R0 = SYSCFG; // Load data register with contents of SYSCFG register
Core Registers 0 31 Data Registers P0 31 15 39 Address Registers P1 A0.H A0.L A0X P2 A1.H A0.L A1X P3 31 15 R0 P4 R0.H R0.L P5 R1 R1.H R1.L R2 FP R3 SP R4.H R4.L R4 USP 31 31 0 31 0 31 0 0 R5 I0 L0 B0 M0 R6 I1 L1 B1 M1 R7 R7.H R7.L I2 L2 B2 M2 I3 L3 B3 M3 Arithmetic Status ASTAT LC0 Loop Counter Loop Top Loop Bottom LT0 Shaded registers only accessible in Supervisor mode LB0 Subroutine Return RETS LC1 Interrupt Return RETI LT1 Exception Return RETX LB1 NMI Return RETN SYSCFG System Config Emulation Return RETE SEQSTAT Sequencer Status
Memory-Mapped Registers (MMRs) • A majority of registers are memory-mapped and must be accessed indirectly • Core MMRs are used to configure the core registers • They are listed in Appendix A of the HRM • All Core MMRs must be accessed with 32-bit reads or writes • System MMRs are used to configure all other peripherals • They are listed in Appendix B of the HRM • Some System MMRs must be accessed with 32-bit reads or writes and others with 16-bit reads or writes (See the HRM for details) • MMR addresses are defined in header files • defBF53x.h for assembly • cdefBF53x.h for C/C++ • MMRs can only be accessed in Supervisor mode Assembly Example: P0.H = HI(SPI_RDBR); // load upper 16-bits of SPI Receive Register address to pointer register P0.L = LO(SPI_RDBR); // load lower 16-bits of SPI Receive Register address to pointer register R0 = W[P0] (z); // read 16-bit SPI Receive Register (SPI_RDBR) into data register C/C++ Example: short temp; // define variable to store contents temp = *pSPI_RDBR; // read 16-bit SPI Receive Register contents into data element
Arithmetic Logic Unit (ALU) Data Arithmetic Unit LD0 32-bits 16 16 8 8 8 8 R7 R7.H R7.L R6 R6.H R6.L LD1 32-bits R5 R5.H R5.L R4 barrel R4.H R4.L 40 40 shifter R3 SD 32-bits R3.H R3.L R2 R2.H R2.L R1 R1.H R1.L A0 A1 R0 R0.H R0.L
Arithmetic Logic Unit (ALU) • Two 40-bit ALUs operate on 16-bit, 32-bit, and 40-bit input data and output 16-bit, 32-bit, and 40-bit results. • Functions • Fixed-point addition and subtraction • Addition and subtraction of immediate values • Accumulation and subtraction of multiplier results • Logical AND, OR, NOT, XOR, bitwise XOR (LFSR), Negate • Functions: ABS, MAX, MIN, Round, division primitives • Supports conditional instructions • Four 8-bit video ALUs
40-bit ALU Operations • 40-bit ALU operations support the following combinations: • Single 16-Bit Operations • Dual 16-Bit Operations • Quad 16-Bit Operations • Single 32-Bit Operations • Dual 32-Bit Operations
Multiply-Accumulators (MAC) Data Arithmetic Unit LD0 32-bits 16 16 LD1 32-bits 8 8 8 8 R7 R7.H R7.L R6 R6.H R6.L SD 32-bits R5 R5.H R5.L R4 R4.H R4.L barrel 40 40 R3 R3.H R3.L shifter R2 R2.H R2.L R1 R1.H R1.L R0 R0.H R0.L A0 A1
Multiply-Accumulators (MAC) • Two identical MACs • Each performs fixed-point multiplication and multiply-accumulate operations on 16-bit fixed-point input data and outputs 32-bit or 40-bit results. • Functions • Multiplication • Multiply-accumulate with addition • Multiply-accumulate with subtraction • Dual versions of the above • Features • Saturation of accumulator results • Optional rounding of multiplier results
Barrel-Shifter (Shifter) Data Arithmetic Unit 16 16 8 8 8 8 R7 R7.H R7.L LD0 32-bits R6 R6.H R6.L R5 R5.H R5.L R4 R4.H R4.L R3 barrel R3.H R3.L LD1 32-bits 40 40 R2 R2.H R2.L shifter R1 R1.H R1.L R0 SD 32-bits R0.H R0.L A0 A1
Barrel-Shifter (Shifter) • Performs bitwise shifting for 16-bit, 32-bit or 40-bit inputs and yields 16-bit, 32-bit, or 40-bit outputs. • Shift Functions • Arithmetic Shifts preserve the sign of the original number. The sign bit value back-fills the left-most bit positions vacated by the arithmetic right shift. • Logical Shifts discard any bits shifted out of the register and back-fills vacated bits with zeros.
