Download

1 / 37
370 likes | 533 Vues
Programming Your Network at Run-Time for Big Data Applications. Guohui Wang, TS Eugene Ng, Anees Shaikh Presented by Jon Logan. Objectives. Why Change Dynamically? Hadoop Essentials How this is accomplished SDN <-> Master Interaction Traffic Patterns Why Application Aware?

E N D
Programming Your Network at Run-Time for Big Data Applications Guohui Wang, TS Eugene Ng, AneesShaikh Presented by Jon Logan
Objectives • Why Change Dynamically? • Hadoop Essentials • How this is accomplished • SDN <-> Master Interaction • Traffic Patterns • Why Application Aware? • Traffic Estimation • Scheduling • Patterns • Constructing the Network • Implementation & Overhead • Future Work • Conclusions • Shortcomings & Discussion
Why Change Dynamically? • With advances of Software Defined Networks (SDN), we are able to dynamically change our network structure • Big Data applications often involve large amounts of data being transferred from one node to another • If you’re not careful, the network can be a bottleneck • Essentially, we want to tailor the network layout to meet current/imminently executingapplication demands • Throughout the paper and this presentation, Hadoop is used as a typical “Big Data” application
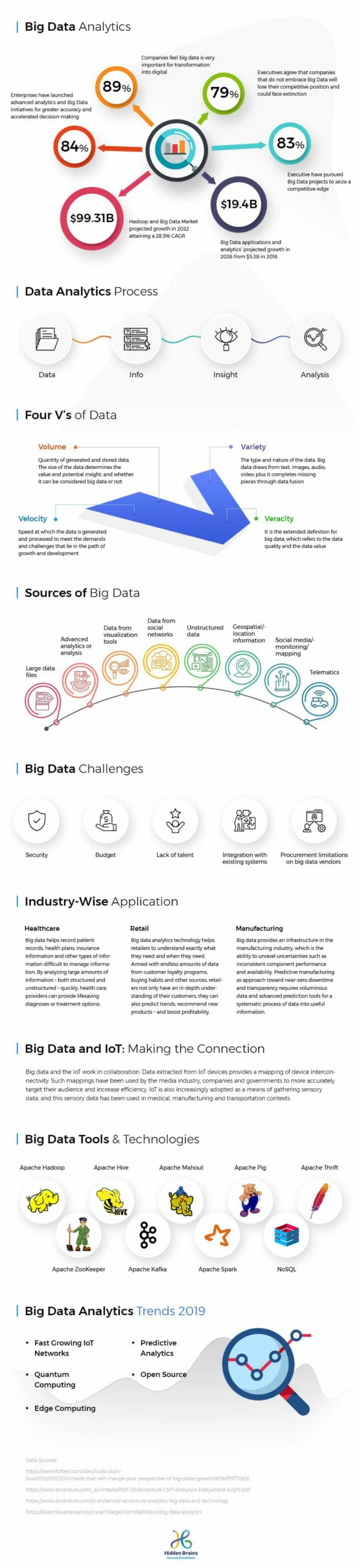
Hadoop Essentials Image source: http://www.ibm.com/developerworks/java/library/l-hadoop-3/index.html
Objectives • Why Change Dynamically? • Hadoop Essentials • How this is accomplished • SDN <-> Master Interaction • Traffic Patterns • Why Application Aware? • Traffic Estimation • Scheduling • Patterns • Constructing the Network • Implementation & Overhead • Future Work • Conclusions • Shortcomings & Discussion
How is this accomplished? • The paper is based on the idea of optical switches • Optical switches allow for the fast changing of fibre-optic links • They cite the transition time in the order of 10s of ms • Assume a hybrid electrical-optical switches • ToR switches are connected to two aggregation networks • One of them is over Ethernet (SLOW) • One of them is connected to a MEMS-optical switch (FAST) • Each ToR switch is connected to multiple optical uplinks • Typically 4-6 uplinks • Network is controlled through a SDN controller • Manages physical connectivity between ToR switches • Manages the forwarding at ToR switches using OpenFlow rules
SDN <-> Master Interaction • Hadoop jobs are coordinated through a master node • Is responsible for scheduling, managing requests, placement of nodes, etc. • All switches are controlled through a SDN controller • The paper proposes interaction between the master of the job and the SDN controller
SDN <-> Master Interaction • Proposes that the SDN Controller • Accepts traffic demand matrices from application controllers • Describes the volume and policy requirements for traffic exchanged between different racks • Issues a network configuration command to the topology accordingly • The application master can also use topology information provided by the SDN for more effective job scheduling/placement • This means that the application controller must be able to predict network usage
Objectives • Why Change Dynamically? • Hadoop Essentials • How this is accomplished • SDN <-> Master Interaction • Traffic Patterns • Why Application Aware? • Traffic Estimation • Scheduling • Patterns • Constructing the Network • Implementation & Overhead • Future Work • Conclusions • Shortcomings & Discussion
Traffic Patterns of Big Data Traffic can be categorized into three categories: • Bulk Transfer • Data Aggregation (Partitioning) • Control Messages
Control Traffic • Is typically latency sensitive, but not large volumes of data • Can simply be handled by the Ethernet network • In the paper’s “implementation”, control messages are sent over the packet-switched (Ethernet) network using the default routes
Data Aggregation / Partitioning • Data must be partitioned or aggregated between one server and a large number of other servers • Ex. Mapper output must be aggregated to (potentially) all reducers • In parallel database systems, most operations require merging/splitting of data from multiple tables • Data aggregation requires high bandwidth to exchange large volumes of data between large numbers of servers • If the network is oversubscribed, aggregation may be the bottleneck • Is the main goal that the paper ties to address
Why Application Aware? • Current approaches for routing optical circuits rely on network level statistics to estimate network demand • It is difficult to estimate real application traffic based solely on this information • Without more precise information, circuits may be configured between the wrong locations • “Circuit flapping” may also occur from repeated corrections
An Example Configuration • An 8-1 aggregation • Ex. 8 mappers outputting to 1 reducer • Each rack has a ToR switch with 3 optical links • Each optical link is capable of 10Gbps • Minimum circuit reconfiguration interval is set to 1 second • Residual Ethernet bandwidth is limited to 100Mbps • Each node wants to transfer 200MB of data to the aggregation node
