Maximizing Execution Efficiency: SIMD Framework & Irregular Data Structures Optimization
Learn how to parallelize irregular data structures using fine-grained SIMD architectures. Explore challenges, design considerations, and benefits of a Compilation/Interpretation framework. Discover optimization strategies for improving performance with case studies demonstrating significant single-core speedups. Evaluate the impact of stream compaction, tiling, and SIMD framework speedup.


Maximizing Execution Efficiency: SIMD Framework & Irregular Data Structures Optimization
E N D
Presentation Transcript
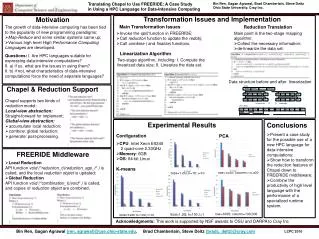
Optimizations for Execution Efficiency Motivation Optimization II: Stream Compaction Compilation/Interpretation Framework • Fine-grained data parallelism is increasingly prevalent – Intel SSE, NVIDIA GPUs, AMD APU • Irregular data structures are widely used in many applications – e.g. Trees, and Graphs • Question: How to parallelize irregular data structures on fine-grained SIMD architectures? • Challenges: • Poor data locality • Dynamic data-driven behavior from control and data dependencies • A common feature of irregular data structure traversals • In the internal node, n, we perform conditional traversal, T(n) • In the leaf node, n’, we perform evaluation W(n’) • Design a Compilation/Interpretation framework to compile T(n), W(n’) operations into domain-specific bytecodes, and interpret them by SIMD interpreter Task Queue for Level-1 Evaluation Ci = Bi + 1 TQ = [a1, b1, c1, d1, e1, f1, g1, h1] next0 = C0 – cond0; next1 = C1 – cond1; next2 = C2 – cond2; next3 = C3 – cond3; Iteration1: Evaluate first 4 Tasks Evaluate next 4 Tasks Get next buffer Get next buffer R = [a2, b2, 0, d2] R = [0, 0, 0, h2] Shuffle Shuffle R = [a2, b2, d2, 0] R = [h2, 0, 0, 0] Store Store TQ = [a2, b2, d2, 0, e1, f1, g1, h1] TQ = [a2, b2, d2, h2, 0, 0, 0, 0] Task Queue for Level-2 Evaluation Optimization I: Branch-less Addressing Optimization III: Intelligent Memory Layouts & Tiling Two Irregular Applications • Tiling trees into smaller bags • Observation: Only a small number of trees are processed at the same time • Tiling can improve the locality of deep levels of trees, especially for SLL and DLL layouts if (cond0){ next0 = B0;} else {next0 = C0; } if (cond1){ next1 = B1;} else {next1 = C1; } if (cond2){ next2 = B2;} else {next2 = C2; } if (cond3){ next3 = B3;} else {next3 = C3; } Random Forests Vectorize by SSE __m128i cond = _mm_cmple_ps(…); __m128i next = Load (C0, C1, C2, C3); next = _mm_add_epi32(next, cond); Input feature vector: <f0 = 0.6, f1 = 0.7, f2 = 0.2, f3 = 0.2> Experimental Results Regular Expression • Impact of SIMD • Impact of Intelligent Layouts Contributions • A compilation/ interpretation approach to traverse and compute on irregular data structures in parallel • Multiple optimization strategies to improve the performance • Two case studies to demonstrate the utility of our approach and show significant single-core speedups • CPU: Intel Xeon E5420 • SIMD Unit: SSE-4 • Compiler: ICC Input String: abbbbba Traversal Issues Speedup over Different Data Layouts Percentage of Time Backend is Stalled • Impact of Stream Compaction • Impact of Tiling • Speedup of our SIMD Framework • Branches on selecting different children • Different structures may have different evaluation lengths– various tasks may exist on the same evaluation level • Poor data locality Benefits of Tiling – Poker Dataset Speedup over Baseline Random Forests Speedup Improvements from SC Speedup over GNU grep Reduction in Workload from SC Execution Time with Tree Levels & Tile Sizes