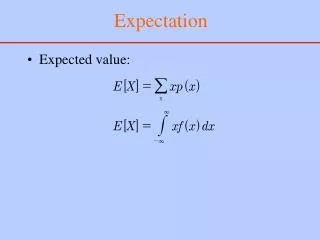CHAPTER 4 EXPECTATION
CHAPTER 4 EXPECTATION. CHAPTER 4. Overview. ● The Expectation of a R. V. ● Properties of Expectation ● Variance ● Moments ● The Mean and the Median ● Covariance and Correlation ● Conditional Expectation ● The Sample Mean. Section 4.1 The Expectation of a Random Variable.


CHAPTER 4 EXPECTATION
E N D
Presentation Transcript
CHAPTER 4 Overview ● The Expectation of a R. V. ● Properties of Expectation ● Variance ● Moments ● The Mean and the Median ● Covariance and Correlation ● Conditional Expectation ● The Sample Mean
Section 4.1 The Expectation of a Random Variable
Section Abstract • Although the distribution of a random variable is the ‘object’ that contains all the probabilistic information about the r.v., it is often times not easy to ‘see through it’, especially when the number of possible values is too big. • This is why it is preferable to have a few values that summarize the information given in a distribution. • The average or mean comes in handy because it gives an idea of where we expectthe values of X to be. The mean is the center of the distribution.
Expectation of a Discrete Distribution • First, if the number of possible values of X is finite (say N) and all these values are equally likely, then each one contributes the same to the average (i.e. 1/N), which givesμ ≡ E[X]:= 1 ∕ N (x1+x2+…+xN) = ∑i (1 ∕ N ) * xi • However, if the values of X are not equally likely, then every value must contribute to the average according to its weight • μ ≡ E[X]:= ∑i pi * xi
Example • The expectation of the r.v. distributed as in the table below is:E[X] = (-3)(0.4)+(-1)(0.1)+(3)(0.2)+(5)(0.3) = -1.2-0.1+0.6+1.5 = 0.8
Another Discrete Example: Binomial b(n,p) • A coin has a probability of 0.4 heads. The number X of heads in four tosses of this coin is b(4,0.4). The distribution is given below. • E[X] = 0* 0.1296 + 1* 0.3456 + 2* 0.3456 + 3* 0.1536 + 4* 0.0256 = 0.1600 • Note that 4*(0.4) = 0.16 • More generally, we can show that the expected value of b(n,p) is simply np
Expectation of a Continuous Distribution • For a continuous r.v. X, the mathematical expectation is defined as the integral: E[X] = -∞∫∞xf(x)dx whenever the latter exists. • Remark: the above integral and hence E[X] exist when -∞∫∞|x|f(x)dx < ∞. • E[X] has several names: mathematical expectation, expectation, mean and first moment.
Examples • Let X have the p.d.f. f(x) = 4x3 when x is in [0,1] and zero elsewhere.E[X] = 0∫14x4dx = 4x5 /5 0|1 = 4/5 • Let X be uniform ~ U[a,b].Then f(x) = 1/(b-a),E[X] = 0∫1x{1/(b-a)}dx = {1/2(b-a)}x20|1 = (b2-a2)/2(b-a) = (a+b)/2 • Inparticular if X ~U[0,1] then E[X] = 1/2
The Exponential Distribution • A random variable is said to be exponentially distributed with parameter λ if it has the p.d.f. f(x) = λ e-λx; x > 0. • E[X] = 0∫1x λ e-λxdx. • Using integration by parts we get that E[X] = 1/ λ. • Remark: the exponential distributions is used to model lifetimes of certain components of systems.
Expectation of a Function of a R.V. • Let Y = r(X) be a function of a random variable X whose distribution is known. • We want to find the expected value of Y. • The straightforward method is to find the distribution of Y, say g(y) and then E[Y] = -∞∫∞yg(y)dy if Y is continuousand E[Y] = ∑y yg(y) if Y is discrete. • Luckily we don’t need to find the distribution of Y: • E[Y] = E[r(X)] = -∞∫∞r(x)f(x)dx for continuous and E[Y] = E[Y] = ∑x r(x)f(x) for discrete X
Illustration for Previous Slide • X has the p.f. in the left table. • Y is defined to be X2 • Hence the p.f. of Y is given in the right table. • E[Y] calculated from its distribution is (1)(0.3)+(9)(0.7) = 3/10 + 63/10 = 66/10 = 6.6 • Calculated directly from the p.f. of X, E[Y] = (-3)2(0.4)+(-1)2(0.1)+(1)2(0.2)+(3)2(0.3) = 36/10 + 1/10 + 2/10 + 27/10 = 66/10 = 6.6
Higher Moments of a R.V. • Earlier, the name first moment was given to the expected value of a random variable with p.d.f. f(x). • The second moment of X is defined asE[X2] = -∞∫∞x2f(x)dx • In general, the nth moment of X is E[Xn] = -∞∫∞xnf(x)dx • Note that Xn is a function of X but by the result in the preceding slide we don’t need to find its density in order to calculate its expected value.
