Download
1 / 15
150 likes | 389 Vues
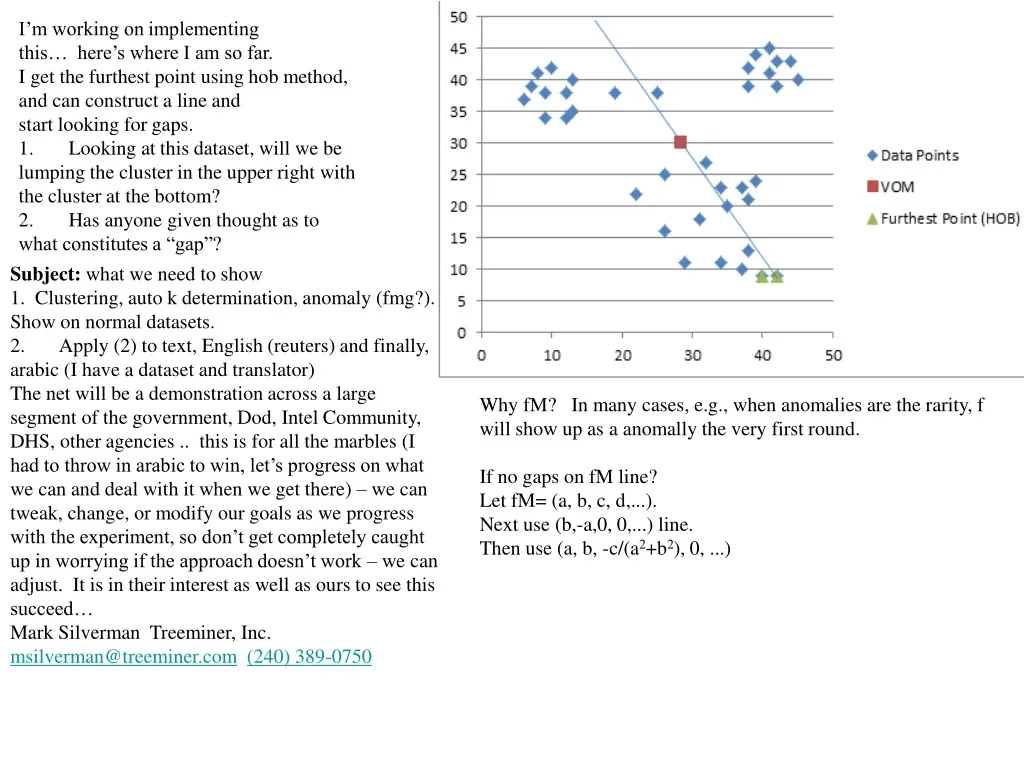
I’m working on implementing this… here’s where I am so far. I get the furthest point using hob method, and can construct a line and start looking for gaps. 1. Looking at this dataset, will we be lumping the cluster in the upper right with the cluster at the bottom?

E N D
I’m working on implementing this… here’s where I am so far. I get the furthest point using hob method, and can construct a line and start looking for gaps. 1. Looking at this dataset, will we be lumping the cluster in the upper right with the cluster at the bottom? 2. Has anyone given thought as to what constitutes a “gap”? Subject: what we need to show 1. Clustering, auto k determination, anomaly (fmg?). Show on normal datasets. 2. Apply (2) to text, English (reuters) and finally, arabic (I have a dataset and translator) The net will be a demonstration across a large segment of the government, Dod, Intel Community, DHS, other agencies .. this is for all the marbles (I had to throw in arabic to win, let’s progress on what we can and deal with it when we get there) – we can tweak, change, or modify our goals as we progress with the experiment, so don’t get completely caught up in worrying if the approach doesn’t work – we can adjust. It is in their interest as well as ours to see this succeed… Mark Silverman Treeminer, Inc. msilverman@treeminer.com(240) 389-0750 Why fM? In many cases, e.g., when anomalies are the rarity, f will show up as a anomally the very first round. If no gaps on fM line? Let fM= (a, b, c, d,...). Next use (b,-a,0, 0,...) line. Then use (a, b, -c/(a2+b2), 0, ...)
F=p1 and xoFM, T=23. Illustration of the first round of finding gaps p4' 1 0 0 1 0 0 0 0 0 0 1 0 1 0 0 p4' 1 0 0 1 0 0 0 0 0 0 1 0 1 0 0 p4' 1 0 0 1 0 0 0 0 0 0 1 0 1 0 0 p4' 1 0 0 1 0 0 0 0 0 0 1 0 1 0 0 p5' 1 1 1 0 0 1 0 0 0 0 0 0 0 0 1 p5' 1 1 1 0 0 1 0 0 0 0 0 0 0 0 1 p5' 1 1 1 0 0 1 0 0 0 0 0 0 0 0 1 p6' 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 p6' 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 p6' 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 p6' 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 p5' 1 1 1 0 0 1 0 0 0 0 0 0 0 0 1 p5' 1 1 1 0 0 1 0 0 0 0 0 0 0 0 1 p4' 1 0 0 1 0 0 0 0 0 0 1 0 1 0 0 p4' 1 0 0 1 0 0 0 0 0 0 1 0 1 0 0 p4' 1 0 0 1 0 0 0 0 0 0 1 0 1 0 0 p6' 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 p4' 1 0 0 1 0 0 0 0 0 0 1 0 1 0 0 p6' 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 p5' 1 1 1 0 0 1 0 0 0 0 0 0 0 0 1 p6' 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 p5' 1 1 1 0 0 1 0 0 0 0 0 0 0 0 1 p6' 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 p5' 1 1 1 0 0 1 0 0 0 0 0 0 0 0 1 p4 0 1 1 0 1 1 1 1 1 1 0 1 0 1 1 p4 0 1 1 0 1 1 1 1 1 1 0 1 0 1 1 p4 0 1 1 0 1 1 1 1 1 1 0 1 0 1 1 p4 0 1 1 0 1 1 1 1 1 1 0 1 0 1 1 p3' 0 0 1 1 1 1 1 1 0 1 0 0 0 0 1 p4 0 1 1 0 1 1 1 1 1 1 0 1 0 1 1 p4 0 1 1 0 1 1 1 1 1 1 0 1 0 1 1 p4 0 1 1 0 1 1 1 1 1 1 0 1 0 1 1 p4 0 1 1 0 1 1 1 1 1 1 0 1 0 1 1 p5 0 0 0 1 1 0 1 1 1 1 1 1 1 1 0 p5 0 0 0 1 1 0 1 1 1 1 1 1 1 1 0 p5 0 0 0 1 1 0 1 1 1 1 1 1 1 1 0 p5 0 0 0 1 1 0 1 1 1 1 1 1 1 1 0 p5 0 0 0 1 1 0 1 1 1 1 1 1 1 1 0 p5 0 0 0 1 1 0 1 1 1 1 1 1 1 1 0 p5 0 0 0 1 1 0 1 1 1 1 1 1 1 1 0 p5 0 0 0 1 1 0 1 1 1 1 1 1 1 1 0 p3' 0 0 1 1 1 1 1 1 0 1 0 0 0 0 1 p3 1 1 0 0 0 0 0 0 1 0 1 1 1 1 0 p3 1 1 0 0 0 0 0 0 1 0 1 1 1 1 0 p3' 0 0 1 1 1 1 1 1 0 1 0 0 0 0 1 p3' 0 0 1 1 1 1 1 1 0 1 0 0 0 0 1 p3 1 1 0 0 0 0 0 0 1 0 1 1 1 1 0 p3 1 1 0 0 0 0 0 0 1 0 1 1 1 1 0 p3' 0 0 1 1 1 1 1 1 0 1 0 0 0 0 1 p3' 0 0 1 1 1 1 1 1 0 1 0 0 0 0 1 p6 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 p6 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 p6 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 p6 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 p6 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 p6 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 p6 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 p6 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 p3 1 1 0 0 0 0 0 0 1 0 1 1 1 1 0 p3 1 1 0 0 0 0 0 0 1 0 1 1 1 1 0 p3' 0 0 1 1 1 1 1 1 0 1 0 0 0 0 1 p3' 0 0 1 1 1 1 1 1 0 1 0 0 0 0 1 p3 1 1 0 0 0 0 0 0 1 0 1 1 1 1 0 p3 1 1 0 0 0 0 0 0 1 0 1 1 1 1 0 pTree gap finderusing PTreeSet(xofM) xofM 11 27 23 34 53 80 118 114 125 114 110 121 109 125 83 p6 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 p5 0 0 0 1 1 0 1 1 1 1 1 1 1 1 0 p4 0 1 1 0 1 1 1 1 1 1 0 1 0 1 1 p3 1 1 0 0 0 0 0 0 1 0 1 1 1 1 0 p2 0 0 1 0 1 0 1 0 1 0 1 0 1 1 0 p1 1 1 1 1 0 0 1 1 0 1 1 0 0 0 1 p0 1 1 1 0 1 0 0 0 1 0 0 1 1 1 1 p6' 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 p5' 1 1 1 0 0 1 0 0 0 0 0 0 0 0 1 p4' 1 0 0 1 0 0 0 0 0 0 1 0 1 0 0 