Query Processing and Optimization
430 likes | 707 Vues
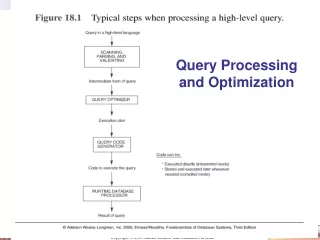
Query Processing and Optimization. General Overview. Relational model - SQL Formal & commercial query languages Functional Dependencies Normalization Physical Design Indexing Query Processing and Optimization. Review: QP & O. SQL Query. Query Processor. Parser. Query Optimizer.

Query Processing and Optimization
E N D
Presentation Transcript
General Overview • Relational model - SQL • Formal & commercial query languages • Functional Dependencies • Normalization • Physical Design • Indexing • Query Processing and Optimization
Review: QP & O SQL Query Query Processor Parser Query Optimizer Algebraic Expression Execution plan Evaluator Data: result of the query
Review: QP & O Query Optimizer Algebraic Representation Query Rewriter Algebraic Representation Data Stats Plan Generator Query Execution Plan
Selections Involving Comparisons Query: Att K (r ) • A6 (primary index, comparison). (Relation is sorted on Att) • For Att V(r) use index to find first tuple v and scan relation sequentially from there • For AttV (r) just scan relation sequentially till first tuple > v; do not use index Cost: EA5 =HTi + c / fr (where c is the cardinality of result) HTi k ... k
How big is c? Query: Att K (r ) Cardinality: More metadata on r are needed: min (att, r) : minimum value of att in r max(att, r): maximum value of att in r Then the selectivity of Att = K (r ) is estimated as: (or nr /2 if min, max unknown) Intuition: assume uniform distribution of values between min and max min(attr, r) K max(attr, r)
Plan generation: Range Queries Att K (r ) A6: (secondary index, comparison). Cost: EA6 = HTi -1+ #of leaf nodes to read + # of file blocks to read = HTi -1+ LBi * (c / nr) + c, if att is a candidate key HTi ... k+m k, k+1 k+1 ... k+m k
Plan generation: Range Queries A6: (secondary index, range query). If att is NOT a candidate key HTi ... k+m k, k+1 ... k ... k k+1 k+m ...
Cost: EA6 = HTi -1+ #of leaf nodes to read + #of file blocks to read +#buckets to read = HTi -1+ LBi * (c / nr) + c + x
Join Operation • Size and plans for join operation • Running example: depositor customer Metadata: ncustomer = 10,000 ndepositor = 5000 fcustomer = 25 fdepositor = 50 bcustomer= 400 bdepositor= 100 V(cname, depositor) = 2500 (each customer has on average 2 accts) cname in depositor a foreign key for customer depositor(cname, acct_no) customer(cname, cstreet, ccity)
Cardinality of Join Queries • What is the cardinality (number of tuples) of the join? E1: Cartesian product: ncustomer * ndepositor = 50,000,000 E2: Attribute cname common in both relations, 2500 different cnames in depositor Size: ncustomer * (avg# of tuples in depositor with same cname) = ncustomer * (ndepositor / V(cname, depositor)) = 10,000 * (5000 / 2500) = 20,000
Cardinality of Join Queries E3: cname is a foreign key for depositor on customer Size: ndepositor * (avg # of tuples in customer with same cname) = ndepositor * 1 = 5000 Note: If cname is a key for customer but it is NOT a foreign key for depositor, (i.e., not all cnames of depositor are in customer) then 5000 an UPPER BOUND Some customer names may not match w/ any customers in customer
Cardinality of Joins in general Assume join: R S • If R, S have no common attributes: nr * ns • If R,S have attribute A in common: (take min) • If R, S have attribute A in common and: • A is a candidate key for R: ≤ ns • A is candidate key in R and candidate key in S : ≤ min(nr, ns) • A is a key for R, foreign key for S: = ns
Nested-Loop Join Query: R S Algorithm 1: Nested Loop Join Idea: t1 u1 Blocks of... t2 u2 t3 u3 R S results Compare: (t1, u1), (t1, u2), (t1, u3) ..... Then: GET NEXT BLOCK OF S Repeat: for EVERY tuple of R
Nested-Loop Join Query: R S Algorithm 1: Nested Loop Join for each tuple tr in R do for each tuple usin S dotest pair (tr,us) tosee if they satisfy the join condition if they do (a “match”), add tr• usto the result. R is called the outerrelation and S the inner relation of the join.
