Download

1 / 30
370 likes | 624 Vues
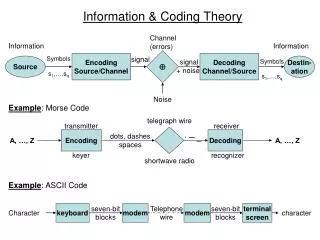
Information and Coding Theory Heuristic data compression codes. Lempel-Ziv encoding. Burrows-Wheeler transform. Juris Viksna, 2014. Lempel-Ziv encoding. [Adapted from D.Ellard]. Lempel-Ziv encoding.

E N D
Information and Coding Theory Heuristic data compression codes. Lempel-Ziv encoding. Burrows-Wheeler transform. Juris Viksna, 2014
Lempel-Ziv encoding [Adapted from D.Ellard]
Lempel-Ziv encoding LZ77 and LZ78 are the two lossless data compression algorithms published in papers by Abraham Lempel and Jacob Ziv in 1977 and 1978. They are also known as LZ1 and LZ2 respectively.These two algorithms form the basis for many variations including LZW, LZSS, LZMA and others. LZW – this is probably the version used in example of Lewis and Denenberg (see the next slides). LZSS – probably the one most often used in practical archiving programs. We will consider also a ‘nice’ binary version from MacKay’s book, but it is not clearly stated from which general version it has been derived. Practical implementations are subject to a number of technical decisions (alphabet used, size of dictionary, packing of bit strings within bytes etc), usually not covered in ‘textbook versions’ of algorithms. [Adapted from en.wikipedia.org]
Lempel-Ziv encoding - example [Adapted from H.Lewis, L.Denenberg]
Lempel-Ziv encoding - ways to deal with full dictionary [Adapted from H.Lewis, L.Denenberg]
Lempel-Ziv encoding - algorithm [Adapted from H.Lewis, L.Denenberg]
Lempel-Ziv encoding - basic algorithm • A bit different and probably better version: • in each stage transfer the pointer to the longest prefix already in a dictionary + a single extra bit. • We don’t need an initial table of symbols (provided they can be transfered “as is” - we can obviously do this in binary case). • We also don’t need to agree on the size of dictionary - simply use the minimal number of bits that covers all existing entries. • Example: • 1011010100010 will be encoded as 100011101100001000010. [Adapted from D.MacKay]
Lempel-Ziv encoding - properties [Adapted from M.Brookes]
Burrows-Wheeler transform • The Burrows-Wheeler Transform (denoted by bwt) is a well • known transformation introduced in • [M. Burrows and D. Wheeler, A block sorting data compression algorithm, Technical report, DIGITAL System Research Center, 1994] • BWT is a reversible transformation that produces a permutation BWT(w) of an input sequence w, defined over an ordered alphabet A, such that the transformed sequence is “easier” to compress than the original one. • The BWT represents for instance the heart of the BZIP2 algorithm that has become the standard for lossless data compression. [Adapted from S.Mantaci]
Burrows-Wheeler transform • Basic Idea: • Sort the characters by their full context (typically done in blocks). This is called the block sorting transform. • Use move-to-front encoding to encode the sorted characters. • The ingenious observation is that the decoder only needs the sorted characters and a pointer to the first character of the original sequence.
Burrows-Wheeler transform a b r a c a # b r a c a # a r a c a # a b a c a # a b r c a # a b r a a # a b r a c # a b r a c a S = abraca M =
Burrows-Wheeler transform # a b r a c a a # a b r a c a b r a c a # a c a # a b r b r a c a # a c a # a b r a r a c a # a b F L L is the Burrows Wheeler Transform
Burrows-Wheeler transform Claim: Every column contains all chars. F L a b r a c a # # a b r a c a a # a b r a c b r a c a # a a b r a c a # r a c a # a b a c a # a b r a c a # a b r b r a c a # a c a # a b r a c a # a b r a a # a b r a c # a b r a c a r a c a # a b You can obtain L from F by sorting
Burrows-Wheeler transform F L # a b r a c a a # a b r a c a b r a c a # a c a # a b r b r a c a # a c a # a b r a r a c a # a b The “a’s” are in the same order in L and in F, Similarly for every other char.
