Download
1 / 5
50 likes | 56 Vues
Given todayu2019s vast amounts of data and user queries, making e-commerce search engines more efficient is an extremely challenging problem. Unbxd works relentlessly to help e-commerce websites optimize their search engines. If you have any questions or want to understand how you can leverage entity extraction to deliver more relevant search results then read this presentation now!

E N D
Unbxd Advancements In Entity Extraction
Given today’s vast amounts of data and user queries, making e-commerce search engines more efficient is an extremely challenging problem. In part 1 of this blog, I wrote about why e-commerce businesses must explore entity extraction as a way to increase the relevance of their search results. This follow-up blog goes into how e-commerce companies can put entity extraction and machine learning (ML) into practice, and some advancements that Unbxd brought to this area in the last year. What is entity extraction? Here’s a primer: consider the sentence, “Cindy bought two Levi’s jeans last week.” Using this input, we can highlight the names of entities: Cindy [person] bought [action] two [quantity] Levi’s [brand] jeans [category] last week [time]. Another example: take the query “Black leather jacket,” from which color_name, pattern, and category_type are the “named entities” recognized. We also know that black, leather, and jacket are the values of these entities. Today, training and building ML model(s) entails massive challenges: 1. Challenges with getting data 2. Generating high quality labeled data 3. Optimizing algorithms and architecture to deploy ML models and deliver business results Challenges with getting data Data is the backbone of named-entity recognition or NER. Over several years, Unbxd has aggregated massive amounts of e-commerce clickstream and user behavior data. Our commitment to innovation has started with how we have built the Unbxd data layer: we crawl open source content like Wikipedia, conceptNet, and social media, and we combine it with a special data set built from scanning 100K sites. (This data set is so large that we call it the world catalog!)Generating high quality labeled data NER models will require user behavior data and catalog data to generate high quality labeled data that will train NER- based machine learning models, which have the capability of understanding entities in a search query. This understanding can be combined with existing implementations and provide a richer experience to shoppers. Obviously, the more relevant data that we provide, the better the algorithms become. So, the first step was to generate high quality labeled data from historical user behavior data and product catalogs. But collecting, labeling, and maintaining huge amounts of historical data on which entity extraction algorithms can be trained is one of the biggest challenges for e-commerce enterprises. While we were using a bunch of models to run and optimize entity extraction modules in the past, our labeled data set generation part was largely manual. There were arguments on quality and whether algorithms can provide as good a labeled data set as a human-labeled data set. In 2018, we introduced intelligent tagging models to generate labeled data for different domains like fashion and accessories, home and living, electronics, and mass merchants. The results have suggested 94% accuracy for the algorithm-driven models as compared to 97% for human-labeled models. We have seen minor degradation in quality, however; these models have set us on the path to achieving truly scalable entity extraction models – both from a training and testing perspective. Further, we see continuous improvement in terms of accuracy for algorithm-driven models and believe that soon these models will overshoot the accuracy of human-driven models. As of now, for generating labeled data we combine historical clickstream data, product
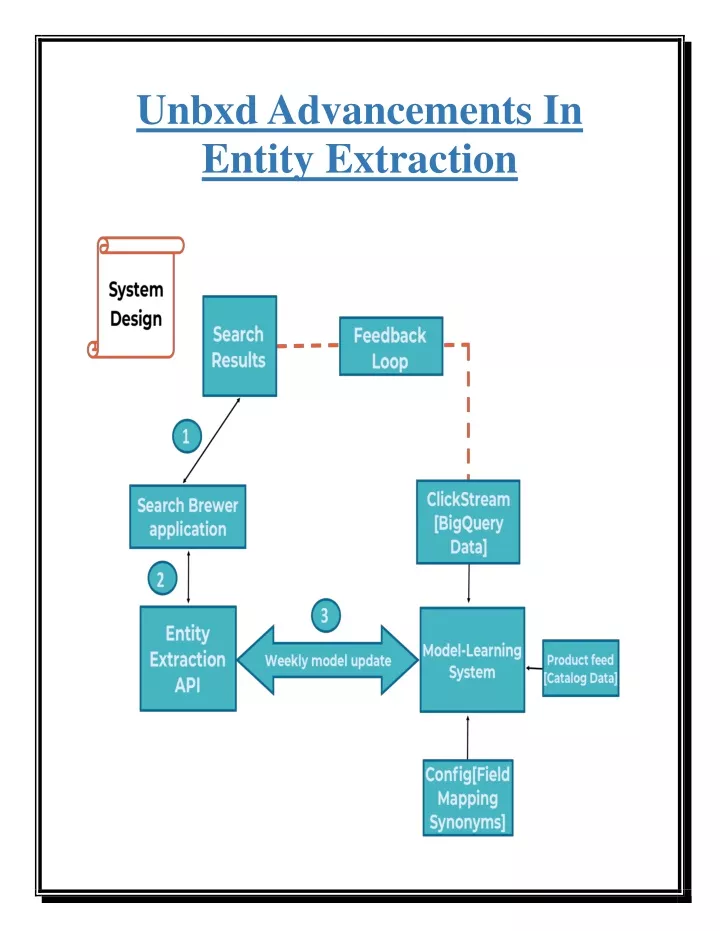
catalog data at the category level, and a bunch of derived parameters along with site-level configuration data to generate a statistical model which predicts labels for search queries with a certain confidence. We discard the entities that have confidence below a certain threshold and take high confidence tokens and search queries from here. This labeled data will contain all “named entities” or concepts that you need to extract from the search query and the possible values of these entities, as per historical search queries and product descriptions. Once we have labeled the data set, the NER based machine learning models are trained on this data set. Optimizing algorithms and architecture to deploy ML models and deliver business results Creating machine models that get a smarter understanding of queries is one thing, but making those models available for delivering more relevant search results is another. I’m happy to write about Unbxd’s contributions to this in 2018. We built our system to consist of two major modules: one of them is the Entity Extraction