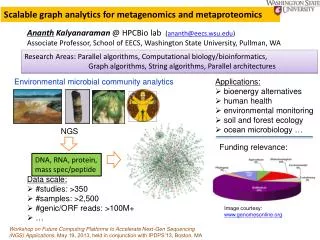
Download

1 / 31
310 likes | 504 Vues
Scalable Benchmarks and Kernels for Data Mining and Analytics. Vipin Kumar University of Minnesota kumar@cs.umn.edu www.cs.umn.edu/~kumar Joint work with Alok Choudhary and Gokhan Memik (Northwestern) and Michael Steinbach (University of Minnesota) Research funded by NSF.

E N D
Scalable Benchmarks and Kernels for Data Mining and Analytics Vipin Kumar University of Minnesota kumar@cs.umn.edu www.cs.umn.edu/~kumar Joint work with Alok Choudhary and Gokhan Memik (Northwestern) and Michael Steinbach (University of Minnesota) Research funded by NSF
Need for High Performance Data Mining • Today’s digital society has seen enormous data growth in both commercial and scientific databases • Data Mining is becoming a commonly used tool to extract information from large and complex datasets • Advances in computing capabilities and technological innovation needed to harvest the available wealth of data Homeland Security Biomedical Data Internet Geo-spatial data Computational Simulations Sensor Networks
NASA ESE questions: • How is the global Earth system changing? • What are the primary forcings? • How does Earth system respond to natural & human-induced changes? • What are the consequences of changes in the Earth system? • How well can we predict future changes? Data Mining for Climate Data • Global snapshots of values for a number of variables on land surfaces or water • High Resolution EOS Data: • EOS satellites provide high resolution measurements • Finer spatial grids • 1 km1 km grid produces 694,315,008 data points • Going from 0.5º 0.5º degree data to 1 km 1 km data results in a 2500-fold increase in the data size • More frequent measurements • Multiple instruments • High resolution data allows us to answer more detailed questions: • Detecting patterns such as trajectories, fronts, and movements of regions with uniform properties • Finding relationships between leaf area index (LAI) and topography of a river drainage basin • Finding relationships between fire frequency and elevation as well as topographic position • Leads to substantially high computational and memory requirements NASA DATA MINING REVEALS A NEW HISTORY OF NATURAL DISASTERS NASA is using satellite data to paint a detailed global picture of the interplay among natural disasters, human activities and the rise of carbon dioxide in the Earth's atmosphere during the past 20 years….http://www.nasa.gov/centers/ames/news/releases/2003/03_51AR.html Detection of Ecosystem Disturbances: This interactive module displays the locations on the earth surface where significant disturbance events have been detected. Disturbance Viewer
Data Mining for Cyber Security • Due to proliferation of Internet, more and more organizations are becoming vulnerable to sophisticated cyber attacks • Traditional Intrusion Detection Systems (IDS) have well-known limitations • Too many false alarms • Unable to detect sophisticated and novel attacks • Unable to detect insider abuse/ policy abuse • Data Mining is well suited to address these challenges MINDS – Minnesota Intrusion Detection System Large Scale Data Analysis is needed for • Correlation of suspicious events across network sites • Helps detect sophisticated attacks not identifiable by single site analyses • Analysis of long term data (months/years) • Uncover suspicious stealth activities (e.g. insiders leaking/modifying information) • Incorporated into Interrogator architecture at ARL Center for Intrusion Monitoring and Protection (CIMP) • Helps analyze data from multiple sensors at DoD sites around the country • Routinely detects Insider Abuse / Policy Violations / Worms / Scans
Data Mining for Biomedical Informatics • Recent technological advances are helping to generate large amounts of both medical and genomic data • High-throughput experiments/techniques • Gene and protein sequences • Gene-expression data • Biological networks and phylogenetic profiles • Electronic Medical Records • IBM-Mayo clinic partnership has created a DB of 5 million patients • NIH Roadmap • Data mining offers potential solution for analysis of large-scale data • Automated analysis of patients history for customized treatment • Design of drugs/chemicals • Prediction of the functions of anonymous genes Protein Interaction Network
Role of Benchmarks in Architecture Design • Benchmarks guide the development of new processor architectures in addition to measuring the relative performance of different systems • SPEC: General purpose architecture (“Advances in the microprocessor industry would not have been possible without the SPEC benchmarks” - David Patterson) • TPC: Database Systems • SPLASH: Parallel machine architectures • Mediabench: Media and Communication Processors • NetBench: Network/Embedded processors
