Download

1 / 69
700 likes | 732 Vues
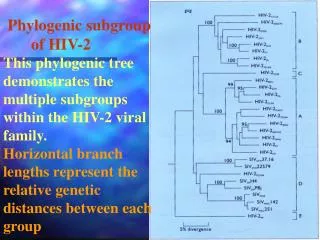
Nada Lavrač Subgroup Discovery: Recent Biomedical Applications Solomon seminar, Ljubljana, January 2008. Talk outline. Data mining in a nutshell Subgroup discovery in a nutshell Relational data mining and propositionalization in a nutshell DNA Microarray Data Analysis with SD

E N D
Nada Lavrač Subgroup Discovery: Recent Biomedical Applications Solomon seminar, Ljubljana, January 2008
Talk outline • Data mining in a nutshell • Subgroup discovery in a nutshell • Relational data mining and propositionalization in a nutshell • DNA Microarray Data Analysis with SD • RSD approach to Descriptive Analysis of Differentially Expressed Genes • Future work: Towards service-oriented knowledge technologies for information fusion
Data Mining in a Nutshell knowledge discovery from data Data Mining model, patterns, … data • Given:transaction data table, relational database, text • documents, Web pages • Find: aclassification model, a set of interesting patterns
Data Mining in a Nutshell knowledge discovery from data Data Mining model, patterns, … data • Given:transaction data table, relational database, text • documents, Web pages • Find: aclassification model, a set of interesting patterns symbolic model symbolic patterns explanation new unclassified instance classified instance black box classifier no explanation
Output: Decision tree for contact lens prescription tear prod. reduced normal astigmatism NONE no yes spect. pre. SOFT myope hypermetrope HARD NONE
Output: Classification/prediction rules for contact lens prescription tear production=reduced→lenses=NONE tear production=normal& astigmatism=yes & spect. pre.=hypermetrope→lenses=NONE tear production=normal& astigmatism=no →lenses=SOFT tear production=normal& astigmatism=yes & spect. pre.=myope →lenses=HARD DEFAULT lenses=NONE
Task reformulation: Concept learning problem (positive vs. negative examples of Target class)
Classification versus Subgroup Discovery • Classification task – constructing models from data (constructing sets of predictive rules) • Predictive induction – aimed at learning models for classification and prediction • Classification rules aim at covering only positive examples • A set of rules forms a domain model • Subgroup discovery task – finding interesting patterns in data (constructing individual subgroup describing rules) • Descriptive induction –aimed at exploratory data analysis • Subgroups descriptions aim at covering a significant proportion of positive examples • Each rule (pattern) is an independent chunk of knowledge
Classification versus Subgroup Discovery + + + + + + + + + + + + + + + + + + + + + +
Talk outline • Data mining in a nutshell • Subgroup discovery in a nutshell • Relational data mining and propositionalization in a nutshell • DNA Microarray Data Analysis with SD • RSD approach to Descriptive Analysis of Differentially Expressed Genes
Subgroup discovery in a nutshell • SD Task definition • Given: a set of labeled training examples and a target class of interest • Find: descriptions of`most interesting’ subgroups of target class examples • are as large as possible (high target class coverage) • have significantly different distribution of the target class examples (high TP/FP ratio, high RelAcc, high significance • Other (subjective) criteria of interestingness • Surprising to the user, simple, .…useful - actionable
CHD Risk Group Discovery Task • Task: Find and characterize population subgroups with high CHD risk • Input: Patient recordsdescribed by stage A (anamnestic), stage B (an. & lab.), and stageC (an., lab. & ECG) attributes • Output: Best subgroup descriptions that are most actionable for CHD risk screening at primary health-care level
Subgroup discovery in the CHD application From best induced subgroup descriptions, five were selected by the expert as most actionable for CHD risk screening (by GPs): A1: CHD male & pos. fam. history & age > 46 A2: CHD female & bodymassIndex > 25 & age > 63 B1: CHD ..., B2: CHD ..., C1: CHD ... Principal risk factors (found by subgroup mining) Supporting risk factors (found by statistical analysis): A1: psychosocial stress, as well as cigarette smoking, hypertension and overweight A2: …
Characteristics of Subgroup Discovery Algorithms positives negatives truepositives falsepos. • Remark: Subgroup discovery can be viewed as cost-sensitive rule learning, rewarding TP covered, and punishing FP covered. • SD algorithm does not look for a single complex rule to describe all examples of target class A (all CHD patients), but several rules that describe parts (subgroups) of A. • SD prefers rules that are accurate (cover only CHD patients) and have high generalization potential (cover large patient subgroups) • This is modeled by parameter g of the rule quality heuristic of SD. • SD naturally uses example weights in its procedure for repetitive subgroup generation, via its weighted covering algo., and rule quality evaluation heuristic.
