Download
1 / 121
1.3k likes | 1.54k Vues
Tutorials Monday, September 7, 2009: Learning from Multi-label Data G. Tsoumakas (Aristotle University of Thessaloniki), M. L. Zhang (Hohai University), Z.-H. Zhou (Nanjing University) Language and Document Analysis: Motivating Latent Variable Models

E N D
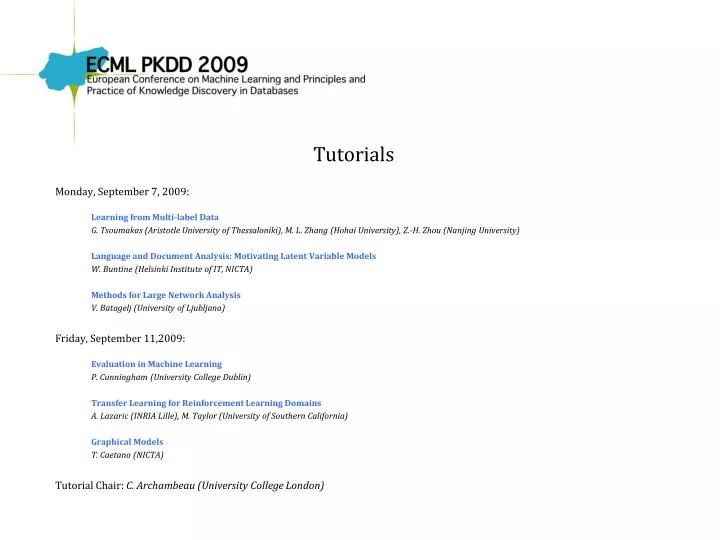
Tutorials Monday, September 7, 2009: Learning from Multi-label Data G. Tsoumakas (Aristotle University of Thessaloniki), M. L. Zhang (Hohai University), Z.-H. Zhou (Nanjing University) Language and Document Analysis: Motivating Latent Variable Models W. Buntine (Helsinki Institute of IT, NICTA) Methods for Large Network Analysis V. Batagelj (University of Ljubljana) Friday, September 11,2009: Evaluation in Machine Learning P. Cunningham (University College Dublin) Transfer Learning for Reinforcement Learning Domains A. Lazaric (INRIA Lille), M. Taylor (University of Southern California) Graphical Models T. Caetano (NICTA) Tutorial Chair: C. Archambeau (University College London)
Tutorial at ECML/PKDD’09 Bled, Slovenia 7 September, 2009 Learning fromMulti-Label Data Grigorios Tsoumakas Department of Informatics, Aristotle University of Thessaloniki, Greece Min-Ling Zhang College of Computer and Information Engineering, Hohai University, China Zhi-Hua Zhou LAMDA Group, National Key Laboratory forNovel Software Technology, Nanjing University, China
The Larger Picture • Data with multiple target variables • What can the type of targets be? • Numerical • Ecological modeling and environmental applications • Industrial applications (automobile) • Categorical targets • Binary targets • Multi-class targets • Ordinal • Combination of types Multi-Label Data
Contents • Introduction • What is multi-label learning • Applications and datasets • Evaluation in multi-label learning (various multi-label metrics) • Overview of existing multi-label learning techniques • Problem transformation learning methods • Algorithm adaptation methods • Advanced topics • Learning in the presence of Label Structure • Multi-instance multi-label learning • The Mulan open-source software
Settings: d-dimensional input space (numerical or nominal features) output (label) space of q labels Inputs: S : multi-label training set with m examples where is the d-dimensional instance Outputs: is the set of labels associated with h : a multi-label predictor where given an instance , f : a ranking predictor or labels in are ordered according to What is Multi-Label Learning
Multi-Label Learning Tasks • Setting • Set of labels L={λ1, λ2, λ3, λ4, λ5}, new instance x • Classification • Produce a bipartition of the set of labels into a relevant and an irrelevant set • Px: {λ1, λ4}, Nx:{λ2, λ3, λ5}
Multi-Label Learning Tasks • Setting • Set of labels L={λ1, λ2, λ3, λ4, λ5}, new instance x • Ranking • Produce a ranking of all labels according to relevance to the given instance • Let r(λ) denote the rank of label λ • r(λ3) < r(λ2) < r(λ4) < r(λ5) < r(λ1) • It can also be learned from data containing • Single labels, total rankings of labels and pairwise preferences over the set of labels
Multi-Label Learning Tasks • Setting • Set of labels L={λ1, λ2, λ3, λ4, λ5}, new instance x • Classification and Ranking • Produce both a bipartition and a ranking of all labels • These should be consistent:
Applications and Datasets • (Semi) automated annotation of large object collections for information retrieval • Text/web, image, video, audio, biology • Tag suggestion in Web 2.0 systems • Query categorization • Drug discovery • Direct marketing • Medical diagnosis
Text • News • An article concerning the Antikythera Mechanism can be categorized to • Science/Technology, History/Culture • Reuters Collection Version I [Lewis et al., 2004] • 804414 newswire stories indexed by Reuters Ltd • 103 topics organized in a hierarchy, 2.6 on average • 350 industries (2-level hierarchy post-produced) • 296 geographic codes
Text • Research articles • A research paper on an ensemble method for multi-label classification can be assigned to the areas • Ensemble methods, Structured output prediction • Collections • OHSUMED [Hersh et al., 1994] • Medical Subject Headings (MeSH) ontology • ACM-DL [Veloso et al., 2007] • ACM Computing Classification System (1st:11, 2nd:81 labels) • 81251 Digital Library articles