Barrel-Shifter (Shifter) • Additional Functions • Rotate: Rotates a registered number through the CC bit a specified distance and direction. • Bit Operations – Set, Clear, Toggle, Test • Field Extract and Deposit
Address Registers • One set of 32-bit general-purpose Pointer registers • P0-P5, SP and FP • One set of 32-bit DSP buffer addressing registers • I0-I3, B0-B3, L0-L3, M0-M3 • All addresses are byte addresses into a 4 GB address space 31 0 P0 Address Registers P1 P2 P3 P4 P5 SP points to supervisor stack in Supervisor mode and user stack in User mode USP is accessible in supervisor mode only – Allows access to user stack location while in Supervisor mode FP SP USP 31 31 0 31 0 31 0 I0 L0 B0 M0 I1 L1 B1 M1 I2 L2 B2 M2 I3 L3 B3 M3
Addressing Methods • Register Indirect Addressing • Index Registers (32-bit and 16-bit accesses) • Pointer Registers P0 – P5 (32-bit, 16-bit, and 8-bit accesses) • Stack and Frame Pointer Registers (32-bit accesses) • Types of address pointer modify • Modify/Post-Modify • Linear addressing • Circular buffering / modulo addressing • Enables automatic maintenance of pointers to stay within bounds of a circular buffer • Bit-Reversal (Modify only) • Pre-Modify with update (using Stack Pointer) • Pre-Modify without update
Linear vs Circular Buffering • Linear Buffer Access • Index (I0:3) registers hold the address sent out on the address bus. • Length (L0:3) register set to 0, thus disabling circular buffering. • Default for C compiler • Provisions in compiler to allow circular buffers • Modify (M0:3) registers contain the value (positive or negative) that is added to the I registers at the end of each memory access. • Circular Buffer Access • Base (B0:3) registers contain the circular buffer’s start address. • Length (L0:3) register set to length of circular buffer. • Modify (M0:3) value must be less than or equal to the length of the circular buffer. • Indexing wraps back to Base address when Index modification exceeds Base + Length
0x00000001 0x00000001 0x00000002 0x00000002 0x00000003 0x00000003 0x00000004 0x00000004 0x00000005 0x00000005 0x00000006 0x00000006 0x00000007 0x00000007 0x00000008 0x00000008 0x00000009 0x00000009 0x0000000A 0x0000000A 0x0000000B 0x0000000B Circular Buffer Example Address 0 4 8 C 10 14 18 1C 20 24 28 1st Access 4th Access 2nd Access 5th Access 3rd Access • Base Address and Starting Index Address (B0 = 0; I0 = 0;) • Buffer Length is 44 (L0 = 44;) • There are 11 data elements and each data element is 4 bytes • Modify Value is 16 (M0 = 16;) • 4 elements * 4 bytes/element
Program Sequencer Features • Controls all program flow • Contains a 10-stage instruction pipeline • Maintains in-program branching • Subroutines • Jumps • Interrupts and Exceptions • Maintains loops • Includes zero-overhead loop registers • No cost for wrapping from loop bottom to loop top
Blackfin Execution Pipeline • 10-stage super-pipeline • Sequencer ensures that the pipeline is fully interlocked and that all the data hazards are hidden from the programmer • If executing an instruction that requires data to be fetched, the pipeline will stall until that data is available • See EE-197 application note for a complete list of stalls and multi-cycle instructions: http://www.analog.com/ee-notes
Avoiding Pipeline Stalls • Most common numeric operations have no instruction latency • VisualDSP++ Pipeline Viewer highlights Stall and Kill conditions
Section 10 Section 7Event Controller
