Download

1 / 26
260 likes | 384 Vues
Data Mining in Business and Economic Analysis. Renata Benda Prokeinova Department of Statistics and Operation Research FEM SUA in Nitra. Data, Information and Knowledge. Data are any facts, numbers, or text that can be processed by a computer.

E N D
Data Mining in Business and Economic Analysis RenataBenda Prokeinova Department of Statistics and Operation Research FEM SUA in Nitra
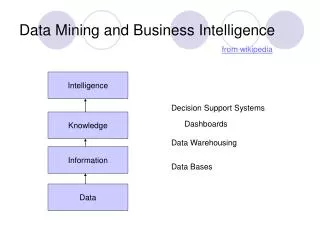
Data, Information and Knowledge • Data are any facts, numbers, or text that can be processed by a computer. • Today, organizations are accumulating vast and growing amounts of data in different formats and different databases. • The patterns, associations, or relationships among all this data can provide information.
Data, Information and Knowledge • Information can be converted into knowledge about historical patterns and future trends. For example, summary information on retail supermarket sales can be analyzed in light of promotional efforts to provide knowledge of consumer buying behavior.
Data Warehouses Dramatic advances in data capture, processing power, data transmission, and storage capabilities are enabling organizations to integrate their various databases into data warehouses. Data warehousing is defined as a process of centralized data management and retrieval. Data warehousing, like data mining, is a relatively new term although the concept itself has been around for years. Data warehousing represents an ideal vision of maintaining a central repository of all organizational data. Centralization of data is needed to maximize user access and analysis. Technological advances are making this vision a reality for many companies. And, equally advances in data analysis software are allowing users to access this data freely. The data analysis software is what supports data mining.
Introduction about Data Mining Basic view • tons of data is collected, then quant wizards work their arcane magic, and then they know all of this amazing stuff • tells us about very large and complex data sets, the kinds of information that would be readily apparent about small and simple things.
Data Mining • is a means of automating part this process to detect interpretable patterns • Discovering information from data takes two major forms: description and prediction • At the scale we are talking about, it is hard to know what the data shows.
Final definition of Data Mining Data mining is used to simplify and summarize the data in a manner that we can understand, and then allow us to infer things about specific cases based on the patterns we have observed.
Data Mining in Marketing A company wants to launch an advertising campaign for a product. Among its present customers the company wants to post product information to those with a high probability of purchasing the product. The company has data describing the past customer behaviour and personal data about each of its customers. There are also customers who have already bought the product, e.g. in a trial period. The customers of the trial period are divided into two classes: those who have bought the product and those who have not. With this data a prediction model is created to predict the probability of purchasing the product. After that the probability of purchasing the product is predicted for all other customers. Only those with a higher probability are addressed. As a side effect the company learns with this data mining analysis which are the relevant driver attributes of its customers buying a specific product (or at least being very interested in it).
Data Mining in Marketing – example 1 Analysis local buying patterns story: They discovered that when men bought diapers on Thursdays and Saturdays, they also tended to buy beer. Further analysis showed that these shoppers typically did their weekly grocery shopping on Saturdays. On Thursdays, however, they only bought a few items. The retailer concluded that they purchased the beer to have it available for the upcoming weekend. The grocery chain could use this newly discovered information in various ways to increase revenue. For example, they could move the beer display closer to the diaper display. And, they could make sure beer and diapers were sold at full price on Thursdays.
Data Mining in Marketing -example 3 • WalMart is pioneering massive data mining to transform its supplier relationships. WalMart captures point-of-sale transactions from over 2,900 stores in 6 countries and continuously transmits this data to its massive 7.5 terabyte Teradata data warehouse. • WalMart allows more than 3,500 suppliers, to access data on their products and perform data analyses. These suppliers use this data to identify customer buying patterns at the store display level. They use this information to manage local store inventory and identify new merchandising opportunities.
Examples of DM in Marketing in web sites • Data.Mining.Fox can help in marketing to predict the purchase probability of customers for a specific product. • Easy.Data.Mining can add value by being profitably applied to marketing challenges.