Text • EUR-Lex collection [Loza Mencia and Furnkranz, 2008] • 19596 legal documents of the European Union (EU) • Hierarchy of 3993 EUROVOC labels, 5.4 on average • EUROVOC is a multilingual thesaurus for EU documents • 201 subject matters, 2.2 on average • 412 directory codes, 1.3 on average • WIPO-alpha collection [Fall et al., 2003] • World Intellectual Patents Organization (WIPO) • 75000 patents • 4 level hierarchy of ~5000 categories
Text • Aviation safety reports (tmc2007) • Competition of SIAM Text Mining 2007 Workshop • 28596 NASA aviation safety reports in free text form • 22 problem types that appear during flights • 2.2 annotations on average • Free clinical text in radiology reports (medical) • Computational Medicine Center's 2007 Medical NLP Challenge [Pestian et al., 2007] • 978 reports, 45 labels, 1.3 labels on average
Web • Email • Enron dataset • UC Berkeley Enron Email Analysis Project • 1702 examples, 53 labels, 3.4 on average • 2 level hierarchy • Web pages • Hierarchical classification schemes • Open Directory Project • Yahoo! Directory [Ueda & Saito, 2003]
Image and Video • Application • Automated annotation for retrieval • Datasets • Scene[Boutell et al., 2004] • 2407 images, 6 labels, 1.1 on average • Mediamill[Snoek et al., 2006] • 85 hours of video data containing Arabic, Chinese, and US broadcast news sources, recorded during November 2004 • 43907 frames, 101 labels, 4.4 on average
Audio • Music and meta-data db of the HiFind company • 450000 categorized tracks since 1999 • 935 labels from 16 categories (340 genre labels) • Style, genre, musical setup, main instruments, variant, dynamics, tempo, era/epoch, metric, country, situation, mood, character, language, rhythm, popularity • Annotation • 25 annotators (musicians, music journalists) + supervisor • Software-based annotation takes 8 min per track on average • 37 annotation per track on average • A subset was used in [Pachet & Roy, 2009] • 32,978 tracks, 632 labels, 98 acoustic features
Audio • Categorization of music into emotions • Relevant works • [Li & Ogihara, 2003; 2006; Wieczorkowska et al., 2006] • Dataset emotions in [Trohidis et al., 2008] • 593 tracks, 6 labels, 1.9 on average • {happy, calm, sad, angry, quiet, amazed} • Some applications • Song selectionin mobile devices, music therapy • Music recommendation systems, TV and radio programs • Acoustic data [Streich & Buhmann, 2008] • Construction of hearing aid instruments • Labels: Noise, Speech, Music
Biology • Applications • Automated annotation of proteins with functions • Annotation hierarchies • The Functional Catalogue (FunCat) • A tree-shaped hierarchy of annotations for the functional description of proteins from several living organisms • The Gene Ontology (GO) • A directed acyclic graph of annotations for gene products
Biology • Datasets • Yeast[Elisseeff & Weston, 2002] • 2417 examples, 14 labels (1st FunCat level), 4.2 on average • Phenotype (yeast) [Clare & King, 2001] • 1461 examples, 4 FunCat levels • 12 yeast datasets [Clare, 2003; Vens et al., 2008] • Gene expression, homology, phenotype, secondary structure • FunCat, 6 levels, 492 labels, 8.8 on average • GO, 14 levels, 3997 labels, 35.0 on average
Benefits Richer descriptions of objects Folksonomy alignment Input Feature representation of objects (content) Challenges Huge number of tags Fast online predictions Related work [Song et al., 2008; Katakis et al., 2008] Tag Suggestion in Web 2.0 Systems
Query Categorization • Benefits • Integrate query-specific rich content from vertical search results (e.g. from a database) • Identify relevant sponsored ads • Place ads on categories vs. keywords • Example: Yahoo! [Tang et al., 2009] • 6433 categories organized in an 8-level taxonomy • 1.5 million manually labeled unique queries • Labels per query range from 1 to 26
Drug Discovery • MDL Drug Data Report v. 2001 • 119110 chemical structures of drugs • 701 biological activities (e.g. calcium channel blocker, neutral endopeptidase inhibitor, cardiotonic, diuretic) • Example: Hypertension [Kawai & Takahashi, 2009] • Two major activities of hypertension drugs • Angiotensin converting enzyme inhibitor • Neutral endopeptidase inhibitor • Compounds producing both these 2 specific activities found to be an effective new type of drug
