Comparative Analysis of Zinc Peptidases in CATH Family
Explore the structural conservation, catalytic mechanisms, and oligomerization states of zinc peptidases in the CATH domain. Discover the diverse functions and substrate specificities of these proteins.

Comparative Analysis of Zinc Peptidases in CATH Family
E N D
Presentation Transcript
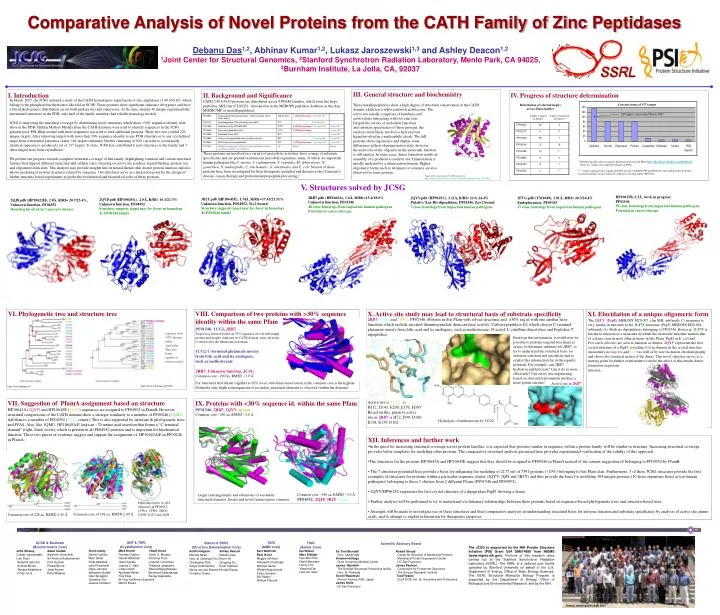
GNF & TSRI (Crystallomics Core) Scott Lesley Mark Knuth Heath Klock Dennis Carlton Thomas Clayton Kevin D. Murphy Marc Deller Daniel McMullan Christina Trout Polat Abdubek Claire Acosta Linda M. Columbus Julie Feuerhelm Joanna C. Hale Thamara Janaratne Hope Johnson Linda Okach Edward Nigoghossian Sebastian Sudek Aprilfawn White Bernhard Geierstanger Glen Spraggon Ylva Elias Sanjay Agarwalla Charlene Cho Bi-Ying Yeh Anna Grzechnik Jessica Canseco Mimmi Brown UCSD & Burnham (Bioinformatics Core) John Wooley Adam Godzik Lukasz Jaroszewski Slawomir Grzechnik Lian Duan Sri Krishna Subramanian Natasha Sefcovic Piotr Kozbial Andrew Morse Prasad Burra Tamara Astakhova Josie Alaoen Cindy Cook Dana Weekes TSRI (NMR Core) Kurt Wüthrich Reto Horst Maggie Johnson Amaranth Chatterjee Michael Geralt Wojtek Augustyniak Pedro Serrano Bill Pedrini William Placzek Stanford /SSRL (Structure Determination Core) Keith Hodgson Ashley Deacon Mitchell Miller Debanu Das Hsiu-Ju (Jessica) Chiu Kevin Jin Christopher RifeQingping Xu Silvya Oommachen Scott Talafuse Henry van den Bedem Ronald Reyes Christine Trame TSRI (Admin Core) Ian Wilson Marc Elsliger Gye Won Han David Marciano Henry Tien Xiaoping Dai Lisa van Veen Scientific Advisory Board Sir Tom Blundell Robert Stroud Univ. Cambridge Center for Structure of Membrane Proteins Homme Hellinga Membrane Protein Expression Center Duke University Medical CenterUC San Francisco James Naismith James Paulson The Scottish Structural Proteomics facilityConsortium for Functional Glycomics Univ. St. Andrews The Scripps Research Institute Soichi Wakatsuki Todd Yeates Photon Factory, KEK, Japan UCLA-DOE Inst. for Genomics and Proteomics James Wells UC San Francisco The JCSG is supported by the NIH Protein Structure Initiative (PSI) Grant U54 GM074898 from NIGMS (www.nigms.nih.gov). Portions of this research were carried out at the Stanford Synchrotron Radiation Laboratory (SSRL). The SSRL is a national user facility operated by Stanford University on behalf of the U.S. Department of Energy, Office of Basic Energy Sciences. The SSRL Structural Molecular Biology Program is supported by the Department of Energy, Office of Biological and Environmental Research, and by the NIH. Annual meeting with SAB 2007 Comparative Analysis of Novel Proteins from the CATH Family of Zinc Peptidases Debanu Das1,2, Abhinav Kumar1,2, Lukasz Jaroszewski1,3 and Ashley Deacon1,2 1Joint Center for Structural Genomics, 2Stanford Synchrotron Radiation Laboratory, Menlo Park, CA 94025, 3Burnham Institute, La Jolla, CA, 92037 III. General structure and biochemistry These metallopeptidases show a high degree of structural conservation in the CATH domain which has a α/β/α sandwich architecture. The active site usually comprises of histidines and carboxylates interacting with two zinc ions. Despite the variety of molecular functions and substrate specificities of these proteins, the catalysis most likely involves a hydroxyl ion ligand involved in a nucleophilic attack. The full proteins often oligomerize and display some differences in their oligomerization state, however, the exact role of the oligomer in the molecular functionis still unclear. In some cases, dimer formation results inassembly of a productive catalytic site. Dimerization is usually mediated by a dimerization domain. Higher oligomeric forms such as tetramers or octamers are also observed for some proteins. Figure of the representative CATH structure fro http://cathwww.biochem.ucl.ac.uk/cgi-bin/cath/GotoCath.pl?cath=3.40.630.10 I. Introduction II. Background and Significance CATH 3.40.630.10 proteins are distributed across 8 PFAM families, which form the large peptidase_MH clan (CL0035). Also known in the MEROPS peptidase database as the clan MH/MC/MF of metallopeptidases: These proteins are involved in a variety of proteolytic activities, have a range of substrate specificities and are present in numerous microbial organisms, many of which are important human pathogens like S. aureus, S. typhimurium, T. vaginalis, M. tuberculosis, N. gonorrhea, N. meningitidis, C. trachomatis, G. intestinalis, and