CHAPTER 4 Syntax ANALYSIS Section 0 Approaches to implement a Syntax analyzer
CHAPTER 4 Syntax ANALYSIS Section 0 Approaches to implement a Syntax analyzer. 1 、 The syntax description of programming language constructs Context-free grammars BNF(Backus Naur Form) notation Notes: Grammars offer significant advantages to both language designers and compiler writers.


CHAPTER 4 Syntax ANALYSIS Section 0 Approaches to implement a Syntax analyzer
E N D
Presentation Transcript
CHAPTER 4 Syntax ANALYSIS Section 0 Approaches to implement a Syntax analyzer 1、The syntax description of programming language constructs • Context-free grammars • BNF(Backus Naur Form) notation Notes: Grammars offer significant advantages to both language designers and compiler writers
CHAPTER 4 Syntax ANALYSIS Section 0 Approaches to implement a Syntax analyzer 3、Approached to implement a syntax analyzer • Manual construction • Construction by tools
CHAPTER 4 Syntax ANALYSIS Section 1 The Role of the Parser 1、 Main task • Obtain a string of tokens from the lexical analyzer • Verify that the string can be generated by the grammar of related programming language • Report any syntax errors in an intelligible fashion • Recover from commonly occurring errors so that it can continue processing the remainder of its input
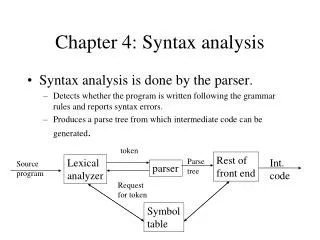
token Rest of front end Intermediate representation Parse tree Lexical analyzer Source program Parser Get next token Symbol table CHAPTER 4 Syntax ANALYSIS Section 1 The Role of the Parser 2、Position of parser in compiler model Notes: Parser is the core of the compiler
CHAPTER 4 Syntax ANALYSIS Section 1 The Role of the Parser 3、Parsing methods • Universal parsing method • Too inefficient to use in production compilers • TOP-DOWN method • Build parse trees from the top(root) to the bottom(leaves) • The input is scanned from left to right • LL(1) grammars (often implemented by hand) • BOTTOM-UP method • Start from the leaves and work up to the root • The input is scanned from left to right • LR grammars(often constructed by automated tools)
CHAPTER 4 Syntax ANALYSIS Section 2 TOP-DOWN PARSING 1、Ideas of top-down parsing • Find a leftmost derivation for an input string • Construct a parse tree for the input starting from the root and creating the nodes of the parse tree in preorder.
CHAPTER 4 Syntax ANALYSIS Section 2 TOP-DOWN PARSING 2、Main methods • Predictive parsing (no backtracking) • Recursive descent (involve backtracking) Notes: Backtracking is rarely needed to parse programming language constructs because backtracking is still not very efficient, and tabular methods are preferred
CHAPTER 4 Syntax ANALYSIS Section 2 TOP-DOWN PARSING 3、Recursive descent • A deducing procedure, which construct a parse tree for the string top-down from S. When there is any mismatch, the program go back to the nearest non-terminal, select another production to construct the parse tree • If you produce a parse tree at last, then the parsing is success, otherwise, fail.