Events (Interrupts / Exceptions) • The Event Controller manages 5 types of Events • Emulation (via external pin) • Reset (via SW or external pin) • Non-Maskable Interrupt (NMI) - for events that require immediate processor attention (via SW, external pin, or Watchdog) • Exception • Interrupts • Hardware Error • Core Timer • 9 General-Purpose Interrupts for servicing peripherals • Can be custom prioritized for optimal system performance • All events can be serviced by Interrupt Service Routines (ISR)
INTERRUPTS Hardware-generated Asynchronous to program flow Requested by a peripheral Software-generated Synchronous to program flow Generated by RAISE instruction All instructions preceding the interrupt in the pipeline are killed EXCEPTIONS Service Exception Return address (RETE) is the address following the excepting instruction Never re-executed EXCPT instruction is in this category Error Condition Exception Return address (RETE) is the address of the excepting instruction Excepting instruction will be re-executed Interrupts vs. Exceptions The Blackfin is always in Supervisor Mode while executing Event Handler software and can be in User Mode only while executing application tasks.
BF533 System and Core Interrupt Controllers System Interrupt Source IVG # 1 Core Event Name IVG # Event Source Highest P r i o r i t y Lowest 1 Note: Default IVG configuration shown.
Interrupt Service Routine (ISR) • ISR address is stored in the Event Vector Table • Used as the next fetch address when the event occurs • Program Counter (PC) address is saved to a register • RETI, RETX, RETN, RETE, based on event • Always concludes with “Return” Instruction • RTI, RTX, RTN, RTE (respectively) • When executed, PC is loaded with address stored in RETI, RETX, RETN, or RETE to continue app code • Optional nesting of higher-priority interrupts possible • See appnote EE-192, which covers writing interrupt routines in C (http://www.analog.com/ee-notes)
Peripherals and Power Management Common Peripherals (All Blackfins) • SPI, UART, SPORT, WD, RTC • PPI BF534/BF536/BF537 Peripherals • TWI, CAN BF536/BF537 Peripheral • Ethernet DMA and Handshake DMA Power Manager
Three Serial Communication Peripherals • SPI (Serial Peripheral Interface) • High-Speed SPI port (up to SCLK/4, max 33.25 MHz) • Master/Slave compatible with control of up to 7 slave-selects • Single-Duplex DMA (Either TX or RX) • Typically used to interface with serial EPROMS, CPUs, converters, and displays • UART (Universal Asynchronous Receiver/Transmitter) • PC-style UART port (baud rate up to SCLK/16, max 8.3125 MHz) • Supports half-duplex IrDA SIR (9.6/115.2 Kbps rate) • Autobaud detection support through the use of the Timers • Separate TX and RX DMA support • Typically used for maintenance port or interfacing with slow serial peripherals • SPORTs (Synchronous Serial Ports) • High Speed Serial Port (up to SCLK/2, max 66.5 MHz) • Variable word length support (3 - 32 bits) • I2S-Compatible • Separate TX and RX DMA support • 128 Channels out of 1024-Channel Window for TDM support • Primary and Secondary Data channels • Typically used for interfacing with CODECs and TDM data streams
Real-Time Clock Features • Used to implement real-time watch or “life counter” • Time of day, alarm, stopwatchcount-down, and elapsed time since last system reset • Uses four counters - Seconds, Minutes, Hours, Days • Equipped with two alarm features • Daily and Day-And-Time • Uses dedicated 32.768 kHz crystal to RTXI / RTXO • Can be pre-scaled to 1 Hz to count in real-time seconds • Uses dedicated power supply pins • Independent of any reset • Can take processor out of all low-power states
