Download

1 / 24
240 likes | 335 Vues
Explore the basic principles and current data model of the open annotation collaboration project involving multiple partners and a protocol-less interoperability approach. Learn about the aims, phases, and the protocol-less approach promoting interoperability.

E N D
Overview of the Open Annotation Collaboration <http://www.openannotation.org/> Robert Sanderson – rsanderson@lanl.gov azaroth42@gmail.com Herbert Van de Sompel – herbertv@lanl.gov hvdsomp@gmail.com Digital Library Research and Prototyping Team Los Alamos National Laboratory, USA This research was funded by the Andrew W. Mellon Foundation. Acknowledgements: Tim Cole, Bernhard Haslhofer, Jane Hunter, Ray Larson, Cliff Lynch, Michael Nelson, Doug Reside
Overview • The Collaboration and Project • Interoperability: • Basic Principles • Current Data Model • Protocol-less Approach
The Collaboration • Partners: • Los Alamos National Laboratory • University of Illinois at Urbana-Champaign • University of Queensland • University of Maryland • George Mason University • Plus: International Advisory Board • Discussion Group: • http://groups.google.com/group/oac-discuss • Open (moderated joins) list for community participation. Please join :)
The Project • Aims • Facilitate a Web-centric interoperable annotation environment • Demonstrate the proposed environment for scholarly use-cases • Seed adoption by deployment of high-visibility production systems • Phase I • Funded by Mellon Foundation • Exploration of Existing Systems, Requirements and Use Case analysis • Initial Interoperability Specification • Integration of AXE and Zotero
Interoperability: Basic Principles • Effort focuses on Interoperability to allow annotation sharing • Many MANY non-interoperable annotation systems already • Existing interoperability mechanisms (eg Annotea) need updating • Interoperability approach is based on the Architecture of the Web • Communication is increasingly online • Resources of interest are increasingly online • Maximize chance of adoption by not being domain-centric • Entities within the model must be identified by HTTP URIs • … when possible • From Linked Data guidelines • Globally unique identifiers without central system overhead • Locator as well as Identifier: can retrieve representation
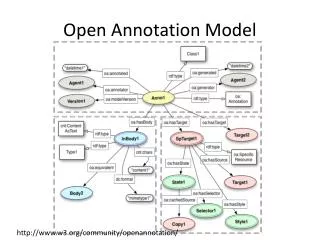
Data Model: Step 1 • An annotation is an event at a moment in time, initiated by an agent, with a source of content and a target. There is an implicit or explicit relationship between the source and target expressed by the annotation. • The Source of Content must have some relationship to the Target. By default, it should be somehow 'about' the Target for it to be considered an Annotation.
Step 1: Baseline Model As web resources, both Content and Target can be of any format, any (or no) language, etc.
Step 2: Transcription Document Must be able to transmit a description of the Annotation event.
Step 3: Properties and Relationships Properties and relationships can be attached to the Annotation and other resources.
Step 4: Versioning As events, Annotations cannot be changed, but can be replaced with new versions.
Step 5: Inline Content Important to be able to capture the content within the annotation transcription
Step 6: Segments of Resources W3C Media Fragment URIs allow us to create a URI that identifies a segment of a resource for common cases.
Step 6b: Complex Segments Some cases are more complex than can be described with Media Fragment URIs.
Step 7: Multiple Targets Note that the relationship from the Content applies to all of the Targets.
Protocol-less Approach • Existing systems are tightly coupled: • The client sends the annotation to the server to store • The server sends the annotation to clients on request • Annotea is a REST protocol, Google Sidewiki uses ATOM plus extensions, most are proprietary. • We believe this is a hindrance to interoperability … anyprotocol that ties servers and clients together is a hindrance to interoperability from the Linked Data perspective. • We recommend no protocol, as opposed to not recommending a protocol.
Protocol-less Approach • Breaking This Apart Promotes Interoperability: • The client sends the annotation somewhere to store (or multiple places) • The server retrieves the annotation • … using regular discovery/harvesting techniques (Pull) • … on demand from the client (Pull on demand) • … by being one of the places the client sends the annotation to (Push) • The server is just one service that can send the annotation to clients on request
Protocol-less Approach • Consequences: • Multiple servers, aggregators or other applications can access the annotation • The client can use whatever protocol is needed by the storage server(s) • Annotations are regular web resources by necessity • Access control is just like any other access control on the web • Services can be used to extend information in annotation • Add extra information for robustness over time • Add extra information for robustness of segment location • Text Mining, Data Mining services • Graph/Relationship Mining across other annotations • … • Servers can replace inline content with real web resources • Multiple servers can do this, and deduplicate with original identifier • Use well known owl:sameAs predicate for this
Thank You • Thank You! • Questions? • Pointers: • http://www.openannotation.org/ • http://groups.google.com/group/oac-discuss • azaroth42@gmail.com ; hvdsomp@gmail.com