p3' 0 0 1 1 1 1 1 1 0 1 0 0 0 0 1 p2' 1 1 0 1 0 1 0 1 0 1 0 1 0 0 1 p1' 0 0 0 0 1 1 0 0 1 0 0 1 1 1 0 p0' 0 0 0 1 0 1 1 1 0 1 1 0 0 0 0 X x1 x2 p1 1 1 p2 3 1 p3 2 2 p4 3 3 p5 6 2 p6 9 3 p7 15 1 p8 14 2 p9 15 3 pa 13 4 pb 10 9 pc 11 10 pd 9 11 pe 11 11 pf 7 8 f= For FAUST SMM (Oblique), do a similar thing on the MrMv line. Record the number of r and v errors if RtEndPt is used to split. Take RtEndPt where sum min Parallelizes easily. Useful in pTree sorting? OR between gap 2 and 3 for cluster C2={p5} width=23 =8 gap: [010 1000, 010 1111] =[40,48) width=23=8 gap: [000 0000, 000 0111]=[0,8) width=23 =8 gap: [011 1000, 011 1111] =[56,64) width = 24 =16 gap: [100 0000, 100 1111]= [64,80) width= 24 =16 gap: [101 1000, 110 0111]=[88,104) OR between gap 1 & 2 for cluster C1={p1,p3,p2,p4} between 3,4 cluster C3={p6,pf} Or for cluster C4={p7,p8,p9,pa,pb,pc,pd,pe}
1. MapReduce FAUST Current_Relevancy_Score =9Killer_Idea_Score=2Nothing comes to minds as to what we would do here. MapReduce.Hadoop is a key-value approach to organizing complex BigData. In FAUST PREDICT/CLASSIFY we start with a Training TABLE and in FAUST CLUSTER/ANOMALIZER we start with a vector space. Mark suggests (my understanding), capturing pTreeBases as Hadoop/MapReduce key-value bases? I suggested to Arjun developing XML to capture Hadoop datasets as pTreeBases. The former is probably wiser. A wish list of great things that might result would be a good start. 2. pTree Text Mining: Current_Relevancy_Score =10Killer_Idea_Score=9I I think Oblique FAUST is the way to do this. Also there is the very new idea of capturing the reading sequence, not just the term-frequency matrix (lossless capture) of a corpus. 3. FAUST CLUSTER/ANOMALASER: Current_Relevancy_Score =9Killer_Idea_Score=9No No one has taken up the proof that this is a break through method. The applications are unlimited! 4. Secure pTreeBases: Current_Relevancy_Score =9Killer_Idea_Score=10 This seems straight forward and a certainty (to be a killer advance)! It would involve becoming the world expert on what data security really means and how it has been done by others and then comparing our approach to theirs. Truly a complete career is waiting for someone here! 5. FAUST PREDICTOR/CLASSIFIER: Current_Relevancy_Score =9Killer_Idea_Score=10No one done a complete analysis of this is a break through method. The applications are unlimited here too! 6. pTree Algorithmic Tools: Current_Relevancy_Score =10Killer_Idea_Score=10This is Md’s work. Expanding the algorithmic tool set to include quadratic tools and even higher degree tools is very powerful. It helps us all! 7. pTree Alternative Algorithm Impl: Current_Relevancy_Score =9Killer_Idea_Score=8This is Bryan’s work. Implementing pTree algorithms in hardware/firmware (e.g., FPGAs) - orders of magnitude performance improvement? 8. pTree O/S Infrastructure: Current_Relevancy_Score =10Killer_Idea_Score=10This is Matt’s work. I don’t yet know the details, but Matt, under the direction of Dr. Wettstein, is finishing up his thesis on this topic – such changes as very large page sizes, cache sizes, prefetching,… I give it a 10/10 because I know the people – they do double digit work always! From:Arjun.Roy@my.ndsu.edu] Sent: Thurs, Aug 09 Dear Dr. Perrizo, Do you think a map reduce class of FAUST algorithms could be built into a thesis? If the ultimate aim is to process big data, modification of existing P-tree based FAUST algorithms on Hadoop framework could be something to look on? I am myself not sure how far can I go but if you approve, then I can work on it. From: Mark to:Arjun Aug 9 From industry perspective, hadoop is king (at least at this point in time). I believe vertical data organization maps really well with a map/reduce approach – these are complimentary as hadoop is organized more for unstructured data, so these topics are not mutually exclusive. So from industry side I’d vote hadoop… from Treeminer side text (although we are very interested in both) From:msilverman@treeminer.comSent: Friday, Aug 10I’m working thru a list of what we need to get done – it will include implementing anomaly detection which is now on my list for some time. I tried to establish a number of things such that even if we had some difficulties with some parts we could show others (w/o digging us too deep). Once I get this I’ll get a call going. I have another programming resource down here who’s been working with me on our production code who will also be picking up some of the work to get this across the finish line, and a have also someone who was a director at our customer previously assisting us in packaging it all up so the customer will perceive value received… I think Dale sounded happy yesterday.