PPI – What is it? • Parallel Peripheral Interface • Programmable bus width (from 8 – 16 bits in 1-bit steps) • Bidirectional (half-duplex) parallel interface • Synchronous Interface • Interface is driven by an external clock (“PPI_CLK”) • Up to 66MHz rate (SCLK/2) • Asynchronous to SCLK • Includes three frame syncs to control the interface timing • Applications • Driving LCD Interface • General Purpose Interface to outside world • High speed data converters • Video CODECs
TWO-WIRE INTERFACE (TWI) • Fully compliant to the Philips I2C bus protocol • See Philips I2C Bus Specification version 2.1 • 7-bit addressing • 100 Kb/s (normal mode) and 400Kb/s (fast mode) data rates • General call address support • Supports Master and Slave operation • Separate receive and transmit FIFOs • SCCB (Serial Camera Control Bus) support • Only in Master mode • Slave mode cannot be used because the TWI controller always issues an Acknowledge in slave mode
Controller Area Network (CAN) • Adheres fully to CAN V2.0B standard • Supports both standard (11-bit) and extended (29-bit) Identifiers • Data Rates up to 1Mbit/second • 32 Configurable Mailboxes • 8 dedicated transmitters and 8 dedicated receivers • 16 configurable (transmit or receive) • Dedicated Acceptance Mask for each Mailbox • Data Filtering (first two bytes) can be used for Acceptance Filtering • CAN wakeup from Hibernation (lowest static power consumption) Mode • CAN Protocol Stacks • Automotive: CAN drivers and protocol stacks through Vector CANtech • Industrial: Leading third parties will provide a full Industrial suite for CANOpen, DeviceNet, etc.
ADSP-BF536/537 Family Ethernet MAC Features ADSP-BF536/537 Ethernet MAC has advanced features beyond IEEE 802.3: For improved performance: Automatic Checksum Computation for IP Header and Payload on RX Frames Programmable RX Data Alignment Mode for 32-bit Alignment Independent RX & TX DMA Channels with Delivery of Frame Status to Memory System Wakeup on Magic Packet for 4 User-Definable Wakeup Frame Filters For lower overall system cost: No PHY XTAL required – Buffered XTAL output from processor feeds PHY Connection to either MII or RMII PHY ADSP-BF536/537 enhances throughput and dataflow via these features: Enhanced DMA channels allow for processor core independence Direction Control to exploit SDRAM physics Four SDRAM rows can be ‘open’ at any given time ADSP-BF536/537 overall networking bandwidth: Full 100Mbps wire speed on 1400-bit payload with an optimized networking stack UDP : ~44% processor core loading TCP/IP: ~75% processor core loading
ADSP-BF536/537 DMA Enhancements • 4 additional DMA channels • All 12 peripheral DMA channels can be assigned to any of the peripherals • Provides MAC further control over the assigned DMA channels • Can reload DMA registers if incorrect checksum is detected • Two External Handshaking Memory DMA Controllers • Good for asynchronous FIFOs or off-chip interface controllers between Blackfin memory and hardware buffers
500 MHz, 1.2V 600 MHz, 1.2V, 264 mW Frequency Only Power Savings 200 MHz, 1.2V, 156 mW Power (mW) Voltage & Frequency 500 MHz, 1.0V Video Processing Audio Processing Blackfin – Dynamic Power Management Increases Battery Life 200 MHz, 0.8V, 90 mW Variable Frequency Clock dividers (1x to 63x) enable low latency changes in system performance Variable Voltage On-Chip Voltage Regulator generates accurate voltage from 2.25 – 3.6V input Core voltage programmable from 0.8V to 1.2V (50 mV increments) Maximum 40usec latency for PLL to relock (Frequency or Voltage changes) System Cost Reduction