Exploring Data
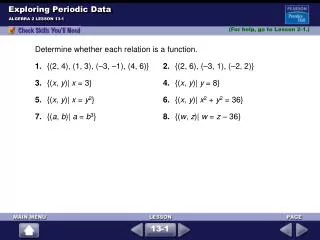
Exploring Data. 1.1 Displaying Distributions with Graphs YMS3e. 1.1 Objectives. Describe what is meant by exploratory data analysis. Explain what is meant by distribution of a variable. Differentiate between categorical variables and quantitative variables.

Exploring Data
E N D
Presentation Transcript
Exploring Data 1.1 Displaying Distributions with Graphs YMS3e
1.1 Objectives • Describe what is meant by exploratory data analysis. • Explain what is meant by distribution of a variable. • Differentiate between categorical variables and quantitative variables. • Construct bar graphs and pie charts for a set of categorical data. • Construct stemplot for a set of quantitative data. • Construct back-to-back stemplot to compare two related distributions. • Construct a stemplot using split stems. • Construct a histogram for a set of quantitative data, and discuss how changing the class width can change the impression of the data given by the histogram.
1.1 Objectives • Describe the overall pattern of a distribution by its shape, center and spread. • Explain what is meant by the mode of a distribution. • Recognize and identify symmetric and skewed distributions. • Explain what is meant by outlier in a stemplot or histogram. • Construct and interpret an ogive (relative cumulative frequency graph) from a relative frequency table. • Construct a time plot for a set of data collected over time.
Case Study • Neilsen Ratings • Read the study on page 37. • What do you observe? Does one network appear to “win” the ratings race? • How can we get a better sense of which network has the best ratings? • How can Statistics help us understand this data?
Exploratory Data Analysis • Exploratory Data Analysis: • Statistical practice of analyzing distributions of data through graphical displays and numerical summaries. • Distribution: • Description of the values a variable takes on and how often the variable takes on those values. • An EDA allows us to identify patterns and departures from patterns in distributions.
EDA • EDA is the part of statistical practice concerned with reviewing, communicating, and using data where there is a low level of knowledge about its cause system. • EDA Objectives • Suggest hypotheses about the causes of observed phenomena. • Assess assumptions on which statistical inference will be based. • Support the selection of appropriate statistical tools and techniques. • Provide a basis for further data collection through surveys or experiments.
Categorical Data • Categorical Variable: • Values are labels or categories. • Distributions list the categories and either the count or percent of individuals in each. • Displays: BarGraphs and PieCharts
SOCS • When describing a distribution remember your SOCS! • Shape • Outliers • Center • Spread
Look Carefully • Look carefully at data, searching for patterns and for situations that seem to differ from the population. • Clusters • Outliers • Gaps
Quantitative Data • Quantitative Variable: • Values are numeric - arithmetic computation makes sense (average, etc.) • Distributions list the values and number of times the variable takes on that value. • Displays: • Dotplots • Stemplots • Histograms • Boxplots Only organized Data can Illuminate! Your goal is to make neat, organized, labeled graphs that display the distribution of data effectively and provide an insight into patterns and departures from patterns.
DotPlots • Small datasets with a small range (max-min) can be easily displayed using a dotplot. • Draw and label a number line from min to max. • Place one dot per observation above its value. • Stack multiple observations evenly.
Stemplots • A stemplot gives a quick picture of the shape of a distribution while including the numerical values. • Separate each observation into a stem and a leaf. eg. 14g -> 1|4 256 -> 25|6 32.9oz -> 32|9 • Write stems in a vertical column and draw a vertical line to the right of the column. • Write each leaf to the right of its stem.
Stemplots • Example1.4, pages 42-43 • Literacy Rates in Islamic Nations
Stemplots • Note: Stemplots do not work well for large data sets • Back-to-Back Stemplots: Compare datasets • Splitting Stems: • Double the number of stems, writing 0-4 after the first and 5-9 after second. • Split them into five (0-1, 2-3, 4-5, 6-7, 8-9)
Stemplots • Example1.5, pages 42-43 • Virginia College Tuition
Example • Page 47 # 1.3: Cheese and Chemistry • As cheddar cheese matures, a variety of chemical processes take place. The taste of mature cheese is related to the concentration of several chemicals in the final product. In a study of cheddar cheese from the Latrobe Valley of Victoria, Australia, samples of cheese were analyzed for their chemical composition. • The final concentration of lactic acid in the 30 samples, as a multiple of their initial concentrations are given in the table.