pTree Text Mining <--dfP0 Vocab Terms df <--dfP3 lev2, pred=pure1 on tfP1 -stide 1 1 0 0 2 hdfP 0 0 0 0 0 df count t=a t=again t=all 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 lev-2 (len=VocabLen) 0 3 1 1 1 0 0 0 1 1 1 0 8 8 8 0 2 1 0 1 1 0 0 0 1 1 1 0 0 3 0 0. . . 0 . . . 0 . . . 2 . . . 3 . . . . . . . . . ... tf 0 . . . 0 . . . . . . . . . ... tfP1 3 . . . ... tfP0 0 0 0 0 0 d=1 d=2 d=3 t=all t=all t=all ... doc=1 d=2 d=3 term=a t=a t=a d=1 d=2 d=3 t=again t=again t=again lev1tfPk eg pred tfP0: mod(sum(mdl-stride),2)=1 0 0 0 0 0 t=a t=again t=all 0 0 0 0 0 tePt=again tePt=all tePt=a t=all d=1 t=all d=2 t=all d=3 t=again t=again t=again d=1 d=2 d=3 t=a d=1 t=a d=2 t=a d=3 lev1 (len=DocCt*VocabLen) 1 1 1 1 1 1 1 Math book mask 0 0 1 1 0 0 0 1 0 0 0 0 0 0 0 0 1 0 1 0 0 . . . . . . 5 6 d=1 commas d=1 Preface d=1 References t=a d=2 t=a d=3 t=a d=1 t=again d=1 documnet ... tf0 tf ... tf1 ... tf2 te 2 0 0 0 0 0 0 0 0 0 JSE 0 0 1 0 . . . HHS LMM 0 0 0 0 0 0 0 . . . 0 0 0 0 0 0 0 . . . 1 a 1 1 always. apple ptf: positional term frequency The frequency of each term in each position across all documents (Is this any good?). 1 an again April 1 1 and all 3 2 1 are 7 1 2 3 4 lev0 corpusP (len=MaxDocLen*DocCt*VocabLen) Libry Congress masks (document categories move us up document semantic hierarchy Reading position masks (pos categories) move us up position semantic hierarchy (and allows puncutation etc., placement.) 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 . . . 0 0 0 0 0 0 0 . . . 0 0 0 0 0 0 0 . . . Corpus pTreeSet data Cube layout: Position
T S DT human .22 -.11 3.34 interface .2 -.07 2.54 computer .24 .04 user .40 .06 system .64 -.17 response .27 .11 time .27 .11 EPS .30 -.14 survey .21 .27 trees .01 .49 graph .04 .62 minors .03 .45 X tm\doc c1 c2 c3 c4 c5 m1 m2 m3 m4 human 1 0 0 1 0 0 0 0 0 interface 1 0 1 0 0 0 0 0 0 computer 1 1 0 0 0 0 0 0 0 user 0 1 1 0 1 0 0 0 0 system 0 1 1 2 0 0 0 0 0 response 0 1 0 0 1 0 0 0 0 time 0 1 0 0 1 0 0 0 0 EPS 0 0 1 1 0 0 0 0 0 survey 0 1 0 0 0 0 0 0 1 trees 0 0 0 0 0 1 1 1 0 graph 0 0 0 0 0 0 1 1 1 minors 0 0 0 0 0 0 0 1 1 c1 c2 c3 c4 c5 m1 m2 m3 m4 .02 -.06 .11 -.95 .05 -.08 .18 -.01 -.06 .61 .17 -.05 -.03 -.21 -.26 -.43 .05 .24 X^ .02 -.06 .11 -.95 .05 -.08 .18 -.01 -.06 .61 .17 -.05 -.03 -.21 -.26 -.43 .05 .24 .46 =.03 .21 .04 .38 .72 -.24 .01 .02 .54 -.23 .57 .27 -.21 -.37 .26 -.02 -.08 .28 .11 -.51 .15 .33 .03 .67 -.06 -.26 .00 .19 .10 .02 .39 -.30 -.34 .45 -.62 .01 .44 .19 .02 .35 -.21 -.15 -.76 .02 .02 .62 .25 .01 .15 .00 .25 .45 .52 .08 .53 .08 -.03 -.60 .36 -.04 -.07 -.45 c1 Human machine interface for Lab ABC computer apps c2 A survey of user opinion of comp system response time c3 The EPS user interface management system c4 System and human system engineering testing of EPS c5 Relation of user-perceived response time to error measmnt m1 The generation of random, binary, unordered trees m2 The intersection graph of paths in trees m3 Graph minors IV: Widths of trees and well-quasi-ordering m4 Graph minors: A survey X = T0S0D0T T0, D0 column-orthonormal. X^ keeps only 1st 2 singular values. Corresp T,D columns give term and doc coordinates in 2D. X ~ X^ = TSDT T0 .22 -.11 .29 -.41 -.11 -.34 .52 -.06 -.41 .20 -.07 .14 -.55 .28 .50 -.07 -.01 -.11 .24 .04 -.16 -.59 -.11 -.25 -.30 .06 .49 .40 .06 -.34 .10 .33 .38 .00 .00 .01 .64 -.17 .36 .33 -.16 -.21 -.17 .03 .27 .27 .11 -.43 .07 .08 -.17 .28 -.02 -.05 .27 .11 -.43 .07 .08 -.17 .28 -.02 -.05 .30 -.14 .33 .19 .11 .27 .03 -.02 -.17 .21 .27 -.18 -.03 -.54 .08 -.47 -.04 -.58 .01 .49 .23 .03 .59 -.39 -.29 .25 -.23 .04 .62 .22 .00 -.07 .11 .16 -.68 .23 .03 .45 .14 -.01 -.30 .28 .34 .68 .18 S0 3.34 2.54 2.35 1.64 1.50 1.31 0.85 0.56 0.36 D0 .02 -.06 .11 -.95 .05 -.08 .18 -.01 -.06 .61 .17 -.05 -.03 -.21 -.26 -.43 .05 .24 .46 =.03 .21 .04 .38 .72 -.24 .01 .02 .54 -.23 .57 .27 -.21 -.37 .26 -.02 -.08 .28 .11 -.51 .15 .33 .03 .67 -.06 -.26 .00 .19 .10 .02 .39 -.30 -.34 .45 -.62 .01 .44 .19 .02 .35 -.21 -.15 -.76 .02 .02 .62 .25 .01 .15 .00 .25 .45 .52 .08 .53 .08 -.03 -.60 .36 -.04 -.07 -.45