E. coli. Several of these proteins have been investigated for their therapeutic potential and diseases roles (Canavan’s disease, cancer therapy and prohormone/propeptide processing). IV. Progress of structure determination In March 2007, the JCSG initiated a study of the CATH homologous superfamily of zinc peptidases (3.40.630.10), which belong to the phosphorylase/hydrolase-like fold in SCOP. These proteins show significant sequence divergence and have a broad phylogenetic distribution across both prokaryotes and eukaryotes. At the time, despite 40 unique experimentally determined structures in the PDB, only half of the family members had reliable homology models. JCSG is improving the structural coverage by determining novel structures which share <30% sequence identity with those in the PDB. Hidden Markov Models from the CATH database were used to identify sequences in the JCSG genome pool. PSI-Blast seeded with these sequences was used to find additional proteins. These two sets yielded 226 unique targets. After removing targets with more than 30% sequence identity to any PDB structure or to any crystallized target from a structural genomics center, 161 targets remained. Further clustering at 90% (in order to avoid nearly identical sequences), produced a set of 137 targets. To date, JCSG has contributed 6 new structures to the family and 7 other targets have been crystallized. We present our progress towards complete structural coverage of this family, highlighting common and variant structural features that support different molecular and cellular roles, focusing on active site residues, ligand binding, protein size and oligomerization state. This analysis may provide insights into structural themes that dictate protein function and also allows modeling of protein structures related by sequence. Our structures serve as a nucleation point for the design of further structure-based experiments to probe the biochemical and biomedical roles of these proteins. Current status of 137 targets Distribution of selected targetsacross Pfam families All targets selected in March 2007 Targets assigned in PfamA Targets unassigned in PfamA * * PFAM assigned based on sequence homology detected with FFAShttp://ffas.ljcrf.edu/ffas-cgi/cgi/ffas.pl There are 3 targets not assigned by PfamA or FFAS. ** 7 targets indicated show significant FFAS match to both PF04389 and PF05450, and could possibly be distant bacterial homologs to the exclusively eukaryotic nicastrin family (PF05450). V. Structures solved by JCSG HP10625B, 2.3Å, work in progress PF01546 50 close homologs from important human pathogens Potential in cancer therapy 2RB7.pdb (HP1666A), 1.6Å, R/Rfr=15.4/18.0% Unknown function, PF01546 48 close homologs from important human pathogens Potential in cancer therapy 2QYV.pdb (HP9625C), 2.11Å, R/Rf= 22.0, 24.4% Putative Xaa-His dipeptidase, PF01546, Zn+2 bound 7 close homologs from important human pathogens 2FVG.pdb (TM1049), 2.01Å, R/Rf= 20.3/24.4% Endoglucanase, PF05343 27 close homologs from important human pathogens 3B2Y.pdb (HP10645E), 1.74Å, R/Rfr=17.45/21.51% Unknown function, PF04952, Ni+2 bound Structure suggests target may be closer in homology To PF00246 family 2QVP.pdb (HP10645A), 2.0Å, R/Rf= 16.1/21.3% Unknown function, PF04952 Structure suggests target may be closer in homology To PF00246 family 2QJ8.pdb (HP10622H), 2.0Å, R/Rf= 20.7/25.4%, Unknown function, PF04952 Homolog involved in Canavan’s disease VI. Phylogenetic tree and structure tree VIII. Comparison of two proteins with >30% sequence identity within the same Pfam PF01546: 1CG2, 2RB7 Target was selected based on 30% sequence id over full length protein and despite similairty in CATH domain, more diversity is observed in the dimerization domain. 1CG2:C-terminal glutamate moiety from folic acid and its analogues, such as methotrexate 2RB7: Unknown function, JCSG Common core ~290 aa, RMSD ~3.0 Å X. Active site study may lead to structural basis of substrate specificity XI. Elucidation of a unique oligomeric form 2RB7 (cyan)and1CG2, PF01546. Proteins in this Pfam with solved structures and >30% seq id with one another have functions which include succinyl-diaminopimelate desuccinylase activity; Carboxypeptidase G2 which cleaves C-terminal glutamate moiety from folic acid and its analogues, such as methotrexate; N-acetyl-L-citrulline deacetylase and Peptidase T tripeptidase. The 2QYV (PepD, MEROPS M20.007, clan MH, subfamily C) monomer is very similar in structure to the 1LFW monomer (PepV, MEROPS M20.004, subfamily A). Both are dipeptidases belonging to PF01546. However, 1LFW is known to function as a monomer in which the molecular structure mimics that of a dimer seen in most other proteins in this Pfam. PepD in E. coli and Prevotella albensis are seen to function as dimers. 