Download

1 / 31
310 likes | 443 Vues
Understanding the TigerSHARC ALU pipeline. Determining the speed of one stage of IIR filter – Part 3 Understanding the memory pipeline issues. Understanding the TigerSHARC ALU pipeline. TigerSHARC has many pipelines Review of the COMPUTE pipeline works

E N D
Understanding the TigerSHARC ALU pipeline Determining the speed of one stage of IIR filter – Part 3Understanding the memory pipeline issues
Understanding the TigerSHARC ALU pipeline • TigerSHARC has many pipelines • Review of the COMPUTE pipeline works • Interaction of memory (data) operations with COMPUTE operations • What we want to be able to do? • The problems we are expecting to have to solve • Using the pipeline viewer to see what really happens • Changing code practices to get better performance • Specialized C++ compiler options and #pragmas (Will be covered by individual student presentation) • Optimized assembly code and optimized C++ Speed IIR -- stage 3, M. Smith, ECE, University of Calgary, Canada
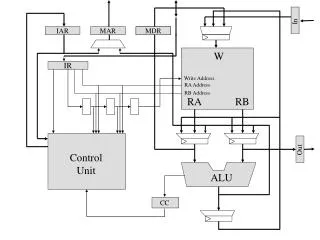
Processor Architecture • 3 128-bitdata busses • 2 Integer ALU • 2 ComputationalBlocks • ALU (Float and integer) • SHIFTER • MULTIPLIER • COMMUNICATIONSCLU Speed IIR -- stage 3, M. Smith, ECE, University of Calgary, Canada
S0 S1 S2 Simple ExampleIIR -- Biquad SOS1S2 • For (Stages = 0 to 3) Do • S0 = Xin * H5 + S2 * H3 + S1 * H4 • Yout = S0 * H0 + S1 * H1 + S2 * H2 • S2 = S1 • S1 = S0 Speed IIR -- stage 3, M. Smith, ECE, University of Calgary, Canada
PIPELINE STAGESSee page 8-34 of Processor manual • 10 pipeline stages, but may be completely desynchronized (happen semi-independently) • Instruction fetch -- F1, F2, F3 and F4 • Integer ALU – PreDecode, Decode, Integer, Access • Compute Block – EX1 and EX2 Speed IIR -- stage 3, M. Smith, ECE, University of Calgary, Canada
Instruction 0x17e XFR8 = R8 + R23 is STALLED (waiting) for 0x17d to complete XFR23 = R8 * R4 Bubble B means that the pipeline is doing “nothing”Meaning that the instruction shown is “place holder” (garbage) Speed IIR -- stage 3, M. Smith, ECE, University of Calgary, Canada
Code withstalls shown • 8 code lines • 5 expected stalls • Expect 13 cyclesto completeif theory is correct Speed IIR -- stage 3, M. Smith, ECE, University of Calgary, Canada
Analysis approach IS correct Code takes same time whether our “SHOW-STALL instructions are there or not Speed IIR -- stage 3, M. Smith, ECE, University of Calgary, Canada
Process for coding for improved speed – code re-organization • Make a copy of the code so can test iirASM( ) and iirASM_Optimized( ) to make sure get correct result • Make a table of code showing ALU resource usage (paper, EXCEL, Project (Gantt chart) ) • Identify data dependencies • KEY –Make all “temp operations” use different register • Move instructions “forward” to fill delay slots, BUT don’t break data dependencies Speed IIR -- stage 3, M. Smith, ECE, University of Calgary, Canada
Show resource usage and data dependencies Speed IIR -- stage 3, M. Smith, ECE, University of Calgary, Canada
Change all temporary registers to use different register namesThen check code produces correct answer Speed IIR -- stage 3, M. Smith, ECE, University of Calgary, Canada
Move instructions forward, without breaking data dependencies What appears possible! DO one thing at a time and then check that code still works Speed IIR -- stage 3, M. Smith, ECE, University of Calgary, Canada
CHECK THE PIPELINE AFTER TESTING There are many more COMPUTE pipeline improvements possible. However, let’s not spend too much time here as we are only looking at half of the problem The coefficients are unlikely to be hard-coded, and the state variables can’t be if we are to call IIR( ) in a loop to be able to filter a series of values. Speed IIR -- stage 3, M. Smith, ECE, University of Calgary, Canada
Expect to take 8 cycles to execute This is not real lifeWe must use IIR( ) in a loop in order to be able to filter a series of values. Also IIR( ) will involve multiple stages Means bring in (read) filter coefficients from memory. Means bring in (read) state values from memory and store (write)the changed state values at theend of the function. Speed IIR -- stage 3, M. Smith, ECE, University of Calgary, Canada
Rewrite Tests so that IIR( ) function can take parameters Lets make things real bypassing in state variablesthrough an “overloaded”C++ function Speed IIR -- stage 3, M. Smith, ECE, University of Calgary, Canada
Rewrite the “C++ code” I leave the old “fixed” values in until I can get the code to work. Proved useful this time as the code failed Why did it fail to return the correct value? Speed IIR -- stage 3, M. Smith, ECE, University of Calgary, Canada
Explore design issues – 1What do we expect to have to worry about? XR0 = 0.0; // Set Fsum = 0; XR1 = [J1 += 1]; // Fetch a coefficient from memory XFR2 = R1 * R4; // Multiply by Xinput (XR4) XFR0 = R0 + R2; // Add to sum XR3 = [J1 += 1]; // Fetch a coefficient from memory XR5 = [J2 += 1]; // Fetch a state value from memory XFR5 = R3 * R5; // Multiply coeff and state XFR0 = R0 + R5; // Perform a sum XR5 = XR12; // Update a state variable (dummy) XR12 = XR13 // Update a state variable (dummy) [J3 += 1] = XR12; // Store state variable to memory [J3 += 1] = XR5; // Store state variable to memory Speed IIR -- stage 3, M. Smith, ECE, University of Calgary, Canada