Weighted covering algorithm for rule set construction CHD patients other patients 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 For learning a set of subgroup describing rules, SD implements an iterative weigthed covering algorithm. Quality of a rule is measured by tading off coverage and precision.
Weighted covering algorithm for rule set construction f2 and f3 CHD patients other patients 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 Rule quality measure in SD: q(Cl Cond) = TP/(FP+g) Rule quality measure in CN2-SD: WRAcc(Cl Cond) = p(Cond) x [p(Cl | Cond) – p(Cl)] = coverage x (precision – default precision) = = …= Pos/N x Neg/N x [TPr – FPr] *Coverage = sum of the covered weights, *Precision = purity of the covered examples
Weighted covering algorithm for rule set construction CHD patients other patients 0.5 1.0 0.5 1.0 0.5 1.0 0.5 1.0 1.0 0.5 0.5 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 In contrast with classification rule learning algorithms (e.g. CN2), the covered positive examples are not deleted from the training set in the next rule learning iteration; they are re-weighted, and a next ‘best’ rule is learned.
Subgroup visualization The CHD task: Find, characterize and visualize population subgroups with high CHD risk (large enough, distributionally unusual, most actionable)
Induced subgroups and their statistical characterization Subgroup A2 for femle patients: High-CHD-risk IF body mass index over 25 kg/m2 (typically 29) AND age over 63 years Supporting characteristics are positive family history and hypertension. Women in this risk group typically have slightly increased LDL cholesterol values and normal but decreased HDL cholesterol values.
Statistical characterization of subgroups • starts from induced subgroup descriptions • statistical significance of all available features (all risk factors) is computed given two populations: true positive cases (CHD patients correctly included into the subgroup) and all negative cases (healthy subjects) • 2 test with 95% confidence level is used
Propositional subgroup discovery algorithms SD algorithm (Gamberger & Lavrač, JAIR 2002) APRIORI-SD (Kavsek & Lavrač, AAI 2006) CN2-SD (Lavrač et al., JMLR 2004): Adapting CN2 classification rule learner to Subgroup Discovery: • Weighted covering algorithm • Weighted relative accuracy (WRAcc) search heuristics, with added example weights • WRAcc trade-off between rule coverage and rule accuracy • Probabilistic classification • Evaluation with different rule interestingness measures
Subgroup discovery lessons learned • In expert-guided subgroup discovery, the expert may decide to choose sub-optimal subgroups, which are themost actionable • A weigted covering algorithm forrule subset construction (or rule set selection), usingdecreased weights of covered positive examples, can be used to construct/select a small set of relatively independent patterns • Additional evidence in the form ofsupporting factorsincreases expert’s confidence in rules resulting from automated discovery • Value-added:Subgroup visualization
Talk outline • Data mining in a nutshell • Subgroup discovery in a nutshell • Relational data mining and propositionalization in a nutshell • DNA Microarray Data Analysis with SD • RSD approach to Descriptive Analysis of Differentially Expressed Genes
Relational Data Mining (Inductive Logic Programming) in a Nutshell Relational Data Mining knowledge discovery from data model, patterns, … • Given: a relational database, a set of tables. sets of logical facts, a graph, … • Find: aclassification model, a set of interesting patterns
