Development of an OCR System
120 likes | 253 Vues
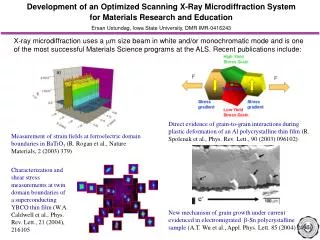
This project details the creation of an Optical Character Recognition (OCR) system, focusing on Latin-based fonts. Built from scratch, the system emphasizes effective formatting handling and generic recognition capabilities. It explores the Idocrase system, a methodology involving image processing transformations including sector and gap vectors, as well as pixel concentration analysis. The project showcases character recognition for both individual characters and words, utilizing a Generic Character Definition Database (GCDD). Results indicate strong character recognition rates while noting challenges in formatting and small letter handling.

Development of an OCR System
E N D
Presentation Transcript
Development of an OCR System Nathan Harmata TJHSST Computer Systems Lab 2007-2008
What is OCR? Optical Character Recognition Font and handwriting based
Goals of My Project Generic recognition for Latin-based fonts System built from scratch Proper handling of most formatting
Transformations Attribute Character Model
Transformations Sector Vector - image is parsed into parts that pass the vertical line test - then each part is transformed into a collection of line segments Gap Vector - gaps, if any, are found on the four sides of the image
Transformations Pixel Concentration Vector – which sides, if any, have a higher concentration of pixels
Character Recognition GCDD – Generic Character Definition Database Averages of Character Models for every character from many different fonts 0 PixelConcentrationVector balanced balanced SectorVector 4 3 GapVector
Character Recognition For a single character: For words, dictionary and grammar references are used.
Results -Mediocre word recognition -Doesn’t handle formatting well -Doesn’t handle small letters well -Fairly accurate single character recognition (93.7%)