Nested-Loop Join (Cont.) Cost: • Worst case, if buffer size is 3 blocks br + nrbsdisk accesses. • Best case: buffer big enough for entire INNER relation + 2 br + bs DAs. ncustomer = 10,000 ndepositor = 5000 fcustomer = 25 fdepositor = 50 bcustomer= 400 bdepositor= 100 • Assuming worst case memory availability cost estimate is • 5000 400 + 100 = 2,000,100 disk accesses with depositor as outer relation, and • 10000 100 + 400 = 1,000,400 disk accesses with customer as the outer relation. • If smaller relation (depositor) fits entirely in memory, the cost estimate will be 500 disk accesses. (actually we need 2 more blocks)
Join Algorithms Query: R S Algorithm 2: Block Nested Loop Join Idea: t1 u1 Blocks of... t2 u2 t3 u3 R S results Compare: (t1, u1), (t1, u2), (t1, u3) (t2, u1), (t2, u2), (t2, u3) (t3, u1), (t3, u2), (t3, u3) Then: GET NEXT BLOCK OF S Repeat: for EVERY BLOCK of R
Block Nested-Loop Join • Block Nested Loop Join for each block BRofR dofor each block BSof S do for each tuple trin BR do for each tuple usin Bsdo beginCheck if (tr,us) satisfy the join condition if they do (“match”), add tr• usto the result.
Block Nested-Loop Join (Cont.) Cost: • Worst case estimate: br bs + br block accesses. • Best case: br+ bsblock accesses. Same as nested loop. • Improvements to nested loop and block nested loop algorithms for a buffer with M blocks: • In block nested-loop, use M — 2 disk blocks as blocking unit for outer relations, where M = memory size in blocks; use remaining two blocks to buffer inner relation and output • Cost = br / (M-2) bs + br • If equi-join attribute forms a key or inner relation, stop inner loop on first match • Scan inner loop forward and backward alternately, to make use of the blocks remaining in buffer (with LRU replacement)
Join Algorithms Query: R S Algorithm 3: Indexed Nested Loop Join Idea: t1 Blocks of... t2 t3 R S results (fill w/ blocks of S or index blocks) For each tuple ti of R if ti.A = K (A is the attribute R,S have in common) then use the index to compute att = K (S ) Demands: index on A for S
Indexed Nested-Loop Join Indexed Nested Loop Join • For each tuple tRin the outer relation R, use the index to look up tuples in S that satisfy the join condition with tuple tR. • Worst case: buffer has space for only one page of R, and, for each tuple in R, we perform an index lookup on s. • Cost of the join: br + nr c • Where c is the cost of traversing the index and fetching all matching s tuples for one tuple from r • c can be estimated as cost of a single selection on s using the join condition. • If indices are available on join attributes of both R and S,use the relation with fewer tuples as the outer relation.
Example of Nested-Loop Join Costs Query: depositor customer (cname, acct_no) (cname, ccity, cstreet) Metadata: customer: ncustomer = 10,000 fcustomer = 25 bcustomer = 400 depositor: ndepositor = 5000 fdepositor = 50 bdepositor = 100 V (cname, depositor) = 2500 i a primary index on cname (dense) for customer (fi = 20) Minimal buffer
Plan generation for Joins Algorithm 2: Block Nested Loop 1a: customer = OUTER relation depositor = INNER relation cost: bcustomer + bdepositor * bcustomer = 400 +(400 *100) = 40,400 1b: customer = INNER relation depositor = OUTER relation cost: bdepositor + bdepositor * bcustomer = 100 +(400 *100) = 40,100
Plan generation for Joins Algorithm 3: Indexed Nested Loop We have index on cname for customer. Depositor is the outer relation Cost: bdepositor + ndepositor * c = 100 +(5000 *c ) , c is the cost of evaluating a selection cname=K using index. What is c? Primary index on cname, cname a key for customer c = HTi +1
Plan generation for Joins What is HTi ? cname a key for customer. V(cname, customer) = 10,000 fi = 20, i is dense LBi = 10,000/20 = 500 HTi ~ logfi(LBi) + 1 = log20 500 + 1 = 4 Cost of index nested loop is: = 100 + (5000 * (4+1)) = 25,100 BA (cheaper than NLJ)
pR pS Another Join Strategy Query: R S Algorithm: Merge Join Idea: suppose R, S are both sorted on A (A is the common attribute) A A 2 2 3 5 1 2 3 4 ... ... Compare: (1, 2) advance pR (2, 2) match, advance pS add to result (2, 2) match, advance pS add to result (2, 3) advance pR (3, 3) match, advance pS add to result (3, 5) advance pR (4, 5) read next block of R
Merge-Join GIVEN R, S both sorted on A • Initialization • Reserve blocks of R, S into buffer reserving one block for result • Pr= 1, Ps =1 • Join (assuming no duplicate values on A in R) WHILE !EOF( R) && !EOF(S) DO if BR[Pr].A == BS[Ps].A then output to result; Ps++ else if BR[Pr].A < BS[Ps].A then Pr++ else (same for Ps) if Pr or Ps point past end of block, read next block and set Pr(Ps) to 1