A Naïve Approach • This task can be implemented in 3 rounds • In each round, 3 racks are connected directly to the aggregation rack • Repeat 3 times • This will require up to 3.16 seconds (The paper says 2.16 seconds) • If one rack is not configured to use the optical link correctly, it may have to use Ethernet, and take up to 16 seconds!
A Better Approach • If we “chain” tasks together, as we know the application demands, we could do this same transfer in just 1.48 seconds (the paper states 480ms), only requiring 1 round of switching
Objectives • Why Change Dynamically? • Hadoop Essentials • How this is accomplished • SDN <-> Master Interaction • Traffic Patterns • Why Application Aware? • Traffic Estimation • Scheduling • Patterns • Constructing the Network • Implementation & Overhead • Future Work • Conclusions • Shortcomings & Discussion
Traffic Estimation • In order to know how to allocate resources, we need to estimate demand • This is left up to the master node (In the case of Hadoop, the job tracker) • Must report a traffic demand matrix to the controller • The job tracker has information about the placement of mappers and reducers on a per-job basis • Computing the source and destination racks is easy • Computing the demand, not so easy
Estimating demand • The paper makes the assumption that more input data = more output data • This is not necessarily true • Ex. If your input is a list of URLs, a longer URL does not necessarily mean more data! • By looking at intermediate data, you can predict shuffling demand of map tasks before they complete • Glosses over the fact that mappers start transferring data before completing • Essentially, tries to state that more input data means more shuffle data
Hadoop Job Scheduling • Is currently FIFO (plus priorities) • Data locality is considered in the placement of map tasks to reduce network traffic • Reducers are schedule randomly • Hadoop could potentially change its scheduling based on real time network topology
Bin Packing Placement • Rack-based bin packing placement for reduce tasks • Attempts to minimize the number of racks utilized • Reduces the number of ToR switches required to be reconfigured • The paper is not clear how they actually accomplish this, if it is based on network demand or not. • Hadoop has a concept of “slots” for reducers, somewhat negating any real “bin packing” problem, if it were not for network usage • This would also require machines to be able to handle the huge amount of bandwidth that could be sent to them (up to 30Gbps in their scenario), in order to make it worthwhile
Batch Processing • Would essentially process entire batches of jobs together, within a time interval T • The job tracker selects those with the greatest estimated volume and requests the SDN to configure the network to best handle these jobs • Is not clear how you estimate this! Previous discussion always discussed talking about already running jobs • Tasks in earlier batches have higher priority • Helps aggregate traffic from multiple jobs to create long duration traffic that is suitable for optical paths • Can be implemented as a “simple extension” to the Hadoop job scheduling • In reality, it wouldn’t be “simple” by any means
Objectives • Why Change Dynamically? • Hadoop Essentials • How this is accomplished • SDN <-> Master Interaction • Traffic Patterns • Why Application Aware? • Traffic Estimation • Scheduling • Patterns • Constructing the Network • Implementation & Overhead • Future Work • Conclusions • Shortcomings & Discussion
Topology and Routing for Aggregation Patterns • The major issue with Hadoop jobs is intermediate data between mappers and reducers • Is essentially a N-to-M shuffling, where N is the number of mappers, and M is the number of reducers
Single Aggregation Pattern • Is the case when multiple reducers need to output to a single mapper • N-to-1 aggregation • As discussed earlier, we can construct a 2-hop aggregation tree in this case (ex. 8-to-1) • We can place racks with higher traffic demand “closer” to the aggregator in the tree • Ex. Make sure mappers 5, 1, 6 have the highest demand to reduce the number of hops
Data shuffling pattern • Is essentially an N-to-M aggregation • Ex. 8-to-4 shuffling • The paper relies on Hypercube or Torus Topology to achieve this • We want to place racks with high demand close to each other • Reduces amount of multi-hop traffic • Constructing an optimal Torus topology is difficult due to thelarge search space • A greedy heuristic algorithm can beused • Places racks into a 2-D coordinate space and connects each row and each column into rings
Constructing the Torus Topology • An N-to-M shuffling pattern with R racks can be reduced to a X x Y topology • X = , Y= • The network is constructed as follows: • Find four neighbors for each rack based on traffic demand and rank all racks based on the overall traffic demand to its neighbors • Construct the Torus from the highest ranked rack S • Connect two rings around S with X and Y racks into the rings respectively. Racks with higher traffic demand to S will be placed closer to S in the ring • These two rings will be the “framework” for the Torus topology, which maps to coordinates (0,0), …, (0, X-1) and (0,0), …, (Y-1, 0) in the Torus space • Select racks from row 2 to Y one by one based on the coordinates • Given a coordinate {(x,y), x > 0, y > 0}, select the rack with the highest overall demand to neighboring racks { (x-1, y), (x, y-1), ((x + 1) % X, y) (x, (y+1) % Y) } • If a neighbor rack has not been placed, the demand is ignored