d(doc,q) human interface computer user system response time 1.00 (c1-q)^2 0 1 0 0 0 0 0 2.45 (c2-q)^2 1 0 0 1 1 1 1 2.45 (c3-q)^2 1 1 1 1 1 0 0 2.45 (c4-q)^2 0 0 1 0 4 0 0 2.24 (c5-q)^2 1 0 1 1 0 1 1 1.73 (m1-q)^2 1 0 1 0 0 0 0 2.00 (m2-q)^2 1 0 1 0 0 0 0 2.24 (m3-q)^2 1 0 1 0 0 0 0 2.24 (m4-q)^2 1 0 1 0 0 0 0 This tells us c1 is closest to q in the full space, but that the other c documents are no closer than the m documents. q is probably classified c (one voter in the 1.5 nbhd) but it's not clear. This shows need for SVD or Oblique FAUST! EPS survey trees graph minors 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 1 1 0 0 0 1 1 1 0 1 0 1 1 inter comp X doc\term human face uter user system response time EPS c1 1 1 1 0 0 0 0 0 c2 0 0 1 1 1 1 1 0 c3 0 1 0 1 1 0 0 1 c4 1 0 0 0 2 0 0 1 c5 0 0 0 1 0 1 1 0 m1 0 0 0 0 0 0 0 0 m2 0 0 0 0 0 0 0 0 m3 0 0 0 0 0 0 0 0 m4 0 0 0 0 0 0 0 0 mc 0.4 0.4 0.4 0.6 0.8 0.4 0.4 0.4 mm 0 0 0 0 0 0 0 0 q 1 0 1 0 0 0 0 0 D 0.40 0.40 0.40 0.60 0.80 0.40 0.40 0.40 d 0.23 0.30 0.42 1.09 -16.00 -0.47 -0.32 -0.24 (mc+mm)/2 0.09 0.12 0.17 0.65 -12.80 -0.19 -0.13 -0.10 mc+mm/2*d 0.02 0.04 0.07 0.71 204.80 0.09 0.04 0.02 a 204.92 q * d 0.23 0.00 0.42 0.00 0.00 0.00 0.00 0.00 q dot d 0.65 Since .65 is ar less than a =~ 205, q is clearly in the c class survey trees graph minors 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 1 0 0 1 1 1 1 0 1 1 0.2 0 0 0 0.25 0.75 0.75 0.5 0 0 0 0 -0.05 -0.75 -0.75 -0.50 0.02 0.38 0.60 1.00 -0.00 -0.28 -0.45 -0.50 -0.00 -0.11 -0.27 -0.50 0.00 0.00 0.00 0.00
inter comp doc\termhuman face uter user system respons time EPS c1 0.16 0.14 0.15 0.26 0.45 0.16 0.16 0.22 c2 0.40 0.37 0.51 0.84 1.23 0.58 0.58 0.55 c3 0.38 0.33 0.36 0.61 1.05 0.38 0.38 0.51 c4 0.47 0.4 0.41 0.70 1.27 0.42 0.42 0.63 c5 0.18 0.16 0.24 0.39 0.56 0.28 0.28 0.24 m1 -0.05 -0.03 0.02 0.03 -0.07 0.06 0.06 -0.07 m2 -0.12 -0.07 0.06 0.08 -0.15 0.13 0.13 -0.14 m3 -0.16 -0.10 0.09 0.12 -0.21 0.19 0.19 -0.20 m4 -0.09 -0.04 0.12 0.19 -0.05 0.22 0.22 -0.11 c mean mc 0.32 0.28 0.33 0.56 0.91 0.36 0.36 0.43 m mean mm -0.11 -0.06 0.07 0.11 -0.12 0.15 0.15 -0.13 q^ = TSDq' 0.16 0.14 0.15 0.26 0.45 0.16 0.16 0.22 d(doc,q^) 0.02 (c1-q^)^2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 1.47 (c2-q^)^2 0.06 0.05 0.13 0.34 0.60 0.17 0.17 0.11 0.90 (c3-q^)^2 0.05 0.03 0.04 0.12 0.36 0.05 0.05 0.08 1.23 (c4-q^)^2 0.09 0.07 0.07 0.20 0.67 0.07 0.07 0.17 0.50 (c5-q^)^2 0.00 0.00 0.01 0.02 0.01 0.01 0.01 0.00 0.92 (m1-q^)^2 0.05 0.03 0.02 0.05 0.27 0.01 0.01 0.09 1.40 (m2-q^)^2 0.08 0.05 0.01 0.03 0.36 0.00 0.00 0.13 1.82 (m3-q^)^2 0.10 0.06 0.00 0.02 0.44 0.00 0.00 0.18 1.55 (m4-q^)^2 0.06 0.03 0.00 0.00 0.25 0.00 0.00 0.11 Using knn this SVD transformed picture puts q cleary in the c class: dis=.25 nbrs {c1 } dis=.5 nbrs {c1,c5 } dis=.9 nbrs {c1,c3,c5 } dis=1 nbrs {c1,c3,c5, m1 } dis=1.25 nbrs {c1,c3,c4,c5, m1 } dis=1.5 nbrs {c1,c2,c3,c4,c5, m1,m2} Un-SVD transformed, it's not conclusive (i.e., using X instead of X^). D = mcmm0.42 0.34 0.26 0.46 1.03 0.21 0.21 0.56 -0.05 d = D/|D| 0.25 0.27 0.29 0.71 5.69 -0.25 -0.20 -0.44 0.03 (mc+mm)/2 0.11 0.09 0.08 0.33 5.87 -0.05 -0.04 -0.25 -0.00 mc+mm/2 dot d 0.03 0.03 0.02 0.23 33.36 0.01 0.01 0.11 -0.00 a 33.00 q * d 0.04 0.04 0.04 0.18 2.58 -0.04 -0.03 -0.10 0.00 q dot d 2.61 ( 2.61 << a so q is classified as c. And, we note that O'FAUST is more conclusive with X than it is with X^. ) survey trees graph minors 0.10 -0.06 -0.06 -0.04 0.53 0.23 0.34 0.25 0.23 -0.14 -0.15 -0.10 0.21 -0.27 -0.30 -0.21 0.27 0.14 0.20 0.15 0.14 0.24 0.31 0.22 0.31 0.55 0.69 0.50 0.44 0.77 0.98 0.71 0.42 0.66 0.85 0.62 0.27 -0.02 0.01 0.01 0.33 0.56 0.71 0.51 0.10 -0.07 -0.07 -0.05 0.03 0.32 0.58 1.00 -0.00 -0.19 -0.41 -0.50 -0.00 -0.06 -0.24 -0.50 0.01 0.04 0.05 0.03 0.03 0.04 0.07 0.04 0.00 0.09 0.14 0.07 0.04 0.38 0.57 0.30 0.12 0.70 1.10 0.58 0.10 0.53 0.84 0.45