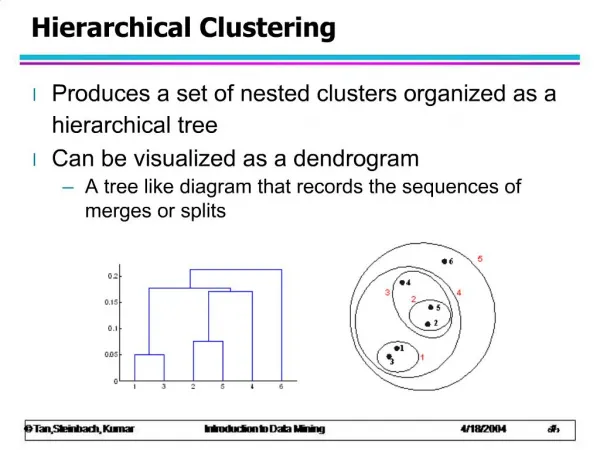
Four types of relationships in DM • Classes • Clusters • Associations • Sequential patterns
Classes • Stored data is used to locate data in predetermined groups. For example, a restaurant chain could mine customer purchase data to determine when customers visit and what they typically order. This information could be used to increase traffic by having daily specials.
Clusters • Data items are grouped according to logical relationships or consumer preferences. For example, data can be mined to identify market segments or consumer affinities.
Associations • Data can be mined to identify associations. The beer-diaper example is an example of associative mining
Sequential patterns • Data is mined to anticipate behaviour patterns and trends. • For example, an outdoor equipment retailer could predict the likelihood of a backpack being purchased based on a consumer's purchase of sleeping bags and hiking shoes.
Basic Characteristics of Data • The most common and important form of analysis is statistical analysis of data, if the data are metric and quantitative in nature. • The number of respondents in a quantitative Market Research projects can often be over a thousand, making a large bunch of data points within the data set.
Mean After the data collected is cleaned for illogical responses and missing responses, a next good step would be tabulating and cross-tabulating respondents’ answers for all the questions. The cross-tabulating based on various segments such as demographic segments and other segments are useful in validating the responses and making sense of the data. Another useful statistic is the mean or the average. The average response for all the respondents or a cluster within the sample is good starting summary of the data. For example, if the market research project is about understanding the ability to pay for a certain product, then the average income of the respondents could be the very first statistic that would give a sense of the data. For instance, the average income of 1000 respondents is $1000. The average for various clusters can then be calculated. Cluster averages such as average income of male and female, average income of various age groups, average income of various geographic locations, etc. would give a better picture of the situation at hand.
Mode • The mode is the value that has the maximum number of occurrences. • The mode represents the highest peak of the normal distribution curve. This means that the normal distribution curve highest point will correspond to the value of mode. The mode is a good measure of location of data when the variable is categorical.
Median • The middle value of ranked data is the median. If the number of data points is even, the median is calculated by taking the average of the two middle values. • There are 50% of values larger than the median in the data set and 50% lesser than the median. Therefore, the median is the 50th percentile. The median is a good measure of central tendency for ordinal data.
Range • The range measures the spread of the data. The spread is the distance between or the gap between the largest and smallest value. • Thus, the range will be directly affected by outliers. Therefore, it is advisable to remove outliers by using box plot or any other tool before any statistical analysis.
Variance • The difference between the mean and an observed value is called as a deviation from the mean. • The variance is the average of the square of the deviations from the mean for all the values. • The variance is always a positive figure. If the data points are clustered closely around the mean, the variance is small. If the data points are scattered dispersedly around the mean, the variance is large
Standard Deviation • The standard deviation is the square root of variance.
Histogram The histogram is a summary graph showing a count of the data points falling in various ranges. The effect is a rough approximation of the frequency distribution of the data.
Histogram • The groups of data are called classes, and in the context of a histogram they are known as bins, because one can think of them as containers that accumulate data and "fill up" at a rate equal to the frequency of that data class. • The histogram of the frequency distribution can be converted to a probability distribution by dividing the tally in each group by the total number of data points to give the relative frequency.
Quiz about Data Mining • http://www.sagepub.com/clow/study/chapters/03/Quiz/Quiz.swf