CHAPTER 4 Syntax ANALYSIS Section 2 TOP-DOWN PARSING E.g. Consider the grammar S cAd A ab | a Construct a parse tree for the string “cad”
CHAPTER 4 Syntax ANALYSIS Section 2 TOP-DOWN PARSING 3、Recursive descent • Backtracking parsers are not seen frequently, because: • Backtracking is not very efficient. • Why backtracking occurred? • A left-recursive grammar can cause a recursive-descent parser to go into an infinite loop. • An ambiguity grammar can cause backtracking • Left factor can also cause a backtracking
CHAPTER 4 Syntax ANALYSIS Section 2 TOP-DOWN PARSING 4、Elimination of Left Recursion 1)Basic form of left recursion Left recursion is the grammar contains the following kind of productions. • P P| Immediate recursion or • P Aa , APb Indirect recursion
CHAPTER 4 Syntax ANALYSIS Section 2 TOP-DOWN PARSING 4、Elimination of Left Recursion 2)Strategy for elimination of Left Recursion Convert left recursion into the equivalent right recursion P P| => P->* => P P’ P’ P’|
CHAPTER 4 Syntax ANALYSIS Section 2 TOP-DOWN PARSING 4、Elimination of Left Recursion 3)Algorithm (1) Elimination of immediate left recursion P P| => P->* => P P’ P’ P’| (2) Elimination of indirect left recursion Convert it into immediate left recursion first according to specific order, then eliminate the related immediate left recursion
Algorithm: • (1)Arrange the non-terminals in G in some order as P1,P2,…,Pn, do step 2 for each of them. • (2) for (i=1,i<=n,i++) {for (k=1,k<=i-1,k++) {replace each production of the form Pi Pk by Pi 1 | 2 |……| ,n ; where Pk 1| 2|……| ,n are all the current Pk -productions } change Pi Pi1| Pi2|…. | Pim|1| 2|….| n into Pi 1 Pi`| 2 Pi `|……| n Pi ` Pi`1Pi`|2Pi`|……| mPi`| } /*eliminate the immediate left recursion*/ (3)Simplify the grammar.
E.g. Eliminating all left recursion in the following grammar: (1) S Qc|c (2)Q Rb|b (3) R Sa|a Answer: 1)Arrange the non-terminals in the order:R,Q,S 2)for R: no actions. for Q:Q Rb|b Q Sab|ab|b for S: S Qc|c S Sabc|abc|bc|c; then get S (abc|bc|c)S` S` abcS`| 3) Because R,Q is not reachable, so delete them so, the grammar is : S (abc|bc|c)S` S` abcS`|
CHAPTER 4 Syntax ANALYSIS Section 2 TOP-DOWN PARSING 4、Elimination of Left Recursion 3)Algorithm Note: (1)If you arrange the non-terminals in different order, the grammar you get will be different too, but they can recognize the same language. (2) You cannot change the starting symbol
CHAPTER 4 Syntax ANALYSIS Section 2 TOP-DOWN PARSING 5、Eliminating Ambiguity of a grammar • Rewriting the grammar stmtif expr then stmt|if expr then stmt else stmt|other ==> stmt matched-stmt|unmatched-stmt matched-stmt if expr then matched-stmt else matched-stmt|other unmatched-stmt if expr then stmt|if expr then matched-stmt else unmatched-stmt
CHAPTER 4 Syntax ANALYSIS Section 2 TOP-DOWN PARSING 6、Left factoring • A grammar transformation that is useful for producing a grammar suitable for predictive parsing • Rewrite the productions to defer the decision until we have seen enough of the input to make right choice
CHAPTER 4 Syntax ANALYSIS Section 2 TOP-DOWN PARSING 6、Left factoring If the grammar contains the productions like A1| 2|…. | n Chang them intoAA` A`1|2|…. |n
CHAPTER 4 Syntax ANALYSIS Section 2 TOP-DOWN PARSING 7、Predictive Parsers Methods • Transition diagram based predictive parser • Non-recursive predictive parser
CHAPTER 4 Syntax ANALYSIS Section 2 TOP-DOWN PARSING 9、Non-recursive Predictive Parsing 1) key problem in predictive parsing • The determining the production to be applied for a non-terminal 2)Basic idea of the parser Table-driven and use stack
CHAPTER 4 Syntax ANALYSIS Section 2 TOP-DOWN PARSING • 9、Non-recursive Predictive Parsing • 3) Model of a non-recursive predictive parser Input a+b……$ Stack Output Predictive Parsing Program Parsing Table M S $
CHAPTER 4 Syntax ANALYSIS Section 2 TOP-DOWN PARSING 9、Non-recursive Predictive Parsing 4) Predictive Parsing Program X: the symbol on top of the stack; a: the current input symbol If X=a=$, the parser halts and announces successful completion of parsing; If X=a!=$, the parser pops X off the stack and advances the input pointer to the next input symbol;
CHAPTER 4 Syntax ANALYSIS Section 2 TOP-DOWN PARSING 9、Non-recursive Predictive Parsing 4) Predictive Parsing Program If X is a non-terminal, the program consults entry M[X,a] of the parsing table M. This entry will be either an X-production of the grammar or an error entry.
