Download

1 / 24
240 likes | 451 Vues
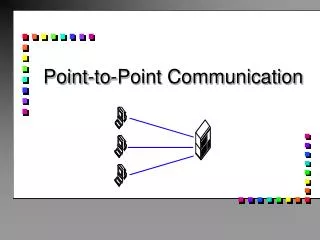
A Brief Look At MPI’s Point To Point Communication. Brian T. Smith Professor, Department of Computer Science Director, Albuquerque High Performance Computing Center (AHPCC). Point To Point Communication. What is meant by this concept? There is a sender and a receiver

E N D
A Brief Look At MPI’s Point To Point Communication Brian T. Smith Professor, Department of Computer Science Director, Albuquerque High Performance Computing Center (AHPCC)
Point To Point Communication • What is meant by this concept? • There is a sender and a receiver • The sender prepares a message in a package from the application storage area • The sender has a protocol on how it contacts and communicates with the receiver • The protocol is an agreement on how the communication is set up • The sender and receive agree to and how to communicate • The receiver receives the message package per its agreement with the sender • The receiver processes the packet and installs the data in the application storage area
Communication Models • Many models are feasible and have been implemented in various environments, past and current • MPI’s goal is to be portable across all of the reasonable models • This means that essentially NO assumptions can be made either • by the implementation, or • by the user • as to which model is or can be used • Let’s talk about two possible models • Models like these actually were used informally and differently by individual “CPUs” in our recent trial communications amongst the three institutions
MPIs Conventions • Messages have a format or a template • Message container, called a buffer, which is frequently assumed to be specified in user space – the storage set up by the user’s code • Length in terms of number of objects of message type • The type of objects in the message (basic type or user defined type) • A message tag – a user specified integer id for the message • Destination (for the sender) or source (for the receiver) of the message • The destination is the rank of the process in the process group • Communication world or group – named arrangement established by calls to MPI
MPIs Conventions Continued • Kinds of communication • Blocking • Sender does not return from an MPI call until the message buffer (the user’s container for the message) can be reused without corrupting the message that is being sent • Receiver does not return until the receiving message buffer contains all of the message • Non-blocking • Sender call returns after sufficient processing has been performed to allow the processor in a separate and independent thread to complete sending the message – in particular, changes in the sending tasks message buffer may change the message sent • Receiver call returns after sufficient processing has been performed to allow the processor in a separate and independent thread to complete receiving the message – in particular, receiver tasks message buffer likely changes after the receiver call returns to the user’s code • Other MPI procedures test or wait for the completion of sends and receives
MPI Conventions Continued • Modes of communication (contact protcols and assumptions) • These are assumptions that may be made by the user and the implementation must follow these assumptions • Modes are determined by the name of the MPI SEND procedure used • Eg: MPI_BSEND specifies a buffered send • Standard (no letter) • Assumes no particular protocol used – see later modes for typical protocols • Because no protocol is assumed, the programmer must assume the most restrictive one is used – namely “Ready” mode • Non-local operation – another process may have ‘to do something’ before this operation completes • Buffered (B letter) • Buffers created used by the protocol and allocated in user-space • Send can be started whether or not a receive has been posted • Local operation – another process does not have to do anything before this operation completes
Modes Continued • Synchronous (S letter) • Rendezvous semantics implemented • Sender starts but does not complete until the receiver has posted a receive • Buffer may be created in the receiver’s space or may be a direct transfer • Non-local operation • Ready (R letter) • Sender starts only if the matching receive has been posted • Erroneous if receive not posted – result is undefined • Non-local operation • Highest performance as it can be a direct transfer with no buffer
MPI Conventions Continued • Communication “worlds” or communicators • Specifies the domain of the processes within the group • A processor may be in more than one processor group • Each processor has a rank in each group • The rank of a particular process may be different in each group • The purpose of the groups is to arrange the processors so that it is convenient to send/receive message to the particular group and others processors do not see the message • Processors in a grid (north-south-east-west communication) • Processors distributed in a line or row or column of a grid • Processors in a circle • Processors in a hypercube configuration
Sender Receiver Sender Send buffer used No receive buffer used User data User data User data Buffer Buffer Buffer Pictures of Implementation Models Receiver Send buffer used Receive buffer used User data Buffer
Pictures of Implementation Models Receiver Sender No send buffer used No receive buffer used User data User data Buffer Buffer Receiver Sender No send buffer used Receive buffer used User data User data Buffer Buffer
Blocking Communication Operations • MPI_SEND and MPI_RECV • Let’s look at 3 reasonable ways to perform communication between 2 processors which exchange messages • One always works • One always deadlocks • That is, both processors hang waiting for the other to communicate • One may or may not work depending on the actual protocols used by the MPI implementation