Example Continued A dotplot and a stemplot from the Minitab statistical software package.
Example Continued • Which plot does a better job of summarizing the data? Explain why. • What do the numbers in the left column in the stemplot tell us? How does Minitab identify the row that contains the center of the distribution? • The final concentration of lactic acid in one of the samples stayed the same (as its initial concentration). Identify the sample in both plots.
Histograms • Histograms break the range of data values into classes and displays the count/% of observations that fall into that class. • Divide the range of data into equal-width classes. • Count the observations in each class - “frequency” • Draw bars to represent classes - height = frequency • Bars should touch (unlike bar graphs).
Histograms • Example1.6, page 49 • IQ Scores for 5th Graders Describe the SOCS What do these data suggest?
Example • Page 57 #1.11: Presidential ages at inauguration • The table gives the ages of all U.S. presidents when they took office. • Make a histogram of the ages of the presidents at inauguration. Use class intervals of 40 to 44, 45-49, and so on. Each interval should contain the left hand endpoint but not the right hand endpoint. • Describe the shape, center and spread of the distribution. • Who was the youngest president? Who was the oldest? • Was Bill Clinton, at age 46, unusually young?
AP Tip • Be sure to label carefully any required graphs. • This means your axes should be labeled and your scales should made clear. • “Describe” means to discuss shape, center and spread!
EDA Summary • The purpose of an Exploratory Data Analysis is to organize data and identify patterns/departures. • PLOT YOUR DATA - Choose an appropriate graph • Look for overall pattern and departures from pattern • Shape {mound, bimodal, skewed, uniform} • Outliers {points clearly away from body of data} • Center {What number “typifies” the data?} • Spread {How “variable” are the data values?}
Outliers • Outliers need to be looked at carefully. • Is it “bad data” that can be thrown out? • Is there a reason for that particular value to occur?
Shape • Modes • Peaks in the graph. • A distribution can be unimodal (1 peak), bimodal (2 peaks), etc… • Symmetric • The values above and below the midpoint are mirror images of each other. • Skewed • Skewed right means the tail is pulled to the right, skewed left means the tail is pulled to the left.
Frequency • Relative frequency refers to the proportion of values that fall into a certain class. • Cumulative frequency refers to the number of values that fall are contained in a class and in all classes below it. • Relative Cumulative Frequency refers to the proportion of values that fall into a class and into all classes before it. • These are graphed with an Ogive.
Example • Page 64 1.14: Glucose Levels • People with diabetes must monitor and control their blood glucose level. The goal is to maintain “fasting plasma glucose” between about 90 and 130 milligrams per deciliter (mg/dl) of blood. • Here are the fasting plasma glucose levels for 18 diabetics enrolled in a diabetes control class, five months after the end of the class.
Example continued • Make a stemplot of these data and describe the main features of the distribution. (You will want to round and split stems.) Are there outliers? How well does this group do as a whole achieving the goal for controlling glucose levels? • Construct a relative cumulative frequency graph (ogive) for these data sets. • Use your graph to answer the following questions. • What percent of blood glucose levels were between 90 and 130? • What is the center of the distribution? • What relative cumulative frequency is associated with a blood glucose level of 130?
Timeplots • A timeplot of a variable plots each observation against the time at which it was measured. • Time is on the horizontal scale • The variable you are measuring goes in the vertical scale. • Connecting the points emphasizes change over time.
Exploring Data 1.2 Describing Distributions with Numbers YMS3e
1.2 Objectives • Given a data set, compute the mean and median as measures of the center. • Explain what is meant by resistant measure. • Identify situations in which the mean is the most appropriate measure of center and situations in which the median is the most appropriate measure. • Given a data set, find the quartiles. • Given a data set, find the five-number summary. • Use the five-number summary of a data set to construct a boxplot for the data. • Compute the interquartile range (IQR) of a data set. • Given a data set, use the 1.5xIQR rule to identify outliers. • Given a data set, compute the standard deviation and variance as measures of spread.
