Download
1 / 1
10 likes | 153 Vues
This study presents a novel method for predicting disulfide bonds in proteins through grammatical inference based on a universal, ambiguous context-free grammar. By modeling protein structures and utilizing control sets for learning, we can analyze sequences and effectively identify bonding patterns, particularly those involving cysteine residues. Our approach combines positive and negative training examples to enhance accuracy and predictability in disulfide bond formations. This research has implications for advancing computational biology and protein engineering.

E N D
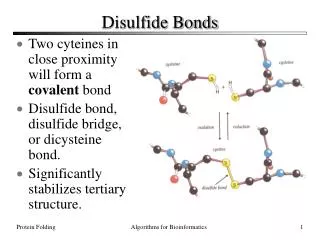
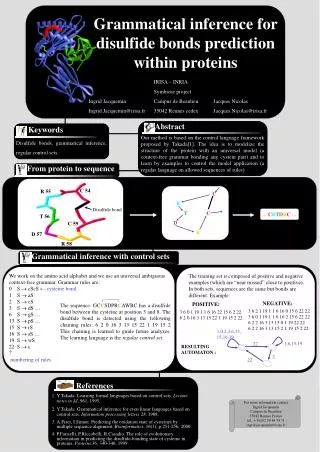
We work on the amino acid alphabet and we use an universal ambiguous context-free grammar. Grammar rules are:0 S cScS cysteine bond 1 S aS2 S cS3 S dS …6 S gS …13 S pS …15 S rS16 S sS …19 S wS22 S numbering of rules The sequence: GCCSDPRCAWRC has a disulfide bond between the cysteine at position 3 and 8. The disulfide bond is detected using the following chaining rules: 6 2 0 16 3 13 15 22 1 19 15 2This chaining is learned to guide future analyzes.The learning language is the regular control set. 1,0,2,3,6,13,15,16,19 1,6,15,19 22 2 22 Grammatical inference for disulfide bonds prediction within proteins IRISA – INRIA Symbiose project Campus de Beaulieu 35042 Rennes cedex Ingrid Jacquemin Ingrid.Jacquemin@irisa.fr Jacques Nicolas Jacques.Nicolas@irisa.fr Abstract Our method is based on the control language framework proposed by Takada[1]. The idea is to modelize the structure of the protein with an universal model (a context-free grammar bonding any cystein pair) and to learn by examples to control the model application (a regular language on allowed sequences of rules) Keywords Disulfide bonds, grammatical inference, regular control sets. From protein to sequence C R TC D R C 54 R 55 Disulfide bond ... CRTDRC ... T 56 C 59 D 57 R 58 Grammatical inference with control sets The training set is composed of positive and negative examples (which are “near missed” close to positive). In both sets, sequences are the same but bonds are different. Example: NEGATIVE: POSITIVE: 3 6 2 1 19 1 1 6 16 0 15 6 22 22 3 6 0 1 19 1 1 6 16 2 15 6 22 22 6 2 2 16 3 13 15 0 1 19 22 22 6 2 2 16 3 13 15 2 1 19 15 2 22 3 6 0 1 19 1 1 6 16 22 15 6 2 22 6 2 0 16 3 13 15 22 1 19 15 2 22 RESULTING AUTOMATON : • References • Y.Takada. Learning formal languages based on control sets. Lecture notes in AI, 961, 1995. • Y.Takada. Grammatical inference for even linear languages based on control sets. Information processing letters 28, 1988. • A.Fiser, I.Simon. Predicting the oxidation state of cysteines by multiple sequence alignment. Bioinformatics, 16(3), p.251-256, 2000. • P.Fariselli, P.Riccobelli, R.Casadio. The role of evolutionary information in predicting the disulfide-bonding state of cysteine in proteins. Proteins 36, 340-346, 1999. For more information contact Ingrid Jacquemin Campus de Beaulieu 35042 Rennes France tel.: +33(0)2 99 84 74 51 ingrid.jacquemin@irisa.fr