Novel Peptide Identification using ESTs and Sequence Database Compression
This study addresses the challenges in peptide identification, highlighting the shortcomings of existing protein sequence databases. It discusses the missed opportunities for novel peptide discovery due to biases in traditional databases, which favor well-understood isoforms. By utilizing Compressed Expressed Sequence Tag (EST) peptide databases, we can enhance the identification of novel coding mutations, isoforms, and alternative splicing events. This methodology aims to refine peptide search processes, making them efficient while reducing computational complexity and error rates, ultimately leading to improved outcomes in proteomics research.


Novel Peptide Identification using ESTs and Sequence Database Compression
E N D
Presentation Transcript
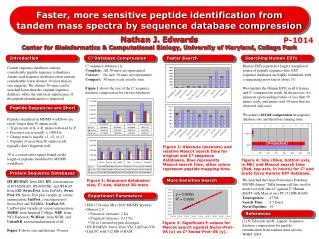
Novel Peptide Identification using ESTs and Sequence Database Compression Nathan Edwards Center for Bioinformatics and Computational Biology University of Maryland, College Park
What is missing from protein sequence databases? • Known coding SNPs • Novel coding mutations • Alternative splicing isoforms • Alternative translation start-sites • Microexons • Alternative translation frames
Why don’t we see more novel peptides? • Tandem mass spectrometry doesn’t discriminate against novel peptides......but protein sequence databases do! • Searching traditional protein sequence databases biases the results towards well-understood protein isoforms!
Novel Mutation Ala2→Pro associated with familial amyloid polyneuropathy
Searching ESTs • Proposed long ago: • Yates, Eng, and McCormack; Anal Chem, ’95. • Now: • Protein sequences are sufficient for protein identification • Computationally expensive/infeasible • Difficult to interpret • Make EST searching feasible for routine searching to discover novel peptides.
Pros No introns! Primary splicing evidence for annotation pipelines Evidence for dbSNP Often derived from clinical cancer samples Cons No frame Large (8Gb) “Untrusted” by annotation pipelines Highly redundant Nucleotide error rate ~ 1% Searching Expressed Sequence Tags (ESTs)
Other Search Strategies • Genome Corrected ESTs • Large (2Gb) • Controls for nucleotide error rate • Polymorphism lost, potential errors introduced • Genome Clustered ESTs • Small, Gene model • Convergence to well-understood isoforms • Controls nucleotide error rate • Full-Length mRNAs • Incomplete gene coverage, “most” are already in IPI
Other Search Strategies • Genome • Large (6Gb), lots of non-coding DNA • Find novel ORFs, no sampling bias • Miss spliced peptide sequences. • Genscan Exons • Small, find novel ORFs. • Miss spliced peptide sequences. • How should we interpret peptide identifications with no mRNA evidence?
Compressed EST Peptide Sequence Database • For all ESTs mapped to a UniGene gene: • Six-frame translation • Eliminate ORFs < 30 amino-acids • Eliminate amino-acid 30-mers observed once • Compress to C2 FASTA database • Complete, Correct for amino-acid 30-mers • Gene-centric peptide sequence database: • Size: < 3% of naïve enumeration, 20774 FASTA entries • Running time: ~ 1% of naïve enumeration search • E-values: ~ 2% of naïve enumeration search results
Compressed EST Peptide Sequence Database • For all ESTs mapped to a UniGene gene: • Six-frame translation • Eliminate ORFs < 30 amino-acids • Eliminate amino-acid 30-mers observed once • Compress to C2 FASTA database • Complete, Correct for amino-acid 30-mers • Gene-centric peptide sequence database: • Size: < 3% of naïve enumeration, 20774 FASTA entries • Running time: ~ 1% of naïve enumeration search • E-values: ~ 2% of naïve enumeration search results
SBH-graph ACDEFGI, ACDEFACG, DEFGEFGI
Compressed SBH-graph ACDEFGI, ACDEFACG, DEFGEFGI
Sequence Databases & CSBH-graphs • Original sequences correspond to paths ACDEFGI, ACDEFACG, DEFGEFGI
Sequence Databases & CSBH-graphs • All k-mers represented by an edge have the same count 1 2 2 1 2
CSBH-graphs • Quickly determine which k-mers occur at least twice 2 2 1 2
de Bruijn Sequences de Bruijn sequences represent all words of length k from some alphabet A. A = {0,1}, k = 3: s = 0001110100 A = {0,1}, k = 4: s = 0000111101011001000
110 011 100 001 000 010 111 101 de Bruijn Graph: A = {0,1}, k = 4 1 1 0 1 0 1 1 0 1 0 1 0 1 0 0 0
Correct, Complete, Compact (C3) Enumeration • Set of paths that use each edge exactly once ACDEFGEFGI, DEFACG
Correct, Complete (C2) Enumeration • Set of paths that use each edge at least once ACDEFGEFGI, DEFACG
Patching the CSBH-graph • Use artificial edges to fix unbalanced nodes
Patching the CSBH-graph • Use matching-style formulations to choose artificial edges • Optimal C2/C3 enumeration in polynomial time. • Chinese Postman Problem • Edmonds and Johnson, ’73 • l-tuple DNA sequencing • Pevzner, ’89 • Shortest (Common) Superstring • MAX-SNP-hard, 2.5 approx algorithm
-2 -1 -4 -1 -2 1 3 2 1 3 C3 Enumeration #in-#out #in-#out Cost: k
-4 -2 -1 -1 -2 0 0 3 1 2 3 1 C3 Enumeration #in-#out #in-#out Cost: 0 Cost: 0 Cost: k
EHAC FHAC ACD HAC GHAC D Reusing Edges • ACDEHAC, ACDFHAC, ACDGHACD
$ACD EHAC ACD HAC FHAC GHAC D Reusing Edges • C3: ACDEHACDFHAC, ACDGHACD
D EHAC ACD HAC FHAC GHAC D Reusing Edges • C2: ACDEHACDFHACDGHAC
-4 -2 -1 -2 -1 3 2 1 1 3 C2 Enumeration #in-#out #in-#out 4 10 “Shortcut paths” 7
Implementation • CSBH-graph construction • Determine non-trivial nodes directly • Consecutive non-trivial nodes determine edges • C3/C2 enumeration • C3: Trivial “assignment” of artificial edges • C2: Depth-first search & Goldberg’s CS2 min cost flow code • Eulerian path algorithm • Can be applied to entire EST database • Condor grid and PBS cluster for CSBH-graph construction • Large memory machine for C3/C2 enumeration
Conclusions • Peptides identify more than just proteins • Compressed peptide sequence databases makes routine EST searching feasible • Currently available for download • Can include other sources of peptide sequence at little additional cost. • CSBH-graph + edge counts + C2/C3 enumeration algorithms • Minimal FASTA representation of k-mer sets
Acknowledgements • Chau-Wen Tseng, Xue Wu • UMCP Computer Science • Catherine Fenselau, Crystal Harvey • UMCP Biochemistry • Calibrant Biosystems • PeptideAtlas, HUPO PPP, X!Tandem • Funding: National Cancer Institute