CHAPTER 4 Syntax ANALYSIS Section 2 TOP-DOWN PARSING E.g. Consider the following grammar, and parse the string id+id*id$ 1.E TE` 2.E` +TE` 3.E` 4.T FT` 5.T` *FT` 6.T` 7.F i 8.F (E)
CHAPTER 4 Syntax ANALYSIS Section 2 TOP-DOWN PARSING Parsing table M
CHAPTER 4 Syntax ANALYSIS Section 2 TOP-DOWN PARSING 10、Construction of a predictive parser 1) FIRST & FOLLOW FIRST: • If is any string of grammar symbols, let FIRST() be the set of terminals that begin the string derived from . • If , then is also in FIRST() • That is : V*, First()={a| a……,a VT } +
CHAPTER 4 Syntax ANALYSIS Section 2 TOP-DOWN PARSING 10、Construction of a predictive parser 1) FIRST & FOLLOW FOLLOW: • For non-terminal A, to be the set of terminals a that can appear immediately to the right of A in some sentential form. • That is: Follow(A)={a|S …Aa…,a VT } If S…A, then $ FOLLOW(A)。
CHAPTER 4 Syntax ANALYSIS Section 2 TOP-DOWN PARSING 10、Construction of a predictive parser 2) Computing FIRST() (1)to compute FIRST(X) for all grammar symbols X • If X is terminal, then FIRST(X) is {X}. • If X is a production, then add to FIRST(X). • If X is non-terminal, and X Y1Y2…Yk,Yj(VNVT),1j k, then
{ j=1; FIRST(X)={}; //initiate while ( j<k and FIRST(Yj)) { FIRST(X)=FIRST(X)(FIRST(Yj)-{}) j=j+1 } IF (j=k and FIRST(Yk)) FIRST(X)=FIRST(X) {} }
CHAPTER 4 Syntax ANALYSIS Section 2 TOP-DOWN PARSING 10、Construction of a predictive parser 2) Computing FIRST() (2)to compute FIRST for any string =X1X2…Xn,Xi(VNVT),1i n {i=1; FIRST()={}; //initiate while (i<n and FIRST(Xj)) { FIRST()=FIRST()(FIRST(Xi)-{}) i=i+1 } IF (i=n and FIRST(Xn)) FIRST()=FIRST(){} }
CHAPTER 4 Syntax ANALYSIS Section 2 TOP-DOWN PARSING 10、Construction of a predictive parser 3) Computing FOLLOW(A) (1) Place $ in FOLLOW(S), where S is the start symbol and $ is the input right end-marker. (2)If there is A B in G, then add (First()-) to Follow(B). (3)If there is A B, or AB where FIRST() contains ,then add Follow(A) to Follow(B).