I have put together a pBase of 75 Mother Goose Rhymes or Stories. Created a pBase of the 15 documents with 30 words (Universal Document Length, UDL) using as vocabulary, all white-space separated strings. Little Miss Muffet Lev1 (term freq/exist) Lev-0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20... pos 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 . . . 182 te tf tf1 tf0 VOCAB Little Miss Muffet sat on a tuffet eating 1 2 1 0 a 0 0 0 0 0 1 0 0 0 0 0 0 again. 0 0 0 0 0 0 0 0 0 0 0 0 all 0 0 0 0 0 0 0 0 0 0 0 0 always 0 0 0 0 0 0 0 0 0 0 0 0 an 0 0 0 0 0 0 0 0 1 3 1 1 and 0 0 0 0 0 0 0 0 0 0 0 0 apple 0 0 0 0 0 0 0 0 0 0 0 0 April 0 0 0 0 0 0 0 0 0 0 0 0 are 0 0 0 0 0 0 0 0 0 0 0 0 around 0 0 0 0 0 0 0 0 0 0 0 0 ashes, 0 0 0 0 0 0 0 0 0 0 0 0 away 0 0 0 0 0 0 0 0 0 0 0 0 away 0 0 0 0 0 0 0 0 1 1 0 1 away. 0 0 0 0 0 0 0 0 0 0 0 0 baby 0 0 0 0 0 0 0 0 0 0 0 0 baby. 0 0 0 0 0 0 0 0 0 0 0 0 bark! 0 0 0 0 0 0 0 0 0 0 0 0 beans 0 0 0 0 0 0 0 0 0 0 0 0 beat 0 0 0 0 0 0 0 0 0 0 0 0 bed, 0 0 0 0 0 0 0 0 0 0 0 0 Beggars 0 0 0 0 0 0 0 0 0 0 0 0 begins. 0 0 0 0 0 0 0 0 1 1 0 1 beside 0 0 0 0 0 0 0 0 0 0 0 0 between 0 0 0 0 0 0 0 0 . . . 0 0 0 0 your 0 0 0 0 0 0 0 0 of curds and whey. There came a big spider and sat down... 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Level-2 pTrees (document frequency) df3 df2 df1 df0 df VOCAB te04 te05 te08 te09 te27 te29 te34 1 0 0 0 8 a 1 1 0 1 0 0 0 0 0 0 1 1 again. 0 1 0 0 0 0 0 0 0 1 1 3 all 0 1 0 0 0 0 0 0 0 0 1 1 always 0 0 0 0 0 1 0 0 0 0 1 1 an 0 0 0 0 0 0 0 1 1 0 1 13 and 1 1 1 1 1 1 1 0 0 0 1 1 apple 0 0 0 0 0 0 0 0 0 0 1 1 April 0 0 0 0 0 0 0 0 0 0 1 1 are 0 0 0 0 0 0 0 0 0 0 1 1 around 0 0 0 0 0 0 0 0 0 0 1 1 ashes, 0 0 0 0 0 0 0 0 0 1 0 2 away 0 0 0 0 0 1 0 0 0 1 0 2 away 0 0 0 0 0 1 0 0 0 0 1 1 away. 1 0 0 0 0 0 0 0 0 0 1 1 baby 0 0 0 0 1 0 0 0 0 0 1 1 baby. 0 0 0 1 0 0 0 0 0 0 1 1 bark! 0 0 0 0 0 0 0 0 0 0 1 1 beans 0 0 0 0 0 0 1 0 0 0 1 1 beat 0 0 0 0 0 0 0 0 0 0 1 1 bed, 0 0 0 0 0 1 0 0 0 0 1 1 Beggars 0 0 0 0 0 0 0 0 0 0 1 1 begins. 0 0 0 0 0 0 0 0 0 0 1 1 beside 1 0 0 0 0 0 0 0 0 0 1 1 between 0 0 1 0 0 0 0 Humpty Dumpty Lev1 (term freq/exist) Lev-0 1 2 3 4 5 6 7 8... te tf tf1 tf0 05HDS Humpty Dumpty sat on a wall. Humpt yDumpty 1 2 1 0 a 0 0 0 0 1 0 0 0 1 1 0 1 again. 0 0 0 0 0 0 0 0 1 2 1 0 all 0 0 0 0 0 0 0 0 0 0 0 0 always 0 0 0 0 0 0 0 0 0 0 0 0 an 0 0 0 0 0 0 0 0 1 1 0 1 and 0 0 0 0 0 0 0 0 0 0 0 0 apple 0 0 0 0 0 0 0 0 0 0 0 0 April 0 0 0 0 0 0 0 0 0 0 0 0 are 0 0 0 0 0 0 0 0 0 0 0 0 around 0 0 0 0 0 0 0 0 0 0 0 0 ashes, 0 0 0 0 0 0 0 0 0 0 0 0 away 0 0 0 0 0 0 0 0 0 0 0 0 away 0 0 0 0 0 0 0 0 0 0 0 0 away. 0 0 0 0 0 0 0 0 0 0 0 0 baby 0 0 0 0 0 0 0 0 0 0 0 0 baby. 0 0 0 0 0 0 0 0 0 0 0 0 bark! 0 0 0 0 0 0 0 0 0 0 0 0 beans 0 0 0 0 0 0 0 0 0 0 0 0 beat 0 0 0 0 0 0 0 0 0 0 0 0 bed, 0 0 0 0 0 0 0 0 0 0 0 0 Beggars 0 0 0 0 0 0 0 0 0 0 0 0 begins. 0 0 0 0 0 0 0 0 0 0 0 0 beside 0 0 0 0 0 0 0 0 0 0 0 0 between 0 0 0 0 0 0 0 0 . . . 0 0 0 0 your 0 0 0 0 0 0 0 0 pos 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 . . . 182 Next we look at using only content words (reduces VocabSize=8 and CorpusSize=11).
te 2 2 4 5 5 7 7 4 5 8 9 7 9 6 3 4 1 3 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 1 0 1 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 1 1 tf1 2 2 4 5 5 7 7 4 5 8 9 7 9 6 3 4 1 3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 tf0 2 2 4 5 5 7 7 4 5 8 9 7 9 6 3 4 1 3 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 1 1 tf 2 2 4 5 5 7 7 4 5 8 9 7 9 6 3 4 1 3 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 2 0 1 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 1 0 2 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 2 0 1 0 0 0 0 0 0 0 0 0 0 0 1 1 In this slide section, the vocabulary is reduce to content words (8 of them). mdl=5, vocab={baby,cry,dad,eat,man,mother,pig,shower}, VocabLen=8 and there are 11 docs of the 15 (11 survivors of the content word reduction). First Content Word Mask, FCWM Level-1 (rolled vocab of level-0) d=73 1 0 0 0 0 d=71 1 0 0 0 0 d=54 1 0 0 0 0 d=53 1 0 0 0 0 d=46 1 0 0 0 0 d=29 1 0 0 0 0 d=27 1 0 0 0 0 d=09 1 0 0 0 0 d=08 1 0 0 0 0 d=05 1 0 0 0 0 d=04 1 0 0 0 0 doc=73 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 doc=71 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 doc=54 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 Level-1 (roll up position of level-0) doc=53 