Expectation in the case of a Joint distribution • Let X and Y have the joint p.d.f. f(x,y). • The Expectation of X is E[X] = -∞∫∞xfX(x)dx; where fX(x) is the marginal p.d.f. of X. • But -∞∫∞xfX(x)dx = -∞∫∞x[-∞∫∞f(x,y)dy]dx • Hence E[X] = -∞∫∞-∞∫∞xf(x,y)dydx • Similarly E[Y] = -∞∫∞-∞∫∞yf(x,y)dydx • Morale: We do not need to get the marginal density of X and Y in order to get the expectations E[X] and E[Y]. We get them directly from their joint p.d.f.
Function of Two Random Variables • Let X and Y have the joint p.d.f. f(x,y). • Let Z = r(X,Y). The expectation of Z is:E[Z] = -∞∫∞ -∞∫∞ r(x,y)f(x,y)dxdy • Again, we do not need to calculate the p.d.f. of Z. • Remark: this and the previous slide report the continuous case, the discrete case is obtained similarly.
Examples • Let X and Y be distributed according to the uniform distribution in the rectangle 0 <X < 1; 0 < Y < 2.Find E[X], E[Y], E[X2], E[Y2], E[XY]. • Repeat (1) for a joint densityf(x,y) = 12y2 ; 0 ≤ y ≤ x ≤1 and zero elsewhere.
Section 4.2 Properties of Expectations
Section Abstract • We prove some theorems/properties of the mathematical expectation that are mainly inherited from the integral/summation nature of the expectation. • These properties simplify the derivation and calculation of some classes of functions (the results are gathered without proof in the next slide)
If Y = aX + b then E[Y] = aE[X] + b. • If there is a constant a such that Pr(X ≥ a) = 1 then E[X] ≥ a. • If there is a constant b such that Pr(X ≤ b) = 1 then E[X] ≤ b. • Sum of R.V.: If X1,X2,…,Xn are n random variables such that each expectation E[Xi] exists thenE[X1+X2+…+Xn] = E[X1] + …+ E[Xn] • Product of R.V.: If X1,X2,…,Xn are n independent random variables such that each expectation E[Xi] exists thenE[i=1ΠnXi] = i=1ΠnE[Xi]
Section 4.3 Variance
See Class Notes for definitions, properties and examples of the variance and standard deviation. MORE NOTES: • Variance of a uniform r.v. in an interval [a,b] is (a-b)2/12. • Variance of a binomial r.v. is np(1-p).
Loss Function • In Economics, we often need to approximate a variable by a value. This is done by minimizing an expected loss function: • Typically a loss function is of the form L(t)=(X-t)2 • which is the loss incurred by approximating X by the value t. • The strategy is to predict X by a value t0 that will minimize the expected value of the loss function:i.e. find t such that E[(X-t)2] is minimal. • It turns out that this minimizing value is μ itself, AND the minimum value is σ2. • When the loss function is |X-t|, it can be shown that the median is the minimizing value of the expected loss.
Section 4.4 Moments
Section Abstract We recall the definition of moments of distributions. Also we explore a new technique that makes that makes it simple to find the mean and variance of certain distributions whose moments are otherwise hard to calculate. This technique is called the method of the moment generating function.
Definition • The kth moment of a random variable with p.d.f. f(x) (or with p.f. p(x) if discrete) is given by EXk and it is defined whenver E|X|k is finite. • The first moment is the expected value. • The variance is the second moment minus the square of the first moment. • The kth central moment is E(X-μ)k
The Moment Generating Function • The moment Generating Function of a r.v. X is given by: Ψ(t) = E[etX] • The m.g.f is always defined at t=0; if it is moreover defined in an open interval containing zero then one can show that the moments E[Xk] of all orders exist and Ψ(k) (0)=E[Xk]; That is, in particular Ψ’(0)=E[X]; Ψ’’ (0)=E[X2]; etc.
Properties of m.g.f. • If Y = aX+b then ΨY(t)=etbΨX(at). • Suppose that X1, …,Xn are independent r.v. with the m.g.f.’s Ψ1(t),…, Ψn(t) resp.then the m.g.f. of the sum X = X1+ …+Xn is ΨX(t) = i=1∏nΨi(t). • Uniqueness of m.g.f. If two r.v.s X and Y have the same m.g.f. then they must have the same distribution.