Managing External Data 3
Managing External Data 3. Gitte Christensen Dyalog Ltd. Relational Algebra is : the formal description of how a relational database operates the mathematics which underpin SQL operations.


Managing External Data 3
E N D
Presentation Transcript
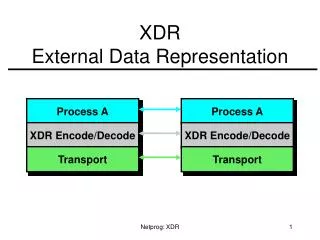
Managing External Data 3 Gitte Christensen Dyalog Ltd
Relational Algebra is : the formal description of how a relational database operates the mathematics which underpin SQL operations. Operators in relational algebra are not necessarily the same as SQL operators, even if they have the same name. Relational Algebra
Relation - a set of tuples. Tuple - a collection of attributes which describe some real world entity. Attribute - a real world role played by a named domain. Domain - a set of atomic values. Set - a mathematical definition for a collection of objects which contains no duplicates. Terminology
INSERT - provides a list of attribute values for a new tuple in a relation. This operator is the same as SQL. DELETE - provides a condition on the attributes of a relation to determine which tuple(s) to remove from the relation. This operator is the same as SQL. MODIFY - changes the values of one or more attributes in one or more tuples of a relation, as identified by a condition operating on the attributes of the relation. This is equivalent to SQL UPDATE. Operators - Write
There are two groups of operations: Mathematical set theory based relations: UNION, INTERSECTION, DIFFERENCE, and CARTESIAN PRODUCT. Special database operations: SELECT (not the same as SQL SELECT), PROJECT, and JOIN. Operators - Retrieval
SELECT is used to obtain a subset of the tuples of a relation that satisfy a select condition. For example, find all employees born after 1st Jan 1950: SELECT dob > ’01/JAN/1950’ (employee) Relational SELECT
The PROJECT operation is used to select a subset of the attributes of a relation by specifying the names of the required attributes. For example, to get a list of all employees surnames and employee numbers: PROJECT surname,empno (employee) Relational PROJECT
SELECT and PROJECT SELECT and PROJECT can be combined together. For example, to get a list of employee numbers for employees in department number 1:
Consider two relations R and S. UNION of R and Sthe union of two relations is a relation that includes all the tuples that are either in R or in S or in both R and S. Duplicate tuples are eliminated. INTERSECTION of R and Sthe intersection of R and S is a relation that includes all tuples that are both in R and S. DIFFERENCE of R and Sthe difference of R and S is the relation that contains all the tuples that are in R but that are not in S. Set Operations - semantics
For set operations to function correctly the relations R and S must be union compatible. Two relations are union compatible if they have the same number of attributes the domain of each attribute in column order is the same in both R and S. SET Operations - requirements
The Cartesian Product is also an operator which works on two sets. It is sometimes called the CROSS PRODUCT or CROSS JOIN. It combines the tuples of one relation with all the tuples of the other relation. CARTESIAN PRODUCT
JOIN is used to combine related tuples from two relations: In its simplest form the JOIN operator is just the cross product of the two relations. As the join becomes more complex, tuples are removed within the cross product to make the result of the join more meaningful. JOIN allows you to evaluate a join condition between the attributes of the relations on which the join is undertaken. The notation used is R JOIN join condition S JOIN Operator
Invariably the JOIN involves an equality test, and thus is often described as an equi-join. Such joins result in two attributes in the resulting relation having exactly the same value. A ‘natural join’ will remove the duplicate attribute(s). In most systems a natural join will require that the attributes have the same name to identify the attribute(s) to be used in the join. This may require a renaming mechanism. If you do use natural joins make sure that the relations do not have two attributes with the same name by accident. Natural Join
Notice that much of the data is lost when applying a join to two relations. In some cases this lost data might hold useful information. An outer join retains the information that would have been lost from the tables, replacing missing data with nulls. There are three forms of the outer join, depending on which data is to be kept. LEFT OUTER JOIN - keep data from the left-hand table RIGHT OUTER JOIN - keep data from the right-hand table FULL OUTER JOIN - keep data from both tables OUTER JOINs
SQL query optimisation • Optimisation Concept • Implementation of Rel. Algebra Operations • Oracle Query Execution Plans. • Btree Indexing • Rtree Indexing
SQL query optimisation Parse and Translate Relational algebra expression SQL query Optimisation using data statistics Query result Execution plan Evaluate against Database
Optimisation steps • Parse • check SQL syntax and columns & tables valid • Translate • SQL into relational algebra expression • Select most efficient query execution plan • minimisation of the input/output and cpu requirements • Evaluate expression • Call required code modules
Example SQL query S(sno,sname,status,scity) SP(sno,pno,qty) P(pno,pname,colour,weight,pcity) Get supplier name for suppliers who supply red parts. SQL select sname from S,P,SP where S.sno = SP.sno and P.pno = Sp.pno and colour = ‘red’;
Example SQL query • How would you do this?
Query as relational algebra expression and graph (((((( P restrict[ colour = red] ) project[ pno ]) join SP [pno = pno]) project [ sno ]) join S [ sno = sno ]) project [ sname ]) project join project join project restrict P SP S
Relational algebra transformations • The following transformations can be applied without regard to the actual data values stored in the tables referenced in the SQL query. • They are being stated to justify some of the common manipulations of the relational algebra during optimisation.