Merge-Join (Cont.) • Each block needs to be read only once (assuming all tuples for any given value of the join attributes fit in memory) • Thus number of block accesses for merge-join is bR + bS • But.... What if one/both of R,S not sorted on A? Ans: May be worth sorting first and then perform merge join (Sort-Merge Join) Cost: bR + bS + sortR + sortS
External Sorting Not the same as internal sorting Internal sorting: minimize CPU (count comparisons) best: quicksort, mergesort, .... External sorting: minimize disk accesses (what we ‘re sorting doesn’t fit in memory!) best: external merge sort WHEN used? 1) SORT-MERGE join 2) ORDER BY queries 3) SELECT DISTINCT (duplicate elimination)
d e g m p r 31 16 24 3 2 16 External Sorting Idea: 1. Sort fragments of file in memory using internal sort (runs). Store runs on disk. 2. Merge runs. E.g.: a b c 19 14 33 a d g 19 31 24 sort a a b c d d d e g m p r g a d c b e r d m p d a 14 19 14 33 7 21 31 16 24 3 2 16 24 19 31 33 14 16 16 21 3 2 7 14 merge sort b c e 14 33 16 merge sort a d d 14 7 21 d m r 21 3 16 sort merge a d p 14 7 2
External Sorting (cont.) Algorithm Let M = size of buffer (in blocks) 1. Sort runs of size M blocks each (except for last) and store. Use internal sort on each run. 2. Merge M-1 runs at a time into 1 and store. Merge for all runs. 3. if step 2 results in more than 1 run, goto step 2. Run m-1 Output Run 1 Run 2 ........ Run 3
External Sorting (cont.) Cost: 2 bR * (logM-1(bR / M) + 1) Intuition: Step 1: create runs every block read and written once cost 2 bR I/Os Step 2: Merge every merge iteration requires reading and writing entire file (2 bR I/Os) Total: logM-1(bR / M) Iteration # --------------- 1 2 3 ..... Runs Left to Merge ----------------------------
What if we need to sort? Query: depositor customer Merge-sort Join Sorting depositor: bdepositor = 100 Sort depositor = 2 * 100 * (log2(100 / 3) + 1) = 1400 Same for customer. Total: 100 + 400 + 1400 + 7200 = 9100 I/O’s! Still beats BNLJ (40K), INLJ (25K) Why not use SMJ always? Ans: 1) Sometimes inner relation can fit in memory 2) Sometimes index is small 3) SMJ only work for natural joins, “equijoins”
Hash- joins • Applicable only to natural joins, equijoins Depends upon hash function h, used to partition both relations must map values of joins attributes to { 0, ..., n-1} s.t. n = #partitions
Hash-Join Algorithm Algorithm: Hash Join • Partition the relation S using hashing function h so that each si fits in memory. Use 1 block of memory as the output buffer for each partition. (at least n blocks) 2. Partition R using h. • For each partition #i (0,… n-1) • Use BNLJ to compute the join between Ri and Si : Ri Si (optimal since si fits in memory, inner relation) S is called the build input and R is called the probe input. Note: can reduce CPU costs by building in-memory hash index for each si using a different hash function than h.
Hash Join Partitioning: must choose: • # of partitions, n • hashing function, h (each tuple {0, ..., n-1}) Goals (in order of importance) 1. Each partition of build relation should fit in memory (=> h is uniform, n is large) 2. For partitioning step, can fit 1 output block of each partition in memory (=> n is small (<= M-1)) Strategy: Ensure #1. Deal with violations of #2 when needed.
Hash Join Goal #1: Partitions of build relations should fit in memory: 1 ... Memory (M blocks) n n should be? Ans: (reserving 2 blocks for R partition, output of BNLJ) (In practice, a little large (fudge factor~1.2) as not all memory available for partition joins)
Hash Join Goal #2: keep n < M what if not possible? Recursive partitioning! Idea: Iteration #1: Partition S into M-1 partitions using h1 Iteration #2: Partition each partition of S into M-1 partitions using a different hash function h2 ...... repeat until partition S into >=
Cost of Hash-Join Cost: case 1: No recursive partitioning 1. Partition S: bS reads and bS + n writes. Why n? 2. Rartition R: bR reads and bR + n writes. 3. n partition joins: bR + bS + 2n Reads • Total: 3(bR + bS) +4 n Typically n is small enough (roughly ) so it can be ignored.
Cost of Hash-Join case 2: Recursive Partitioning Recall: partition build relation M-1 ways at each time. So, total number of iterations: logM–1(n) ~ logM–1(bS / M-2) ~ logM–1(bS / M-1) = = logM–1bS - 1 • Cost: 1. partition S : 2 bS (logM–1bS - 1) 2. partition R: 2 bR (logM–1bS - 1) 3. n partition joins: bR + bS Total cost estimate is: 2(bR + bS)(logM–1(bS)-1) + bR + bS
Example of Cost of Hash-Join customer depositor • Assume that memory size is M=3 blocks • bdepositor= 100 and bcustomer= 400. • depositor is to be used as build input. NO Recursive partitioning: 2(bcust + bdep) (log2(bdep) -1)+ bdep + bcust = 1000 (6) + 500 = 6500 I/O’s ! Why ever use Sort-Merge-Join? 1) both input relations already sorted 2) skewless hash functions hard.