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 doc=46 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 doc=29 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 doc=27 0 1 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 doc=09 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 Level-2 (roll up document of level-1) df1 1 1 1 1 1 1 1 1 doc=08 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 df0 0 0 0 1 0 1 0 0 doc=05 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 VOCAB baby cry dad eat man mother pig shower df 2 2 2 3 2 3 2 2 doc=04 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Level-0 POSITION 1 2 3 4 5
df 2 2 2 3 2 3 2 2 df1 0 0 0 1 0 1 0 0 df0 0 0 0 1 0 1 0 0 term doc tf tf1 tf0 te baby 04LMM 0 0 0 0 05HDS 0 0 0 0 08JSC 0 0 0 0 09HBD 1 0 1 1 27CBC 1 0 1 1 29LFW 0 0 0 0 46TTP 0 0 0 0 53NAP 0 0 0 0 54BOF 0 0 0 0 71MWA 0 0 0 0 73SSW 0 0 0 0 cry 04LMM 0 0 0 0 05HDS 0 0 0 0 08JSC 0 0 0 0 09HBD 0 0 0 0 27CBC 2 1 0 1 29LFW 0 0 0 0 46TTP 1 0 1 1 53NAP 0 0 0 0 54BOF 0 0 0 0 71MWA 0 0 0 0 73SSW 0 0 0 0 dad 04LMM 0 0 0 0 05HDS 0 0 0 0 08JSC 0 0 0 0 09HBD 1 0 1 1 27CBC 0 0 0 0 29LFW 1 0 1 1 46TTP 0 0 0 0 53NAP 0 0 0 0 54BOF 0 0 0 0 71MWA 0 0 0 0 73SSW 0 0 0 0 eat 04LMM 1 0 1 1 05HDS 0 0 0 0 08JSC 2 1 0 1 09HBD 0 0 0 0 27CBC 0 0 0 0 29LFW 0 0 0 0 46TTP 1 0 1 1 53NAP 0 0 0 0 54BOF 0 0 0 0 71MWA 0 0 0 0 73SSW 0 0 0 0 man 04LMM 0 0 0 0 05HDS 1 0 1 1 08JSC 0 0 0 0 09HBD 0 0 0 0 27CBC 0 0 0 0 29LFW 0 0 0 0 46TTP 0 0 0 0 53NAP 1 0 1 1 54BOF 0 0 0 0 71MWA 0 0 0 0 73SSW 0 0 0 0 mother04LMM 0 0 0 0 05HDS 0 0 0 0 08JSC 0 0 0 0 09HBD 1 0 1 1 27CBC 1 0 1 1 29LFW 1 0 1 1 46TTP 0 0 0 0 53NAP 0 0 0 0 54BOF 0 0 0 0 71MWA 0 0 0 0 73SSW 0 0 0 0 eat shower baby man 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 dad mother pig cry 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 pig 04LMM 0 0 0 0 05HDS 0 0 0 0 08JSC 0 0 0 0 09HBD 0 0 0 0 27CBC 0 0 0 0 29LFW 0 0 0 0 46TTP 2 1 0 1 53NAP 0 0 0 0 54BOF 1 0 1 1 71MWA 0 0 0 0 73SSW 0 0 0 0 shower04LMM 0 0 0 0 05HDS 0 0 0 0 08JSC 0 0 0 0 09HBD 0 0 0 0 27CBC 0 0 0 0 29LFW 0 0 0 0 46TTP 0 0 0 0 53NAP 0 0 0 0 54BOF 0 0 0 0 71MWA 1 0 1 1 73SSW 1 0 1 1 5 reading positions for doc=04LMM (Little Miss Muffet) baby cry dad eat man mother pig shower 04LMM 2 3 4 5 05HDS 7 8 9 10 08JSC 12 13 14 15 09HBD 17 18 19 20 27CBC 22 23 24 25 29LFW 27 28 29 30 46TTP 32 33 34 35 53NAP 37 38 39 40 54BOF 42 43 44 45 71MWA 47 48 49 50 73SSW 52 53 54 55 Level-2 (roll up doc) Level-1 (roll up pos) Level-0 (ordered by position, document, then vocab)
Masking FCW Taking a very simple task - that of clustering vocab by document frequency. Each cluster contains the words that are of relatively equal importance - assuming the more frequently the term occurs, the less important the term. df 2 2 2 3 2 3 2 2 In the original data, the clusters in decreasing order of importance are: {shower, pig, man, dad, cry, baby} baby cry dad eat man mother pig shower {mother, eat} df 1 1 2 2 1 2 2 In FCW filtered data the clusters in decreasing order of importance are: baby cry eat man mother pig shower {mother, cry, baby} {shower, pig, man, eat} baby 04LMM 05HDS 08JSC 09HBD 27CBC 29LFW 46TTP 53NAP 54BOF 71MWA 73SSW 0 0 0 1 0 0 0 0 0 0 0 cry 0 0 0 0 1 0 0 0 0 0 0 eat 0 0 0 0 0 0 0 0 0 0 0 man 0 0 0 0 1 0 0 0 0 0 0 One could argue that the latter is a better clustering. Crying, babies and mothers are strongly associated? Men, pigs, eating and needing a shower are strongly associated? The point of this is to demonstrate (suggest?) that there may be new information in the expanded view of the text corpus that we take (not just starting from the tf matrix but including the reading sequences as well. I'm sure others have considered an "abstract only" or "executive summary only" data mine, but the horizontal structuring does not yield that input readily - our pTree approach does (just by applying the "abstract" mask). In the general case, an additional weighting (other than the usual, inverse of df type weightings of term importance within the corpus) could include the (inverse of) position number of the 1st occurrence of the term (normalized). Or even the (inverse of) the weighted average of the position number (or relative position numbers, since documents are different lengths). mother 0 0 0 1 0 0 0 0 0 0 0 pig 0 0 0 0 1 0 0 0 0 0 0 df 1 1 2 2 1 2 2 df1 0 0 1 1 0 1 1 df0 1 1 1 0 1 0 0 shower 0 0 0 0 1 0 0 0 0 0 0 baby cry eat man mother pig shower
