
Context-Dependent Phoneme Modeling: Analyzing the Word "Lines"
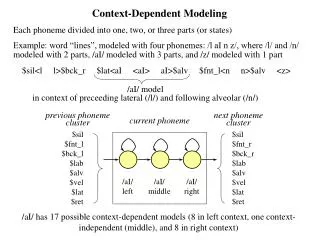
This analysis explores context-dependent modeling of phonemes through the example of the word "lines," formed by four phonemes: /l/, /aI/, /n/, and /z/. Each phoneme is dissected into distinct parts for nuanced understanding: /l/ and /n/ consist of 2 parts, /aI/ has 3 parts, and /z/ has 1 part. The modeling considers the phoneme clusters in relation to their preceding and following environments, showcasing a total of 17 possible models for /aI/, including both context-dependent and independent scenarios.

Context-Dependent Phoneme Modeling: Analyzing the Word "Lines"
E N D
Presentation Transcript
Context-Dependent Modeling Each phoneme divided into one, two, or three parts (or states) Example: word “lines”, modeled with four phonemes: /l aI n z/, where /l/ and /n/ modeled with 2 parts, /aI/ modeled with 3 parts, and /z/ modeled with 1 part $sil<l l>$bck_r $lat<aI <aI> aI>$alv $fnt_l<n n>$alv <z> /aI/ model in context of preceeding lateral (/l/) and following alveolar (/n/) previous phoneme cluster next phoneme cluster current phoneme $sil $fnt_l $bck_l $lab $alv $vel $lat $ret $sil $fnt_r $bck_r $lab $alv $vel $lat $ret /aI/ left /aI/ middle /aI/ right /aI/ has 17 possible context-dependent models (8 in left context, one context-independent (middle), and 8 in right context)




