Constructing the Network • A routing scheme well suited for shuffling traffic is a per-destination spanning tree • Build a spanning tree rooted at each aggregator rack • Traffic routed to the aggregator rack will be routed over this tree • When an optical link is selected, increase its weight to favor other links for other spanning trees • This allows us to exploit all available links, and to achieve better load balancing and multi-pathing among multiple spanning trees
Partially Overlapping Aggregations • Some aggregations may overlap source or destination racks • Building a Torus network would have poor utilization • S1’ and S3’ are essentially N-1 aggregations • S2’ is essentially an N-2 aggregation • Can use previously discussed configuration algorithms to schedule the network • Depending on available links, we could either schedule them concurrently or consecutively • Allows for path sharing among aggregations, and improving utilization of circuits
Objectives • Why Change Dynamically? • Hadoop Essentials • How this is accomplished • SDN <-> Master Interaction • Traffic Patterns • Why Application Aware? • Traffic Estimation • Scheduling • Patterns • Constructing the Network • Implementation & Overhead • Future Work • Conclusions • Shortcomings & Discussion
Implementation and Overhead • To implement, we need to use OpenFlow rules on ToR switches and issue commands to reconfigure optical switches • Commercial optical switches can switch in less than 10ms • Run-time routing configuration over a dynamic network requires rapid and frequent table updates on potentially large number of switches • Routing configuration has to be done within a short period of time • Requires the SDN to be scalable and responsiveness • We want to minimize the number of rules required • Reduces table size (which is limited) • Reduces delays in reconfiguring the network
Implementation • We can use the VLAN field on packets to tag the destination rack • Each rack is assigned to one VLAN ID • Packets sent to a destination rack will all have the same VLAN ID • Packet tagging could also be implemented at the server kernel levelor using hypervisor virtual switches • Servers can look up the VLAN tag in a repository based on the destination • We would need at most N rules on each switch, where N is the number of racks • Most MR jobs last for several minutes (paper cites 10s of seconds or more) • Largest MR jobs use hundreds of servers • Equals tens of racks (at 20-40 servers per rack) • Commercial switches can install more than 700 rules per second • They estimate 10s of ms to reconfigure the network for a typical MR job
Implementation • We need to be careful when rerouting multiple switches • Need to avoid potential transient errors or forwarding loops • Proposed solutions for this require a significant amount of extra rules on each switch • Unknown amount of delay this approach adds to achieve a consistent state during topology updates
Objectives • Why Change Dynamically? • Hadoop Essentials • How this is accomplished • SDN <-> Master Interaction • Traffic Patterns • Why Application Aware? • Traffic Estimation • Scheduling • Patterns • Constructing the Network • Implementation & Overhead • Future Work • Conclusions • Shortcomings & Discussion
Future Work • Fault tolerance, Fairness, and Priority • Fairness and priority of network topology among different applications • Must be handled by the SDN • Traffic engineering • Could potentially allow rerouting over multiple paths, even if optical switches are not available
Conclusion • The paper claims the analysis has great promise of integrated network control • Although the discussion primarily relied on Hadoop, most Big Data applications have similar traffic patterns • Aggregation patterns can be applied to those as well • Study serves as a “step towards tight and dynamic interaction between applications and networks” using SDN
Shortcomings / Discussion • This relies heavily on the ability to predict application usage • Is not as simple as they portray it to be • More input is not necessarily more output! • Also seems to lack any real evaluation of their proposal • No actual data; no data even realistically modeled • Assumes a 100Mbps Ethernet, which seems low (1Gbps is the bare minimum in modern day applications) • Assumes that mappers would not have consistent load • If they go with their assumption that more input = more output, and it scales linearly, this is not true! • Mappers are all (except for the last one) generally given roughly equal chunks of data (unless you have a bizarre input split) • Therefore, Mappers should have consistent network load (if their assumptions are valid)