eat pig baby cry man mother shower te tf1 tf0 dad tf baby cry eat pig man mother dad shower baby 04LMM 05HDS 08JSC 09HBD 27CBC 29LFW 46TTP 53NAP 54BOF 71MWA 73SSW cry 04LMM 05HDS 08JSC 09HBD 27CBC 29LFW 46TTP 53NAP 54BOF 71MWA 73SSW dad 04LMM 05HDS 08JSC 09HBD 27CBC 29LFW 46TTP 53NAP 54BOF 71MWA 73SSW eat 04LMM 05HDS 08JSC 09HBD 27CBC 29LFW 46TTP 53NAP 54BOF 71MWA 73SSW man 04LMM 05HDS 08JSC 09HBD 27CBC 29LFW 46TTP 53NAP 54BOF 71MWA 73SSW mother04LMM 05HDS 08JSC 09HBD 27CBC 29LFW 46TTP 53NAP 54BOF 71MWA 73SSW pig 04LMM 05HDS 08JSC 09HBD 27CBC 29LFW 46TTP 53NAP 54BOF 71MWA 73SSW shower04LMM 05HDS 08JSC 09HBD 27CBC 29LFW 46TTP 53NAP 54BOF 71MWA 73SSW 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 1 0 1 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 2 0 1 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 1 0 2 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 2 0 1 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 1 0 0 0 0 04LMM 2 3 4 5 05HDS 7 8 9 10 08JSC 12 13 14 15 09HBD 17 18 19 20 27CBC 22 23 24 25 29LFW 27 28 29 30 46TTP 32 33 34 35 53NAP 37 38 39 40 54BOF 42 43 44 45 71MWA 47 48 49 50 73SSW 52 53 54 55 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 04LMM 05HDS 08JSC 09HBD 27CBC 29LFW 46TTP 53NAP 54BOF 71MWA 73SSW 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 1 0 1 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 1 1 df 2 2 2 3 2 3 2 2 df1 0 0 0 1 0 1 0 0 df0 0 0 0 1 0 1 0 0 baby cry dad eat man mother pig shower
APPENDIX: Latent semantic indexing (LSI) is indexing and retrieval that uses Singular value decomposition for patterns in terms and concepts in text. LSI is based on the principle that words that are used in the same contexts tend to have similar meanings. LSI feature: ability to extract conceptual content of a body of text by establishing associations between terms that occur in similar contexts.[1] LSI overcomes synonymy, polysemy which cause mismatches in info retrieval [3] and cause Boolean keyword queries to mess up. LSI performs autodoc categorization (assignment of docs to predefined categories based on similarity to conceptual content of the categories.[5] LSI uses example docs for conceptual basis categories - concepts are compared to the concepts contained in the example items, and a category (or categories) is assigned to the docs based on similarities between concepts they contain and the concepts contained in example docs. Mathematics of LSI (linear algebra techniques to learn the conceptual correlations in a collection of text). Construct a weighted term-document matrix, do Singular Value Decomposition on it. Use that to identify the concepts contained in the text. Term Document Matrix, A: Each (of m) terms represented by a row, each (of n) doc is rep'ed by a column, with each matrix cell, aij, initially representing number of times the associated term appears in the indicated document, tfij. This matrix is usually large and very sparse. SVD basically reduces the dimensionality of the matrix to a tractable size by finding the singular values. It involves matrix operations and may not be amenable to pTree operations (i.e. horizontal methods are highly developed and my be best. We should study it though to see if we can identify a pTree based breakthrough for creating the reduction that SVD achieves. Here is a good paper on the subject of LSI and SVD: http://www.cob.unt.edu/itds/faculty/evengelopoulos/dsci5910/LSA_Deerwester1990.pdf SVD: Let X be the t by d TermFrequency (tf) matrix. It can be decomposed as T0S0D0T where T and D have ortho-normal columns and S has only the singular values on its diagonal in descending order. Remove from T0,S0,D0, row-col of all but highest k singular values, giving T,S,D. X ~= X^ ≡ TSDT (X^ is the rank=k matrix closest to X). We have reduced the dimension