Download
1 / 1
10 likes | 92 Vues
Mobot-Learn: Aprendizado por Reforço utilizando políticas parcias e macroestados na navegação de robôs móveis. Experimentos e Resultados. Introdução. Fluxo Compulsório. Macroestados.

E N D
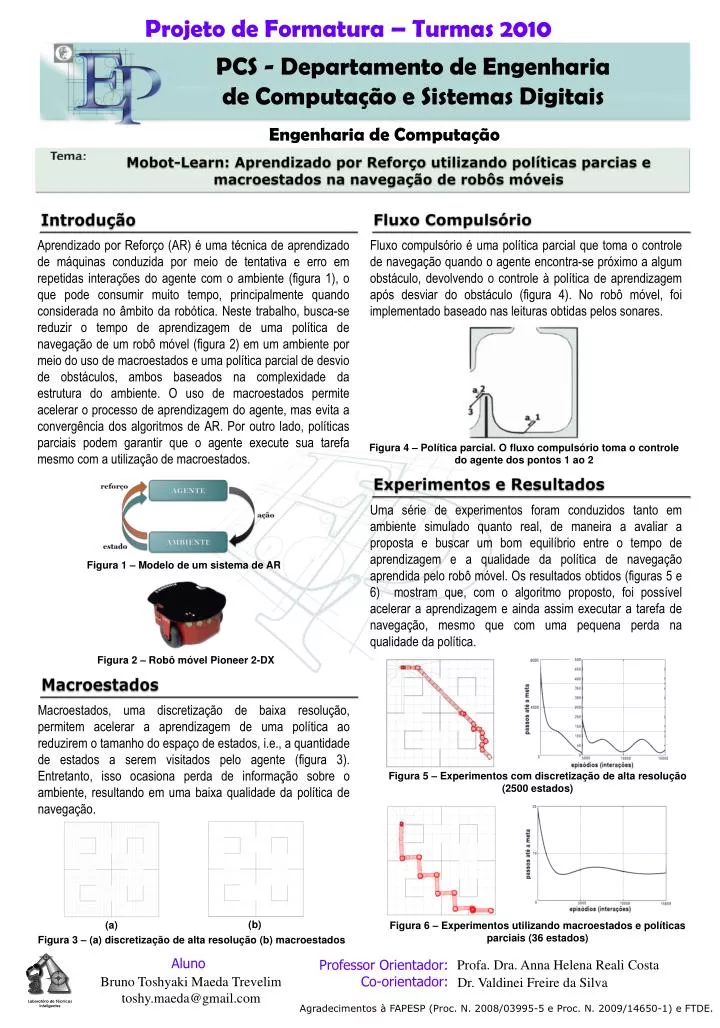
Mobot-Learn: Aprendizado por Reforço utilizando políticas parcias e macroestados na navegação de robôs móveis Experimentos e Resultados Introdução Fluxo Compulsório Macroestados Uma série de experimentos foram conduzidos tanto em ambiente simulado quanto real, de maneira a avaliar a proposta e buscar um bom equilíbrio entre o tempo de aprendizagem e a qualidade da política de navegação aprendida pelo robô móvel. Os resultados obtidos (figuras 5 e 6) mostram que, com o algoritmo proposto, foi possível acelerar a aprendizagem e ainda assim executar a tarefa de navegação, mesmo que com uma pequena perda na qualidade da política. Macroestados, uma discretização de baixa resolução, permitem acelerar a aprendizagem de uma política ao reduzirem o tamanho do espaço de estados, i.e., a quantidade de estados a serem visitados pelo agente (figura 3). Entretanto, isso ocasiona perda de informação sobre o ambiente, resultando em uma baixa qualidade da política de navegação. Fluxo compulsório é uma política parcial que toma o controle de navegação quando o agente encontra-se próximo a algum obstáculo, devolvendo o controle à política de aprendizagem após desviar do obstáculo (figura 4). No robô móvel, foi implementado baseado nas leituras obtidas pelos sonares. Aprendizado por Reforço (AR) é uma técnica de aprendizado de máquinas conduzida por meio de tentativa e erro em repetidas interações do agente com o ambiente (figura 1), o que pode consumir muito tempo, principalmente quando considerada no âmbito da robótica. Neste trabalho, busca-se reduzir o tempo de aprendizagem de uma política de navegação de um robô móvel (figura 2) em um ambiente por meio do uso de macroestados e uma política parcial de desvio de obstáculos, ambos baseados na complexidade da estrutura do ambiente. O uso de macroestados permite acelerar o processo de aprendizagem do agente, mas evita a convergência dos algoritmos de AR. Por outro lado, políticas parciais podem garantir que o agente execute sua tarefa mesmo com a utilização de macroestados. Figura 4 – Política parcial. O fluxo compulsório toma o controle do agente dos pontos 1 ao 2 Figura 2 – Robô móvel Pioneer 2-DX Figura 1 – Modelo de um sistema de AR Figura 5 – Experimentos com discretização de alta resolução (2500 estados) (b) (a) Figura 3 – (a) discretização de alta resolução (b) macroestados Figura 6 – Experimentos utilizando macroestados e políticas parciais (36 estados) Profa. Dra. Anna Helena Reali Costa Dr. Valdinei Freire da Silva Agradecimentos à FAPESP (Proc. N. 2008/03995-5 e Proc. N.2009/14650-1) e FTDE.






