Learning from multiple tables Complex relational problems: temporal data: time series in medicine, trafic control, ... structured data: representation of molecules and their properties in protein engineering, biochemistry, ... Illustrative example: structured objects - Trains Relational Data Mining (ILP)
RSD: Upgrading CN2-SD to Relational Subgroup Discovery • Implementing an propositionalization approach to relational data mining, through efficient first-order feature construction • Using CN2-SD for propositional subgroup discovery features Subgroupdiscovery rules First-order featureconstruction
Propositionalization in a nutshell TRAIN_TABLE Propositionalization task Transform a multi-relational (multiple-table) representation to a propositional representation (single table) Proposed in ILP systems LINUS (1991), 1BC (1999), … PROPOSITIONAL TRAIN_TABLE
Propositionalization in relational data mining TRAIN_TABLE Main propositionalization step: first-order feature construction f1(T):-hasCar(T,C),clength(C,short). f2(T):-hasCar(T,C), hasLoad(C,L), loadShape(L,circle) f3(T) :- …. Propositional learning: t(T)f1(T), f4(T) Relational interpretation: eastbound(T) hasShortCar(T),hasClosedCar(T). PROPOSITIONAL TRAIN_TABLE
Relational subgroup discovery • RSD algorithm (Lavrac et al., ILP 2002, Zelezny & Lavrac, MLJ 2006) • Implementing an propositionalization approach to relational learning, through efficient first-order feature construction • Syntax-driven feature construction, using Progol/Aleph style of modeb/modeh declaration f121(M):- hasAtom(M,A), atomType(A,21) f235(M):- lumo(M,Lu), lessThr(Lu,1.21) • Using CN2-SD for propositional subgroup discovery mutagenic(M)feature121(M), feature235(M) features Subgroupdiscovery rules First-order featureconstruction
RSD Lessons learned Efficient propositionalization can be applied to individual-centered, multi-instance learning problems: • one free global variable (denoting an individual, e.g. molecule M) • one or more structural predicates: (e.g. has_atom(M,A)), each introducing a new existential local variable (e.g. atom A), using either the global variable (M) or a local variable introduced by other structural predicates (A) • one or more utility predicates defining properties of individuals or their parts, assigning values to variables feature121(M):- hasAtom(M,A), atomType(A,21) feature235(M):- lumo(M,Lu), lessThr(Lu,-1.21) mutagenic(M):- feature121(M), feature235(M)
Talk outline • Data mining in a nutshell • Subgroup discovery in a nutshell • Relational data mining and propositionalization in a nutshell • DNA Microarray Data Analysis with SD • RSD approach to Descriptive Analysis of Differentially Expressed Genes
DNA microarray data analysis • Genomics: The study of genes and their function • Functional genomics is a typical scientific discovery domain characterized by • a very large number of attributes (genes) relative to the number of examples (observations). • typical values: 7000-16000 attributes, 50-150 examples • Functional genomics using gene expression monitoring by DNA microarrays (“gene chips”) enables: • better understanding of many biological processes • improved disease diagnosis and prediction in medicine
Gene Expression Data: data mining format #1 #2 #100 … fewcases many features 35/71
Learning (model construction) Standard approach: High-Dimensional Classification Models New sample New sample Class Class • Neural Networks, Support Vector Machines, ...
High-Dimensional Classification Models(cont’d) • Usually good at predictive accuracy • Golub et al., Science286:531-537 1999 • Ramaswamy et al., PNAS 98:15149-54 2001 • Resistance to overfitting (mainly SVM, ensembles, ...) • Butblack boxmodels are hard to interpret ??