Explore design issues – 2COMPUTE stalls expected (possible) XR0 = 0.0; // Set Fsum = 0; XR1 = [J1 += 1]; // Fetch a coefficient from memory XFR2 = R1 * R4; // Multiply by Xinput (XR4) XFR0 = R0 + R2; // Add to sum XR3 = [J1 += 1]; // Fetch a coefficient from memory XR5 = [J2 += 1]; // Fetch a state value from memory XFR5= R3 * R5; // Multiply coeff and state XFR0 = R0 + R5; // Perform a sum XR5 = XR12; // Update a state variable (dummy) XR12 = XR13 // Update a state variable (dummy) [J3 += 1] = XR12; // Store state variable to memory [J3 += 1] = XR5; // Store state variable to memory Speed IIR -- stage 3, M. Smith, ECE, University of Calgary, Canada
Explore design issues – 3Probable memory stalls expected XR0 = 0.0; // Set Fsum = 0; XR1 = [J1 += 1]; // Fetch a coefficient from memory XFR2 = R1 * R4; // Multiply by Xinput (XR4) XFR0 = R0 + R2; // Add to sum XR3 = [J1 += 1]; // Fetch a coefficient from memory XR5 = [J2 += 1]; // Fetch a state value from memory XFR5 = R3 * R5; // Multiply coeff and state XFR0 = R0 + R5; // Perform a sum XR5 = XR12; // Update a state variable (dummy) XR12 = XR13 // Update a state variable (dummy) [J3 += 1] = XR12; // Store state variable to memory [J3 += 1] = XR5; // Store state variable to memory Speed IIR -- stage 3, M. Smith, ECE, University of Calgary, Canada
Memory pipeline issues expected from COMPUTE pipeline issues seen • When you start reading values from memory, how soon is the value fetched available for use within the COMPUTE? • When you have adjacent memory accesses (read or write) does the pipeline work better (higher speed) with [J1 += 1];; or with [J1 += J4];; where J4 has been set to 1? Speed IIR -- stage 3, M. Smith, ECE, University of Calgary, Canada
Write a quick test to explore the code example Speed IIR -- stage 3, M. Smith, ECE, University of Calgary, Canada
Code stub – part copy from optimized IIR code Speed IIR -- stage 3, M. Smith, ECE, University of Calgary, Canada
What is the MINIMUM number of ;; that must be added so that the code is valid TigerSHARC (multi-instruction) code? Speed IIR -- stage 3, M. Smith, ECE, University of Calgary, Canada
Code assembles, put when it runs, it crashes the tests Neat mid-term question Explain why this code crashed the processor (corrupted the processor) so that the remaining tests never completed? What are the minimum numbers of lines that must be deleted or added to make the tests run(did not say work) Speed IIR -- stage 3, M. Smith, ECE, University of Calgary, Canada
Switched to simulator#if 0 / #endif around unnecessary testsBreak point set at start of test code All ready seeing lots of pipeline issues Bigger picture on next slide Speed IIR -- stage 3, M. Smith, ECE, University of Calgary, Canada
Lots of instruction fetch issues PROBABLY from jumping into new routine and the instruction pipeline not filled by the start of this code Remove from this problem from the analysis by having 10 NOP;; at the beginning of this exploratory code WHY 10 NOPS and not 4? Speed IIR -- stage 3, M. Smith, ECE, University of Calgary, Canada
Looking much better. Speed IIR -- stage 3, M. Smith, ECE, University of Calgary, Canada
Pipeline issues – are they as we expected? • COMPUTE operations – 1 cycle delay expected if next instruction needs the result of previous instruction • When you start reading values from memory, how soon is the value fetched available for use within the COMPUTE? • When you have adjacent memory accesses (read or write) does the pipeline work better with [J1 += 1];; or with[J1 += J4];; where J4 has been set to 1? Speed IIR -- stage 3, M. Smith, ECE, University of Calgary, Canada
Pipeline performance seen Speed IIR -- stage 3, M. Smith, ECE, University of Calgary, Canada
Pipeline performance predicted When you start reading values from memory, 1 cycle delay for value fetched available for use within the COMPUTE COMPUTE operations – 1 cycle delay expected if next instruction needs the result of previous instruction When you have adjacent memory accesses (read or write) does the pipeline work better with [J1 += 1];; or with[J1 += J4];; where J4 has been set to 1? [J1 += 1];; works just fine here (no delay).Worry about [J1 += J4];; another day Speed IIR -- stage 3, M. Smith, ECE, University of Calgary, Canada
Understanding the TigerSHARC ALU pipeline • TigerSHARC has many pipelines • Review of the COMPUTE pipeline works • Interaction of memory (data) operations with COMPUTE operations • What we want to be able to do? • The problems we are expecting to have to solve • Using the pipeline viewer to see what really happens • Changing code practices to get better performance • Can predict compute and memory stalls • Have enough information to be able to predict performance for real IIR code involving memory fetches and stores • Almost enough information to tackle Lab. 2 with IIR Speed IIR -- stage 3, M. Smith, ECE, University of Calgary, Canada