2QYV represents the first crystal structure of a PepD, revealing it to be dimeric in the crystal structure (monomers in magenta and gold) as well as by size exclusion chromatography and shows the structural nature of the dimer. This novel structure serves as a starting point for further experiments to probe the effect of this unique dimer formation on protein function. Sequence with >30% identity within a particular Pfam also cluster together in structure space Based on this information, it would now be possible to perform targeted biochemical assays to determine substrate for 2RB7, to try to understand the structural basis for substrate selection and specificity and to exploit this information for its therapeutic potential. For example, can 2RB7 hydrolyse methotrexate? Can it do so more efficiently? Can active site engineering based on structural information produce a more potent enzyme? Acknowledgements For structures that cluster together at 30% level, structural conservation in the common core is the highest, Generally only slight rearrangement of secondary structural elements is observed (within the domain). Active site in 2RB7 http://fatcat.burnham.org/POSA http://www.phlogeny.fr VII.Suggestion of PfamA assignment based on structure HP10645A (2QVP) and HP10645E (3B2Y) sequences are assigned to PF04952 in PfamB. However, structural comparisons of the CATH domain show a stronger similarity to a member of PF00246 (1QMU, left)than to a member of PF04952 (2QJ8, center). This is also supported by structure & phylogenetic trees and FFAS. Also, like 1QMU, HP10645A/E lacks an ~70 amino acid insertion that forms a “C-terminal domain” (right, black circle), which is present in all PF04952 proteins and is important for biochemical function. These two pieces of evidence suggest and support the assignment of HP10645A/E in PF00246 in PfamA. IX. Proteins with <30% sequence id. within the same Pfam PF01546: 2RB7, 2QYV (green) Common core ~250 aa, RMSD ~3.0 Å Active site is 1CG2 is H112, D141, E200, E176, H385 Based on this, putative active site in 2RB7 is H72, D99, D100, E138, E139, D162 Hydrolysis of methotrexate by 1CG2 • XII. Inferences and further work • In the quest for increasing structural coverage across protein families, it is expected that proteins similar in sequence within a protein family will be similar in structure. Increasing structural coverage provides better templates for modeling other proteins. The comparative structural analysis presented here provides experimental verification of the validity of this approach. • The structures for the proteins HP10645A and HP10645E suggest that they should be assigned to PF00246 in PfamA instead of the current suggestion of belonging to PF04952 by PfamB. • The 7 structures presented here provide a basis for enhancing the modeling of 2177 out of 7591 proteins (~29%) belonging to this Pfam clan. Furthermore, 3 of these JCSG structures provide the first examples of structures for proteins within a particular sequence cluster (2QYV, 2QJ8 and 3B2Y) and thus provide the basis for modeling 384 unique proteins (10 from organisms listed as top human pathogens) belonging to these 3 clusters from 2 different Pfams (PF01546 and PF04952). • 2QYV/HP9625C represents the first crystal structure of a dipeptidase PepD showing a dimer. • Further analysis will be performed to try to understand evolutionary relationships between these proteins based on sequence-based phylogenetic trees and structure-based trees. • Attempts will be made to investigate use of these structures and their comparative analyses in understanding structural basis for enzyme function and substrate specificities by analysis of active site amino acids, and to attempt to exploit information for therapeutic purposes. Common core ~190 aa, RMSD ~3.0 Å PF04952: 2QJ8, 3B2Y (cyan) Larger rearrangements and extensions of secondary structural elements. Inserts and novel features more common. Superimposition of all 6 structures in PF04952: 1YW4, 1YW6, 2BCO, 2G9D, 2GU2 and 2QJ8 Common core of 191 aa, RMSD 2.49 Å Common core of 226 aa, RMSD 2.45 Å