11 SPECINT SPEC FP MediaBench TPC-H MineBench 10 9 8 7 6 Cluster Number 5 4 3 2 1 0 gs Q3 Q4 Q6 gcc hop art vpr snp Q17 gzip mcf apsi epic birch bzip2 eclat swim twolf lucas mesa cjpeg toast mgrid apriori vortex parser pegwit mpeg2 rsearch encode semphy svm-rfe equake scalparc kMeans genenet wupwise bayesian rawcaudio fuzzy Reference: [Pisharath J., Zambreno J., Ozisikyilmaz B., Choudhary A., 2006] Do We Need Benchmarks Specific to Data Mining? • Performance metrics of several benchmarks gathered from Vtune • Cache miss ratios, Bus usage, Page faults etc. • Benchmark applications were grouped using Kohenen clustering to spot trends:
Recently funded NSF project:Scalable Benchmarks, Software and Datafor Data Mining, Analytics and Scientific DiscoveriesPIs: A. Choudhary and Gokhan Memik (NW) , V. Kumar and M. Steinbach (UM) Goal: Establish a comprehensive benchmarking suite for data mining applications. • Motivate the development of new processor architectures and system design for data mining • Motivate the implementation of more sophisticated data mining algorithms that can work with the constraints imposed by current architecture designs • Improvement the productivity of scientists and engineers using data mining application in a wide variety of domains
Data Mining Tasks … Data Clustering Predictive Modeling Anomaly Detection Association Rules Milk
Key Data Mining Algorithms • Clustering • K-means, EM, SOM • Single link / Group Average hierarchical clustering • DBSCAN, SNN • Classification • Bayes • SVM • Decision trees, Rule based systems • Association Rule Mining • Apriori, FP-Growth • Anomaly Detection • Statistical methods • Distance-based • Clustering-based • Preprocessing • SVD, PCA
Major Data Mining Kernels • Counting • Given a set of data records, count types of different categories to build a contingency table • Count the occurrence of a set of items in a set of transactions • Pairwise computations • Given a set of data records, perform pairwise distane/similarity computations • Linear Algebra operations • SVD, PCA
General Characteristics of Data Mining Algorithms • Dense/Sparse data • Hash table / Hash tree • Linked Lists • Iterative nature • Data often too large to fit in main memory • Spatial locality is critical
Employed Yes Yes No No Education Worthy: 4 Not Worthy:3 Worthy: 4 Not Worthy:3 Worthy: 0 Not Worthy:3 Worthy: 0 Not Worthy:3 Graduate High School/ Undergrad Worthy: 2 Not Worthy:2 Worthy: 2 Not Worthy:4 Not Worthy Worthy 4 3 Employed = Yes Key Computation 0 3 Employed = No Constructing a Decision Tree Employed
Constructing a Decision Tree Employed = Yes Employed = No
Partitioning of data only global reduction per node is required large number of classification tree nodes gives high communication cost Constructing a Decision Tree in Parallel m categorical attributes n records
Partitioning of classification tree nodes natural concurrency load imbalance the amount of work associated with each node varies limited concurrency on the upper portion of the tree child nodes use the same data as used by parent node loss of locality high data movement cost 10,000 training records 7,000 records 3,000 records 2,000 5,000 2,000 1,000 Constructing a Decision Tree in Parallel
0.8 million examples 1.6 million examples hybrid hybrid Data partitioning Data partitioning Tree partitioning Tree partitioning Speedup Comparison of the Three Parallel Algorithms • Data set used in SLIQ paper (Ref: Mehta, Agrawal and Rissanen, 1996) • IBM SP2 with 128 processors • Dynamic load balancing inspired by parallel sparse Cholesky factorization and parallel tree search
Speedup of the Hybrid Algorithm with Different Size Data Sets
Processor P0 Processor P0 Processor P1 Processor P2 Storing the entire has table on one processor makes the algorithm unscalable Hash Table Access • Some efficient decision tree algorithms require random access to large data structures. • Example: SPRINT (Ref: Shafer, Agrawal, Mehta, 1996) Hash Table Processor P0 Left Right Processor P1 Processor P2
ScalParC (Ref: Joshi, Karypis, Kumar, 1998) • ScalParC is a scalable parallel decision tree construction algorithm • Scales to large number of processors • Scales to large training sets • ScalParC is memory efficient • The hash-table is distributed among the processors • ScalParC performs minimum amount of communication