Other • Direct marketing [Zhang et al., 2006] • A direct marketing company sends offers to clients for products of categories they potentially are interested • Historical data of clients and product categories that they got interested (multiple categories) • Data from Direct Marketing Association • 19 categories • Classification and Ranking • Send only relevant products, send top X products • Medical diagnosis • A patient may be suffering from multiple diseases at the same time, e.g. {obesity, hypertension}
For the i-th possible label: Contingency table for λi label λi actual output YES NO classifier output YES TPi FPi NO FNi TNi …… Evaluation Metrics: Label-Based Basic Strategy: Calculate classic single-label metric on each label independently, and then combine metric values over all labels through micro- or macro-averaging
micro-averaging: obtain final metric value by summing over corresponding decisions in each contingency table: E.g.: macro-averaging: obtain final metric value by averaging over the results of different labels: E.g.: Evaluation Metrics: Label-Based (Cont’) Combining single-label metrics: Label-based multi-label metrics are easy to compute, but ignore the relationships between different labels!
Five popular instance-based multi-label metrics [Schapire & Singer, MLJ00]: Given the learned predictor h(·) or f(·,·), and a test set (1) Hamming loss Evaluates how many times an instance-label pair is misclassified (2) One-error Evaluates how many times the top-ranked label is not in the set of proper labels of the instance Evaluation Metrics: Instance-Based Basic Strategy: Calculate metric value for each instance by addressing relationships among different class labels (especially the ranking quality), and then return the mean value over all instances
returns the rank of y derived from (4) Ranking loss Evaluates the average fraction of label pairs that are mis-ordered for the instance (5) Average precision Evaluates the average fraction of labels ranked above a proper label which are also proper labels Evaluation Metrics: Instance-Based (Cont’) (3) Coverage Evaluates how many steps are needed, on average, to go down the label list to cover all proper labels of the instance
Contents • Introduction • What is multi-label learning • Applications and datasets • Evaluation in multi-label learning (various multi-label metrics) • Overview of existing multi-label learning techniques • Problem transformation learning methods • Algorithm adaptation methods • Advanced topics • Learning in the presence of Label Structure • Multi-instance multi-label learning • The Mulan open-source software
A Categorization Of Methods • Problem transformation methods • They transform the learning task into one or more single-label classification tasks • They are algorithm independent • Some could be used for feature selection as well • Algorithm adaptation methods • They extend specific learning algorithms in order to handle multi-label data directly • Boosting, generative (Bayesian), SVM, decision tree, neural network, lazy, ……
Problem Transformation Methods • Binary relevance • Ranking via single-label learning • Pairwise methods • Ranking by pairwise comparison • Calibrated label ranking • Methods that combine labels • Label Powerset, Pruned Sets • Ensemble methods • RAkEL, EPS • From ranking to classification
Example Multi-Label Dataset • L = {λ1, λ2, λ3, λ4}
How it works Learns one binary classifier for each label Outputs the union of their predictions Can do ranking if classifier outputs scores Limitation Does not consider label relationships Complexity O(qm) Binary Relevance (BR)
Ranking via Single-Label Learning • Basic concept • Transform the multi-label dataset to a single-label multi-class dataset with the labels as classes • A single-label classifier that outputs a score (e.g. probability) for each class can produce a ranking • Transformations [Boutell et al, 2004; Chen et al., 2007] • ignore • select-max, select-min, select-random • copy, copy-weight (entropy)
Ignore • Simply ignore all multi-label examples • Major information loss!