CHAPTER 4 Syntax ANALYSIS Section 2 TOP-DOWN PARSING E.g. Consider the following Grammar, construct FIRST & FOLLOW for each non-terminals 1.E TE` 2.E` +TE` 3.E` 4.T FT` 5.T` *FT` 6.T` 7.F i 8.F (E)
Answer: First(E)=First(T)=First(F)={(, i} First(E`)={+, } First(T`)={*, } Follow(E)= Follow(E`)={),$} Follow(T)= Follow(T`)={+,),$} Follow(F)={*,+,),$}
CHAPTER 4 Syntax ANALYSIS Section 2 TOP-DOWN PARSING 10、Construction of a predictive parser 4) Construction of Predictive Parsing Tables Main Idea: Suppose A is a production with a in FIRST(). Then the parser will expand A by when the current input symbol is a. If , we should again expand A by if the current input symbol is in FOLLOW(A), or if the $ on the input has been reached and $ is in FOLLOW(A). *
CHAPTER 4 Syntax ANALYSIS Section 2 TOP-DOWN PARSING 10、Construction of a predictive parser 4) Construction of Predictive Parsing Tables • Input. Grammar G. • Output. Parsing table M.
Method. 1. For each production A , do steps 2 and 3. 2. For each terminal a in FIRST(), add A to M[A,a]. 3. If is in FIRST(), add A to M[A,b] for each terminal b in FOLLOW(A). If is in FIRST() and $ is in FOLLOW(A), add A to M[A,$]. 4.Make each undefined entry of M be error.
E.g. Consider the following Grammar, construct predictive parsing table for it. 1.E TE` 2.E` +TE` 3.E` 4.T FT` 5.T` *FT` 6.T` 7.F i 8.F (E)
Answer: First(E)=First(T)=First(F)={(, i} First(E`)={+, } First(T`)={*, } Follow(E)= Follow(E`)={),$} Follow(T)= Follow(T`)={+,),$} Follow(F)={*,+,),$}
CHAPTER 4 Syntax ANALYSIS Section 2 TOP-DOWN PARSING 11、LL(1) Grammars E.g. Consider the following Grammar, construct predictive parsing table for it. S iEtSS` |a S` eS | E b
CHAPTER 4 Syntax ANALYSIS Section 2 TOP-DOWN PARSING 11、LL(1) Grammars 1)Definition A grammar whose parsing table has no multiply-defined entries is said to be LL(1). The first “L” stands for scanning the input from left to right. The second “L” stands for producing a leftmost derivation “1” means using one input symbol of look-ahead s.t each step to make parsing action decisions.
CHAPTER 4 Syntax ANALYSIS Section 2 TOP-DOWN PARSING 11、LL(1) Grammars Note: (1)No ambiguous can be LL(1). (2)Left-recursive grammar cannot be LL(1). (3)A grammar G is LL(1) if and only if whenever A | are two distinct productions of G:
CHAPTER 4 Syntax ANALYSIS Section 2 TOP-DOWN PARSING 12、Transform a grammar to LL(1) Grammar • Eliminating all left recursion • Left factoring
CHAPTER 4 SYNTAX ANALYSIS Section 3 BOTTOM-UP Parsing 1、Basic idea of bottom-up parsing Shift-reduce parsing • Operator-precedence parsing • An easy-to-implement form • LR parsing • A much more general method • Used in a number of automatic parser generators
CHAPTER 4 SYNTAX ANALYSIS Section 3 BOTTOM-UP Parsing 2、Basic concepts in Shift-reducing Parsing • Handles • Handle Pruning
Input ……$ Stack Output Parsing Program Parsing Table M $ CHAPTER 4 SYNTAX ANALYSIS Section 3 BOTTOM-UP Parsing 3、Stack implementation of Shift-Reduce parsing
CHAPTER 4 SYNTAX ANALYSISSection 5 LR parsers 1、LR parser • An efficient, bottom-up syntax analysis technique that can be used to parse a large class of context-free grammars • LR(k) • L: left-to-right scan • R:construct a rightmost derivation in reverse • k:the number of input symbols of look ahead
CHAPTER 4 SYNTAX ANALYSISSection 5 LR parsers 2、Advantages of LR parser • It can recognize virtually all programming language constructs for which context-free grammars can be written • It is the most general non backtracking shift-reduce parsing method • It can parse more grammars than predictive parsers can • It can detect a syntactic error as soon as it is possible to do so on a left-to-right scan of the input