Receive first Send next Send first Receive next Processor 0 Processor 1 This One Always Works • Steps: • Determine what rank the process is • If rank == 0 • Send a message from send_buffer to process with rank 1 • Receive a message into recv_buffer from process with rank 1 • Else if rank == 1 • Receive a message into recv_buffer from process with rank 0 • Send a message from send_buffer to process with rank 0 • Pattern of communication (doesn’t matter who (0 or 1) executes first)
Example Code – Always Works Call MPI_Comm_rank( comm, rank, ierr) If( rank == 0 ) then call MPI_Send( sendbuf, count, MPI_REAL, & 1, tag, comm, ierr ) call MPI_Recv( recvbuf, count, MPI_REAL, & 1, tag, comm, status, ierr ) Else if( rank == 1 ) then call MPI_Recv( recvbuf, count, MPI_REAL, & 0, tag, comm, status, ierr ) call MPI_Send( recvbuf, count, MPI_REAL, & 0, tag, comm, ierr ) Endif
Receive first Send next Receive first Send next Processor 0 Processor 1 This One Always Deadlocks • Steps: • Determine what rank the process is • If rank == 0 • Receive a message into recv_buffer from process with rank 1 • Send a message from send_buffer to process with rank 1 • Else if rank == 1 • Receive a message into recv_buffer from process with rank 0 • Send a message from send_buffer to process with rank 0 • Pattern of communication (doesn’t matter who (0 or 1) executes first)
Example Code – Always Deadlocks Call MPI_Comm_rank( comm, rank, ierr) If( rank == 0 ) then call MPI_Recv( recvbuf, count, MPI_REAL, & 1, tag, comm, status, ierr ) call MPI_Send( sendbuf, count, MPI_REAL, & 1, tag, comm, ierr ) Else if( rank == 1 ) then call MPI_Recv( recvbuf, count, MPI_REAL, & 0, tag, comm, status, ierr ) call MPI_Send( recvbuf, count, MPI_REAL, & 0, tag, comm, ierr ) Endif
Send first Receive next Send first Receive next Processor 0 Processor 1 This One may or May Not Work – The Worst Of All Possibilities • That is, it may work on one implementation and not work on another • Whether it works may depend on the size of the message or other unknown features of the implementation • It relies on the buffering of the messages for which the code does not specify – no MPI_BSEND used or no MPI_Buffer_attach • Pattern of communication (doesn’t matter who (0 or 1) executes first)
Example Code – May Fail Call MPI_Comm_rank( comm, rank, ierr) If( rank == 0 ) then call MPI_Send( sendbuf, count, MPI_REAL, & 1, tag, comm, ierr ) call MPI_Recv( recvbuf, count, MPI_REAL, & 1, tag, comm, status, ierr ) Else if( rank == 1 ) then call MPI_Send( recvbuf, count, MPI_REAL, & 0, tag, comm, ierr ) call MPI_Recv( recvbuf, count, MPI_REAL, & 0, tag, comm, status, ierr ) Endif
An Application Showing These Issues – Very Close To Your Code • Consider a 2-D Jacobi iteration (nn matrix) using a 5 point stencil • The data structure to be used here is a 1-D data structure • The coding illustrations are simpler here • However, this code does not scale well when the ratio of the size of the problem n to the number of processors is large – the practical case • The communication overhead is too large in this case • The algorithm or computation is: • Given an initial data for the matrix A, compute the average of the E-W-N-S neighbors of a point and assign it to the matrix B • Assign matrix B to A and repeat the process until the process has converged
Serial Code real A(0:n+1,0:n+1), B(1:n,:1:n) ! Main loop do while( .NOT. Converged(A) ) do j = 1, n b(1:n,j) = 0.25*(a(0:n-1,j)+a(2:n,j)+ & a(1:n,j-1)+a(1:n,j+1)) enddo a(1:n,1:n) = b(1:n,1:n) enddo
0 m+1 0 n+1 m m 1 1 1 1 n n Partitioning A an B Amongst The Processors • For simplicity of explaining the SEND/RECV commands, we use a 1-D partition 0 m+1 0 m+1 0 0 A n+1 n+1 m 1 1 B n Process 0
Code For This -- Unsafe real A(0:n+1,0:n+1), B(1:n,:1:n) ! Call MPI to return p (number of processors), and myrank ! Assume m is an integral multiple of p ! Main loop do while( .NOT. Converged(A) ) ! Compute with A and store in B as in the serial code … if( myrank > 0 ) then ! Send first column of B to last column of A of myrank-1 endif if( myrank < p-1 ) then ! Send last column of B to first column of A of myrank+1 endif if( myrank > 0 ) then ! Receive last column of B to first column of A of myrank-1 endif if( myrank < p-1 ) then ! Receive first column of B to last column of A of myrank+1 endif enddo
Unsafe Why? • All the sends are executed before any received is posted • Assumes as before that the messages are buffered • This should not be assumed in standard mode • Solution: • Divide the processors in two groups – even and odd proccssors • The odd processors send to the even processors first • Then the odd processors receive from the even processors • The even processors receive from the odd processors first • Then the even processors send to the odd processors • The effect is to interleave the send and receive commands so that no buffers are required to complete the communication • They, of course, may be used
Safe Communication do while( .NOT. Converged(A) ) ! Compute with A and store in B as in the serial code … if( mod(myrank,2) == 1 ) then ! Odd ranked processors ! Send first column of B to last column of A of myrank-1 ! If not the last processor, send the last column of B to ! processor myrank+1 ! Receive into first column of A from processor myrank-1 ! If not the last processor, receive into last column of A ! from processor myrank+1 else ! Even ranked processors if( mod(myrank,2) == 1 ) then ! Odd ranked processors ! If not the first processor, receive last column of B to ! first column of A of myrank-1 ! If not the last processor, receive the first column of B to ! processor myrank+1 ! If not the first processor, send into first column of B to ! processor myrank-1 ! If not the last processor, send the last column of B ! to processor myrank+1 endif enddo
Safe And Simpler Communications • Use the send/receive commands for all but the first and last processors • Use null processes to avoid the use of the special cases of dealing with the first and last processors