from rank(X) to k and we note, X^X^T = TS2TT and X^TX^ = DS2DT There are three sorts of comparisons of interest: Comparing 1. terms (how similar are terms, i and j?) (comparing rows) 2. documents (how similar are documents i and j?) (comparing documents) 3. terms and documents (how associated are term i and doc j?) (examining individual cells) Comparing terms (how similar are terms, i and j?) (comparing rows) Dot product between two rows of X^ reflects their similarity (similar occurrence pattern across the documents). X^X^T is the square t x t symmetric matrix containing all these dot products. X^X^T = TS2TT This means the ij cell in X^X^T is the dot prod of i and j rows of TS (rows TS can be considered coords of terms). Comparing documents (how similar are documents, i and j?) (comparing columns) Dot product of two columns of X^ reflects their similarity (extent to which two documents have a similar profile of terms). X^TX^ is the square d x d symmetric matrix containing all these dot products. X^TX^ = DS2DT This means the ij cell in X^TX^ is the dot prod of i and j columns of DS (considered coords of documents). Comparing a term and a document (how associated are term i and document j?) (analyzing cell i,j of X^) Since X^ = TSDT cell ij is the dot product of the ith row of TS½ and the jth column of DS½
FAUST=Fast, Accurate Unsupervised and Supervised Teaching(Teachingbig data to reveal information) • FAUST CLUSTER-fmg (furthest-to-meangaps for finding round clusters):C=X (e.g., X≡{p1, ..., pf}= 15 pix dataset.) • While an incomplete cluster, C, remains find M ≡ Medoid(C) ( Mean or Vector_of_Medians or? ). • Pick fC furthest fromM from S≡SPTreeSet(D(x,M) .(e.g., HOBbit furthestf, take any from highest-order S-slice.) • If ct(C)/dis2(f,M)>DT (DensThresh), C is complete, else split C where P≡PTreeSet(cofM/|fM|) gap > GT (GapThresh) • End While. • Notes: a. Euclidean and HOBbit furthest. b. fM/|fM| and just fM in P. c. find gaps by sorrting P or O(logn) pTree method? Interlocking horseshoes with an outlier 1 2 p2 p5 p1 3 p4 p6 p9 4 p3 p8 p7 5 pf pb 6 pe pc 7 pd pa 8 1 2 3 4 5 6 7 8 9 a b c d e f C2={p5} complete (singleton = outlier). C3={p6,pf}, will split (details omitted), so {p6}, {pf} complete (outliers). That leaves C1={p1,p2,p3,p4} and C4={p7,p8,p9,pa,pb,pc,pd,pe} still incomplete. C1 is dense ( density(C1)= ~4/22=.5 > DT=.3 ?) , thus C1is complete. Applying the algorithm to C4: In both cases those probably are the best "round" clusters, so the accuracy seems high. The speed will be very high! {pa} outlier. C2 splits into {p9}, {pb,pc,pd} complete. 1 p1 p2 p7 2 p3 p5 p8 3 p4 p6 p9 4 pa 5 6 7 8 pf 9 pb a pc b pd pe c d e f 0 1 2 3 4 5 6 7 8 9 a b c d e f M0 8.3 4.2 M1 6.3 3.5 f1=p3, C1 doesn't split (complete). M f M4 X x1 x2 p1 1 1 p2 3 1 p3 2 2 p4 3 3 p5 6 2 p6 9 3 p7 15 1 p8 14 2 p9 15 3 pa 13 4 pb 10 9 pc 11 10 pd 9 11 pe 11 11 pf 7 8 D(x,M0) 2.2 3.9 6.3 5.4 3.2 1.4 0.8 2.3 4.9 7.3 3.8 3.3 3.3 1.8 1.5 C1 C2 C3 C4 M1 M0
Separate classR, classV using midpoints of means (mom) method: calc a vomV vomR d-line d v2 v1 std of these distances from origin along the d-line a FAUST Oblique PR = P(X dot d)<a D≡ mRmV= oblique vector. d=D/|D| View mR, mV as vectors (mR≡vector from origin to pt_mR), a = (mR+(mV-mR)/2)od = (mR+mV)/2o d(Very same formula works when D=mVmR, i.e., points to left) Training ≡ choosing "cut-hyper-plane" (CHP), which is always an (n-1)-dimensionl hyperplane (which cuts space in two). Classifying is one horizontal program (AND/OR) across pTrees to get a mask pTree for each entire class (bulk classification) Improve accuracy? e.g., by considering the dispersion within classes when placing the CHP. Use 1. the vector_of_median, vom, to represent each class, rather than mV, vomV ≡ ( median{v1|vV}, 2. project each class onto the d-line (e.g., the R-class below); then calculate the std (one horizontal formula per class; using Md's method); then use the std ratio to place CHP (No longer at the midpoint between mr [vomr] and mv [vomv] ) median{v2|vV}, ... ) dim 2 r r vv r mR r v v v v r r v mV v r v v r v dim 1




