1.2 Objectives • Give two reasons why we use squared deviations rather than just average deviations from the mean. • Explain what is meant by degrees of freedom. • Identify situations in which the standard deviation is the most appropriate measure of spread and situations in which the interquartile range is the most appropriate measure. • Explain the effect of a linear transformation of a data set on the mean, median and standard deviation of the set. • Use numerical and graphical techniques to compare two or more data sets.
Shape? Outliers? Center? Spread? Sample Data Consider the following test scores for a small class: Plot the data and describe the SOCS: What number best describes the “center”? What number best describes the “spread’?
Measures of Center • Numerical descriptions of distributions begin with a measure of its “center”. • If you could summarize the data with one number, what would it be? Mean: The “average” value of a dataset. Median: Q2 or M The “middle” value of a dataset. Arrange observations in order min to max Locate the middle observation, average if needed.
The mean and the median are the most common measures of center. If a distribution is perfectly symmetric, the mean and the median are the same. The mean is not resistant to outliers. You must decide which number is the most appropriate description of the center... Mean vs. Median MeanMedian Applet
Variability is the key to Statistics. Without variability, there would be no need for the subject. When describing data, never rely on center alone. Measures of Spread: Range - {rarely used...why?} Quartiles - InterQuartile Range {IQR=Q3-Q1} Variance and Standard Deviation {var and sx} Like Measures of Center, you must choose the most appropriate measure of spread. Measures of Spread
med Q3=29.5 Q1=23 Q1 Q3 med=79 Quartiles • Quartiles Q1 and Q3 represent the 25th and 75th percentiles. • To find them, order data from min to max. • Determine the median - average if necessary. • The first quartile is the middle of the ‘bottom half’. • The third quartile is the middle of the ‘top half’.
45 50 55 60 65 70 75 80 85 90 95 100 Quiz Scores Outlier? 5-Number Summary, Boxplots • The 5 Number Summary provides a reasonably complete description of the center and spread of distribution • We can visualize the 5 Number Summary with a boxplot.
Determining Outliers “1.5 • IQR Rule” • InterQuartile Range “IQR”:Distance between Q1 and Q3. Resistant measure of spread...only measures middle 50% of data. • IQR = Q3 - Q1 {width of the “box” in a boxplot} • 1.5 IQR Rule:If an observation falls more than 1.5 IQRs above Q3 or below Q1, it is an outlier. Why 1.5? According to John Tukey, 1 IQR seemed like too little and 2 IQRs seemed like too much...
1.5 • IQR Rule • To determine outliers: • Find 5 Number Summary • Determine IQR • Multiply 1.5xIQR • Set up “fences” Q1-(1.5IQR) and Q3+(1.5IQR) • Observations “outside” the fences are outliers.
fence: 19.06-39.99 = -20.93 outliers IQR=45.72-19.06 IQR=26.66 fence: 45.72+39.99 = 85.71 0 10 20 30 40 50 60 70 80 90 100 Spending ($) { } Outlier Example All data on p. 48. 1.5IQR=1.5(26.66) 1.5IQR=39.99
Standard Deviation • Another common measure of spread is the Standard Deviation: a measure of the “average” deviation of all observations from the mean. • To calculate Standard Deviation: • Calculate the mean. • Determine each observation’s deviation (x - xbar). • “Average” the squared-deviations by dividing the total squared deviation by (n-1). • This quantity is the Variance. • Square root the result to determine the Standard Deviation.
Standard Deviation • Variance: • Standard Deviation: • Example 1.16 (p.85): Metabolic Rates
Standard Deviation Metabolic Rates: mean=1600 What does this value, s, mean?
Linear Transformations • Variables can be measured in different units (feet vs meters, pounds vs kilograms, etc) • When converting units, the measures of center and spread will change. • Linear Transformations (xnew=a+bx) do not change the shape of a distribution. • Multiplying each observation by b multiplies both the measure of center and spread by b. • Adding a to each observation adds a to the measure of center, but does not affect spread.
Data Analysis Toolbox • To answer a statistical question of interest: • Data: Organize and Examine • Who are the individuals described? • What are the variables? • Why were the data gathered? • When,Where,How,By Whom were data gathered? • Graph: Construct an appropriate graphical display • Describe SOCS • NumericalSummary: Calculate appropriate center and spread (mean and s or 5 number summary) • Interpretation: Answer question in context!
Chapter 1 Summary • Data Analysis is the art of describing data in context using graphs and numerical summaries. The purpose is to describe the most important features of a dataset.