API that serves the extracted “entities” from a search query to the front end, while the Model-learning System evolves the learned model using clickstream data, derived parameters, and product catalog. The two components are 1. Entity Extraction API: The Entity Extraction API takes the query and client key as input and will return entities for that search query with a certain confidence. Each API host talks to the storage layer to fetch the latest machine learning model, as they continuously evolve 2. Model-Learning System: This module uses the pre-built labeled datasets and trains them for general use-case. Output model is made available via the API. Recall and PrecisionRecall is the ratio of “the number of relevant products retrieved” to “the number of relevant products in the catalog.” Precision is the ratio of “the number of relevant products retrieved” to “the total number of products retrieved.” Essentially, high precision implies that an algorithm returned a higher number of relevant results, while high recall means that the model returned most of the relevant results. For the search query “blue jeans,” if the catalog has 100 relevant products and the search retrieves 160 products out of which 80 are relevant, then recall is 80/100 = 0.8. Precision in this scenario is 80/160 = 0.5. Instead of Recall and Precision, most of the models in Information Retrieval domain are measured by a harmonic mean of Recall and Precision, denoted by F1 score. NER Models Our goal in 2018 was to use more data points from the product catalog, search queries, and click-stream data to generate NER tags for the historical queries of a client from a specific domain. We then want to generalize this understanding via a machine-learned model, so that given new search queries, the model can make accurate tag prediction for various phrases in the query. Simply put, NER models solve for a sequence-to-sequence labeling problem, where given training data in the form of input sequence [Xa, Xb,..Xn] and its corresponding labels [Y1, Y2, ..Yn] we learn a model such that for a new input [Xx, Xy,…Xn], the model outputs the predicted labels [Yx, Yy, ..Yn]. A unique challenge in e-commerce is that the search queries are pretty short and less structured than in web documents. (This is a major reason why out-of-the-box NLP solutions are available for web and document search, but not e-commerce.) As noted above and as a general case, we wanted to use clickstream and/or the catalog to generate the
training data. We tried multiple approaches to generate the model, and here are some models that we found competent with NER: 1. SpaCy: This NER model uses transition learning model coupled with convoluted neural networks (CNN). In this model, the input query passes through multiple states, where a decision is made at each state to generate the label for that state. As it is a neural network based solution, the model takes a significant time to train, and the performance of the model was lower than other approaches. The python based free and open source NLP library SpaCy is used for this model. So for a sample query, “Lenovo mouse,” SpaCy would predict “Lenovo” as the “brand” or “company” and “mouse” as the “product.” 2. Stanford coreNLP NER tagger: This Java implementation of NER uses Conditional Random Fields (CRF), and thus it is also known as CRFClassifier. The model maximizes the conditional probability of tagging the entire query as per the training data. Since the CRF models try to maximize conditional tagging, the recall is less unless we have huge datasets. 3. Stanford MaxEnt POS Tagger: This model uses a maximum entropy-based tagger and is similar to the CRF. Though this model tags the query more liberally (hence the maximum entropy), causing some biased tagging, it has high recall. Some other models that we have tested are Hidden Markov model and SVM based models. Apart from experimenting with different models, we also assess the various implementations of the model and chose the one which gives the best result. For example, with the Stanford MaxEnt Tagger, Unbxd chose Apache OpenNLP library over Stanford NLP library due to its better developer-friendly interface. NER model A/B testing results for few of our customers:Initial results have shown a significant conversion uplift of around 4.83%
(2.69% to 2.82%) over our current models. An important point: As Unbxd continuously tests various NER models to find the best ones and optimize them for specific domains, we have found that a one-size-fits-all approach does not work. Domains are different, and what works in fashion may not work for electronics, so experimentation is key to find out what works best for our customers. Unbxd works relentlessly to help e-commerce websites optimize their search engines. If you have any questions or want to understand how you can leverage entity extraction to deliver more relevant search results, please reach out to me at product@unbxd.com. Source: https://unbxd.com/blog/unbxd-advancements-entity-extraction-2018/