Subgroup discovery in DNA microarray data analysis: Functional genomics domains • Two-class diagnosis problem of distinguishing between acute lymphoblastic leucemia (ALL, 27 samples) and acute myeloid leukemia (AML, 11 samples), with 34 samples in the test set. Every sample is described with gene expression values for 7129 genes. • Multi-class cancer diagnosis problem with 14 different cancer types, in total 144 samples in the training set and 54 samples in the test set. Every sample is described with gene expression values for 16063 genes. • http://www-genome.wi.mit.edu/cgi-bin/cancer/datasets.cgi
Subgroup discovery in microarray data analysis • Applying SD algorithm to cancer diagnosis problem with 14 different cancer types (leukemia, CNS, lung cancer, lymphoma, …) • Altogether 144 samples in the training set, 54 samples in the test set. • Every sample is described with gene expression values for 16063 genes. IF(KIAA0128_gene EXPRESSED) AND(prostaglandin_d2_synthase_geneNOT_EXP) THEN Leukemia training set test set sensitivity 23/24 4/6 specificity 120/120 47/48
Subgroup discovery in microarray data analysis: Extert’s comments “SD results in simple IF-THEN rules, interpretable by biologists.” “The best-scoring rule for leukemiashows expression ofKIAA0128(Septin 6)whose relation to the disease is directly explicable.” “The second condition is concerned with the absence ofProstaglandin Dsynthase (PGDS). PGDS is an enzyme active in the production of Prostaglandins (pro-inflammatory an anti-inflammatory molecules). Elevated expression of PGDS has been found in brain tumors, ovarian and breast cancer [Su2001,Kawashima2001], while hematopoietic PGDS has not been, to our knowledge, associated with leukemias.”
IF gene_20056 EXPRESSEDAND gene_23984 NOT_EXPRESSEDTHEN cancer_class = AML !! Propositional subgroup discovery: Accuracy-Interpretability tradeoff • Patterns in the form of IF-THEN rules induced by SD • Interpretableby biologists • D. Gamberger, N. Lavrač, F. Železný, J. Tolar Jr Biomed Informatics 37(5):269-284 2004 • Special care taken to avoid “fluke” rules • Still, inferior in terms of accuracy
Talk outline • Data mining in a nutshell • Subgroup discovery in a nutshell • Relational data mining and propositionalization in a nutshell • DNA Microarray Data Analysis with SD • RSD approach to Descriptive Analysis of Differentially Expressed Genes
Learning 1 Accuracy-Interpretability tradeoff Classification Learning 2 (exploratory analysis) Genes coding for proteins located in the integral to membrane cell component, whose functions include receptor activity Interpretation • Dilemma:Accuracy or Interpretability ? • Our approach to achieve bothat the same time: • Learn an accurate high-dim classifier • Learn comprehensible summarizations of genes in the classifier by relational subgroup discovery • Learning 2: instances are genes, not patients !!!
Actual approach approach to Learning 1: Identifying sets of differentially expressed genes in data preprocessing 44/28
Gene i Identifying diffferentially expressed genes Sample j Two-sample t-statistic: … 45/28
Identifying diffferentially expressed genes Two-sample t-statistic: … • We want to find genes that display a large difference in gene expression between groups and are homogeneous within groups • Typically, one would use statistical tests (e.g. t-test) and calculate p-values (e.g. permutation test) • p-values from these tests have to be corrected for multiple testing (e.g. Bonferroni correction) The two sample t–statistic is used to test equality of the group means m1, m2.
Ranking of differentially expressed genes The genes can be ordered in a ranked list L, according to their differential expression between the classes. The challenge is to extract meaning from this list, to describe them. The terms of the Gene Ontology were used as a vocabulary for the description of the genes. Selected genes have different influence on the classifier. The weight of that influence can be extracted from the learned model (e.g. voting algorithm or SVM) or from the gene selection algorithm, in a form of a score, or weight. Description of the selected genes should be biased towards the genes with higher weights.
A J Statistical Significance Meets BiologicalRelevance: Motivation for relational feature construction Interesting… Maybe even more interesting? • Gene A is obvious, well-known, and not interesting • Gene J activates gene X, which is an oncogene 48/28
Relational Subgroup Discovery “Learning 2” technically: • Discovery of gene subgroups which • largely overlap with those associated by the classifier with a given class • can be compactly summarized in terms of their features • What are features? • attributes of the original attributes (genes), and • first-order features extractedfrom the Gene Ontology and NCBI gene annotation database ENTREZ • Recent work: first-order features generated from GO, ENTREZ and KEGG
Gene Ontology (GO) • GO is a database of terms for genes: • Function - What does the gene product do? • Process - Why does it perform these activities? • Component - Where does it act? • Known genes are annotated to GO terms(www.ncbi.nlm.nih.gov) • Terms are connected as a directed acyclic graph (is_a, part_of) • Levels represent specificity of the terms 12093 biological process 1812 cellular components 7459 molecular functions