Download
1 / 8
80 likes | 178 Vues
Learn how to optimize neural network training parameters with this comprehensive guideline. Understand the impact of weights, activations, and biases on model performance.

E N D
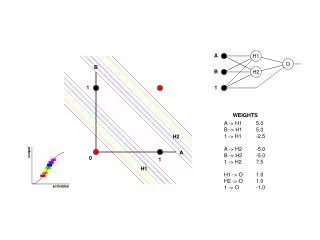
output H1 A activation O H2 B 1 B 1 WEIGHTS A -> H1 5.0 B -> H1 5.0 1 -> H1 -2.5 A -> H2 -5.0 B -> H2 -5.0 1 -> H2 7.5 H1 -> O 1.0 H2 -> O 1.0 1 -> O -1.0 H2 A 0 1 H1
output H1 A activation O H2 B 1 B 1 WEIGHTS A -> H1 5.0 B -> H1 5.0 1 -> H1 -2.5 A -> H2 5.0 B -> H2 5.0 1 -> H2 -7.5 H1 -> O 1.0 H2 -> O -1.0 1 -> O 0.0 H2 A 0 1 H1
output H1 A activation O H2 B 1 B 1 WEIGHTS A -> H1 5.0 B -> H1 5.0 1 -> H1 -2.5 A -> H2 -5.0 B -> H2 -5.0 1 -> H2 7.5 H1 -> O -1.0 H2 -> O 1.0 1 -> O 0.0 H2 A 0 1 H1
output H1 A activation O H2 B 1 B 1 WEIGHTS A -> H1 5.0 B -> H1 5.0 1 -> H1 -2.5 A -> H2 -5.0 B -> H2 -5.0 1 -> H2 7.5 H1 -> O -1.0 H2 -> O -1.0 1 -> O 1.0 H2 A 0 1 H1
output H1 A activation O H2 B 1 B 1 WEIGHTS A -> H1 -5.0 B -> H1 5.0 1 -> H1 2.5 A -> H2 -5.0 B -> H2 5.0 1 -> H2 -2.5 H1 -> O -1.0 H2 -> O 1.0 1 -> O 1.0 H2 A 0 1 H1
output H1 A activation O H2 B 1 B 1 WEIGHTS A -> H1 -5.0 B -> H1 5.0 1 -> H1 2.5 A -> H2 5.0 B -> H2 -5.0 1 -> H2 2.5 H1 -> O -1.0 H2 -> O -1.0 1 -> O 2.0 H2 A 0 1 H1
output H1 A activation O H2 B 1 B 1 WEIGHTS A -> H1 5.0 B -> H1 -5.0 1 -> H1 -2.5 A -> H2 -5.0 B -> H2 5.0 1 -> H2 -2.5 H1 -> O 1.0 H2 -> O 1.0 1 -> O 0.0 H2 A 0 1 H1
output H1 A activation O H2 B 1 B 1 WEIGHTS A -> H1 5.0 B -> H1 -5.0 1 -> H1 -2.5 A -> H2 5.0 B -> H2 -5.0 1 -> H2 2.5 H1 -> O 1.0 H2 -> O -1.0 1 -> O 1.0 H2 A 0 1 H1