Distributive transformation Distributive Law f(A o B) = f(A) o f(B) e.g. restrict(A join B) = restrict (A) join restrict (B) Restrict distributes over union, intersection, difference and join. For join the restriction must, at it’s most complex, consist of the AND of two separate conditions one for each operand. Project distributes over union, intersection, join. For join the join attributes must be included in the projection. Thus restricts / projects can often be done before joins.
Commutative transformation Commutative Law The operator o is commutative if :- A o B = B o A for all values of A and B Union, intersection and join are commutative. E.g S join SP = SP join S Thus optimiser can choose best order typically the smallest table is used to drive the join processing.
Associative transformation Associative Law Operator o is associative if :- A o ( B o C ) = ( A o B ) o C for all A,B,C values e.g. A join ( B join C ) = ( A join B ) join C Union, intersection and join are associative. Thus for a 3 table join the optimiser can choose any sequence of pairs of joins.
Semantic transformations Referential Integrity Based. select pno from SP,S where SP.sno = S.sno; If declared S.sno as PK and SP.sno as FK then optimise to:- select pno from SP; Application of Negator Functions where not (status > 20) this cannot use an index scan so must use table scan but if transform to status <= 20 - now can use index scan Assumes that an index on the status column already exists
Will the results be the same? select sname from s,sp where s,sno = sp.sno and sp.pno = ‘p2’; select sname from sp,s where sp.pno = ‘p2’ and sp.sno = s.sno; select sname from s where s.sno in ( select sp.sno from sp where sp.pno = ‘p2’); Explain. What is the implication for performance of the three?
Yes - all produce the same result rows • join s to sp can be transformed into join sp to s as join operation is commutative • restrict can be distributed past the join thus first two order of operations can be ignored • set membership can be converted to a join • optimisation will convert all 3 queries the same query so all must have the same performance - user can chose which to use
Algorithm selection • The relational algebra operations typically have multiple code implementations. It is necessary for the optimiser to select the most appropriate for the current circumstances. • For example the presence of a direct access path to the data required will be preferred to a complete table scan if only 10 -20% of the table is to be accessed.
Restriction implementations Full table scan or table scan with early termination All blocks must be searched unless an early termination condition is found e.g row found and no duplicates or data is ordered and already passed the required data location. BtreeNon Clustered Index Search Tree search to starting key then linear scan of sorted keys. Assume to access each record needs a disk block read.
Multiple restrictions Conjunction And’d together If only some columns are indexed then use most selective index to locate the data record and check out the other restriction conditions in the buffer. If all columns are indexed then can get rowid’s of all records meeting the restriction conditions and perform an intersection. Use the result set of rowids to locate the data records. Disjunction Or’d together If all columns indexed get all rowid’s and perform union. Use the result set of rowids to locate the data records.Else must scan table.
Join implementations • All give the same final result set of rows as defined by the join operation. • Algorithm and cost differ. • Nested loop algorithm will function with any join condition I.e <, <=, =, >=, > • Hash algorithm only possible with = • Relation S 500 rows 50 rows per disk block • Relation R 100000 rows 50 rows per disk block
Join - Block Nested Loop Inner file pass 1 S Outer File Pass.Block Buffers Pass.Block R Inner File 1.1 2.1 1.2 2.2 1.3 2.3 1.1 1.2 Join col values equal
Join - Block Nested LoopInner file pass 2 S Outer File Pass.Block Buffers Pass.Block R Inner File 1.1 2.1 1.2 2.2 1.3 2.3 1.1 1.2 Join col values equal
Join - Block Nested Loop - Cost Cost No. Outer Loop Blocks * No. Inner Loop blocks + No. Outer Loop Blocks Use smallest table as outer loop i.e. (500/50 * 100000/50 ) + 500/50 = 20010 Reduce cost of inner loop by having :- index built on inner loop join column which is also a Primary Key - lookup avoiding full file scan – assume needs 1 disk read per row in outer file (500 / 50 + 500 ) = 510
Equi Join - Hash example Relation R 91 1 40 900 Disk Hash Buckets R [ 0] [1] Disk Hash Buckets S [0] [1] Relation S 40 101 90 1 1000 91 Value allocated to [0] if even else allocated to [1] if odd
Equi Join - Hash example Relation R 91 1 40 900 Disk Hash Buckets R [ 0] 40 900 [1] 1 91 Disk Hash Buckets S [0] 40 90 1000 [1] 101 1 91 Relation S 40 101 90 1 1000 91 Value allocated to [0] if even else allocated to [1] if odd
Equi Join - Hash cost • Only need to compare record values from matching hash buckets to find which records need joining. Assumes mechanism to retrieve required data rows. • Cost Read files in for hashing; Write out to allocated hash bucket; Read in each pair of buckets for the search for matching join values. 3 * ( No Blocks of R + No of blocks of S) 3 * ( 2000 + 10 ) = 6030
Join before restrict Example S(sno,sname,status,scity) 100 rows 20 rows/disk block SP(sno,pno,qty) 10000 rows 100/disk block 50 with pno = p2 select * from S,SP where pno = ‘p2’ and S.sno = SP.sno; Approach 1 Cost in Block I/O restrict write out after restrict 1 join nested loop 5 + (100*5) 505 S SP Total 506
Restrict before join Example Approach 2 Cost in Block I/O write out after join 1 join nested loop in RAM full scan of S 5 restrict full scan of SP 100 S SP Total 106
Three table join query branch(b_name, b_city, manager, b_address) 100 rows account(b_name, a_number, balance) 10 000 rows account_holder(h_name,a_number,h_address) 50 000 rows select h_name, balance from account a, account_holder h, branch b where a.a_number = h.a_number and a.b_name = b.b_name and b.city = ‘Leicester’ and balance > 10000;