Select one of the labels Most frequent label (Max) Less frequent label (Min) Random selection Information loss! Select Min, Max and Random Max Min Random
Copy and Copy-Weight (Entropy) • Replace each example with examples (xi,λj) , one for each • Copy-weight requires learners that take the weights of examples into account • Weights examples by • No information loss • Increased examples O(mc)
Ranking by Pairwise Comparison • How it works [Hullermeier et al., 2008] • It learns q(q-1)/2 binary models, one for each pair of labels • Each model is trained based on examples that are annotated by at least one of the labels, but not both • Itlearns to separatethe corresponding labels • Given a new instance, all models are invoked and a ranking is obtained by counting the votes received by each label
Ranking by Pairwise Comparison new instance x' λ3 λ1 λ2 λ4 Ranking:
Ranking by Pairwise Comparison • Time complexity • Training: O(mqc) • Testing: Needs to query q2 binary models • Space complexity • Needs to maintain q2 binary models in memory • Pairwise decision tree/rule learning models might be simpler than one-vs-rest • Perceptrons/SVMs store a constant number of parameters
Calibrated Label Ranking • How it works [Furnkranz et al., 2008] • Extends ranking by pairwise comparison by introducing an additional virtual label λV, with the purpose of separating positive from negative labels • Pairwise models that include the virtual label correspond to the models of binary relevance • All examples are used • When a label is true, the virtual label is considered false • When a label is false, the virtual label is considered true • The final ranking includes the virtual label, which acts as the split point between positive/negative labels
Ranking by Pairwise Comparison new instance x' λ1 λV λ2 λ4 λ3 Ranking:
Ranking by Pairwise Comparison • Benefits • Improved ranking performance • Classification and ranking (consistent) • Limitations • Space complexity (as in RPC) • A solution for perceptrons [Loza Mencıa & Furnkranz, 2008] • Querying q2 + q models at runtime • QWeighted algorithm [Loza Mencia et al., 2009]
Label Powerset (LP) • How it works • Each different set of labels in a multi-label training set becomes a different class in a new single-label classification task • Given a new instance, the single-label classifier of LP outputs the most probable class (a set of labels)
Label Powerset (LP) • Ranking • It is possible if a classifier that outputs scores (e.g. probabilities) is used [Read, 2008] • Are the bipartition and ranking always consistent?
Label Powerset (LP) • Complexity • Depends on the number of distinct labelsets that exist in the training set • It is upperbounded by min(m,2q) • It is usually much smaller, but still larger than q • Limitations • High complexity • Limited training examples for many classes • Cannot predict unseen labelsets
Pruned Sets • How it works [Read, 2008; Read et al., 2008] • Follows the transformation of LP, but it also … • Prunes examples whose labelsets (classes) occur less times than a small user-defined thresholdp(e.g. 2 or 3) • Deals with the large number of infrequent classes • Re-introduces pruned examples along with subsets of their labelsets that do exist more times than p • Strategy A: Rank subsets by size/number of examples and keep the top b of those • Strategy B: Keep all subsets of size greater than b



















