Download
1 / 1
10 likes | 123 Vues
Where in the World? Human and Computer Geolocation of Images James Hays and Alexei A. Efros, Carnegie Mellon University. Human Geolocation. im2gps. Query Top Matches Geolocation Estimate.

E N D
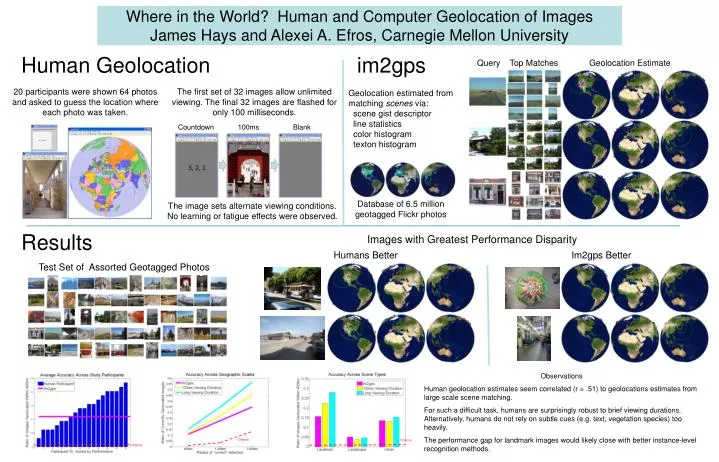
Where in the World? Human and Computer Geolocation of Images James Hays and Alexei A. Efros, Carnegie Mellon University Human Geolocation im2gps Query Top Matches Geolocation Estimate 20 participants were shown 64 photos and asked to guess the location where each photo was taken. The first set of 32 images allow unlimited viewing. The final 32 images are flashed for only 100 milliseconds. Geolocation estimated from matching scenes via: scene gist descriptor line statistics color histogram texton histogram Countdown 100ms Blank Database of 6.5 million geotagged Flickr photos The image sets alternate viewing conditions. No learning or fatigue effects were observed. Results Images with Greatest Performance Disparity Humans Better Im2gps Better Test Set of Assorted Geotagged Photos Observations Human geolocation estimates seem correlated (r = .51) to geolocations estimates from large scale scene matching. For such a difficult task, humans are surprisingly robust to brief viewing durations. Alternatively, humans do not rely on subtle cues (e.g. text, vegetation species) too heavily. The performance gap for landmark images would likely close with better instance-level recognition methods. Chance Chance Chance






