Burrows-Wheeler transform The inverse can be understood this way. Take the final table in the BWT algorithm, and erase all but the last column. Given only this information, you can easily reconstruct the first column. The last column tells you all the characters in the text, so just sort these characters to get the first column. Then, the first and last columns together give you all pairs of successive characters in the document, where pairs are taken cyclically so that the last and first character form a pair. Sorting the list of pairs gives the first and second columns. Continuing in this manner, you can reconstruct the entire list. Then, the row with the "end of file" character at the end is the original text.
Burrows-Wheeler transform F L # a b r a c a a # a b r a c a b r a c a # a c a # a b r b r a c a # a c a # a b r a r a c a # a b The “a’s” are in the same order in L and in F, Similarly for every other char.
From L you can reconstruct the string F L # a a c a # a r b a c a r b What is the first char of S ?
From L you can reconstruct the string F L # a a c a # a r b a c a r b a What is the first char of S ?
From L you can reconstruct the string F L # a a c a # a r b a c a r b ab
From L you can reconstruct the string F L # a a c a # a r b a c a r b abr
Compression? To understand why this creates more-easily-compressible data, let's consider transforming a long English text frequently containing the word "the". Sorting the rotations of this text will often group rotations starting with "he " together, and the last character of that rotation (which is also the character before the "he ") will usually be "t", so the result of the transform would contain a number of "t" characters along with the perhaps less-common exceptions (such as if it contains "Brahe ") mixed in. So it can be seen that the success of this transform depends upon one value having a high probability of occurring before a sequence, so that in general it needs fairly long samples (a few kilobytes at least) of appropriate data (such as text).
Compression? F L a b r a c a # # a b r a c a a # a b r a c b r a c a # a a b r a c a # r a c a # a b a c a # a b r a c a # a b r b r a c a # a c a # a b r a c a # a b r a a # a b r a c # a b r a c a r a c a # a b Characters with the same (right) context appear together
Compression? Sorting is equivalent to computing the suffix array. F L a b r a c a # # a b r a c a a # a b r a c b r a c a # a a b r a c a # r a c a # a b a c a # a b r a c a # a b r b r a c a # a c a # a b r a c a # a b r a a # a b r a c # a b r a c a r a c a # a b Not too difficult to decode in linear time. Not obvious, but one can also encode in linear time !
Encoding and decoding? Sorting is equivalent to computing the suffix array. F L a b r a c a # # a b r a c a a # a b r a c b r a c a # a a b r a c a # r a c a # a b a c a # a b r a c a # a b r b r a c a # a c a # a b r a c a # a b r a a # a b r a c # a b r a c a r a c a # a b Not too difficult to decode in linear time. Not obvious, but one can also encode in linear time !
Suffix arrays and suffix trees? The problem of suffix sorting is linear-time equivalent to computation of suffix trees. Can be done in time O(n2) by straightforward methods, but also in O(n) time by several more advanced algorithms. [Adapted from T.Kasai]
Some compression programs zip A format. Permits a number of compression methods, currently just Deflate is widely supported. Initial based on PKZIP (a tool), which used Lempel-Ziv-Welch algorithm. Deflate is a lossless data compression algorithm that uses a combination of the LZ77 algorithm and Huffman coding. It was originally defined by Phil Katz for version 2 of his PKZIP archiving tool. gz A format supported by gzip. Also based on Deflate algorithm. bzip2 An algorithm. Based on Burrows-Wheeler transform, uses also Huffman encoding. Supported by bzip2 (application) , also by 7-Zip etc. Z A format, initially supported by compress program. Based on LZW. [Adapted from www.wikipedia.org]
Some compression programs z The old Huffman encoding based format, supported by pack. 7z A format, initially supported by 7-Zip program. Supports different methods - LZMA (a Lempel-Ziv variation) , deflate,bzip2 and PPMD. PPMD (PPMZ) This seems to be a rather different method based on “context modelling”... rar Proprietary format, supported primarily by WinRAR. [Adapted from www.wikipedia.org]
Some comparisons - text encoding [Adapted from D.MacKay]
Some comparisons - random file File contains a random sequence of bits with “0” chosen with probability 0.01 and “1” with probability 0.99. [Adapted from D.MacKay]