Processor P0 Processor P1 Processor P2 This ScalParC Design is Inspired by.. • Communication Structure of Parallel Sparse Matrix-Vector Algorithms Processor P0 Processor P1 Processor P2 Hash Table Entries
Parallel Runtime (Ref: Joshi, Karypis, Kumar, 1998) 128 Processor Cray T3D
Computing Association Patterns 2. Find item combinations (itemsets) that occur frequently in data 1. Market-basket transactions 3. Generate association rules
A B A B 1 1 Naïve approach requires O(NM) comparisons A B 2 A C A C 1 2 A C 2 A D A D 1 1 A D 2 A E A E 0 1 A E 2 B C B C 1 1 Reduce the number of comparisons (NM) by using hash tables to store the candidate itemsets B C 3 B D B D 1 1 B D 4 A B E A B E 0 0 A B E 2 B C D B C D 1 1 B C D 2 A B D E A B D E 0 0 A B D E 1 A B C D E A B C D E 0 0 A B C D E 0 Counting Candidates • Frequent Itemsets are found by counting candidates • Simple way: • Search for each candidate in each transaction Transactions Candidates Count M N
DD (Agrawal & Shafer, 1996) IDD (Han, Karypis, Kumar, 2000) HD (Han, Karypis, Kumar, 2000) Parallel Association Rules: Scaleup Results(100K,0.25%)(Ref: Han, Karypis, and Kumar, 2000) Efficient implementation of collective communication Dynamic restructuring of computation
Analysis of Benchmark Algorithms • Explore the bottlenecks associated with the current general purpose sequential and parallel machines • Explore how different architectural features impact the performance of data mining algorithms
Preliminary Evaluation of Some Sample Data Sets • Example small (S), medium (M), and large (L) data set • Execution time for some algorithms in the MineBench suite. Reference: [Liu Y., Pisharath J., Liao W., Memik G., Choudhary A., Dubey P., 2004]
Designing Efficient Kernels for Data Mining • Understanding of the bottlenecks in executing DM algorithms on current architectures will help design new, more efficient algorithms • Focus will be on design frequently used kernels that dominates the execution time of most DM algorithms • Both sequential and parallel versions will be developed Frequency of Kernel Operations in Representative Applications Reference: [Pisharath J., Zambreno J., Ozisikyilmaz B., Choudhary A., 2006]
Conclusions • Data mining applications are becoming increasingly important • Current systems design approach not adequate for DM applications • MineBench – a new benchmark suite which encompasses many algorithms found in data mining • Initial findings: • Data mining applications are unique in terms of performance characteristics • There exists much room for optimization with regards to data mining workloads
Bibliography • Introduction to Data Mining, Pang-Ning Tan, Michael Steinbach, Vipin Kumar, Addison-Wesley April 2005 • Introduction to Parallel Computing, (Second Edition) by Ananth Grama, Anshul Gupta, George Karypis, and Vipin Kumar. Addison-Wesley, 2003 • Data Mining for Scientific and Engineering Applications, edited by R. Grossman, C. Kamath, W. P. Kegelmeyer, V. Kumar, and R. Namburu, Kluwer Academic Publishers, 2001 • J. Han, R. B. Altman, V. Kumar, H. Mannila, and D. Pregibon, "Emerging Scientific Applications in Data Mining", Communications of the ACMVolume 45, Number 8, pp 54-58, August 2002 • C. Potter, P. Tan, M. Steinbach, S. Klooster, V. Kumar, R. Myneni, V. Genovese, Major Disturbance Events in Terrestrial Ecosystems Detected using global Satellite Data Sets, Global Change Biology 9 (7), 1005-1021, 2003 • Vipin Kumar, “Parallel and Distributed Computing for Cyber Security". An article based on the keynote talk by the author at 17th International Conference on Parallel and Distributed Computing Systems (PDCS-2004). DS Online Journal, OLUME 6, NUMBER 10, October 2005 • Ying Liu, Jayaprakash Pisharath, Wei-keng Liao, Gokhan Memik, Alok Choudhary, and Pradeep Dubey. Performance Evaluation and Characterization of Scalable Data Mining Algorithms. In Proceedings of the 16th International Conference on Parallel and Distributed Computing and Systems (PDCS), November 2004. • Joseph Zambreno, Berkin Ozisikyilmaz, Jayaprakash Pisharath, Gokhan Memik, and Alok Choudhary. Performance Characterization of Data Mining Applications using MineBench. In Proceedings of the 9th Workshop on Computer Architecture Evaluation using Commercial Workloads (CAECW-9), February 2006. • Jayaprakash Pisharath, Joseph Zambreno, Berkin Ozisikyilmaz, and Alok Choudhary. Accelerating Data Mining Workloads: Current Approaches and Future Challenges in System Architecture Design. In Proceedings of the 9th International Workshop on High Performance and Distributed Mining (HPDM), April 2006