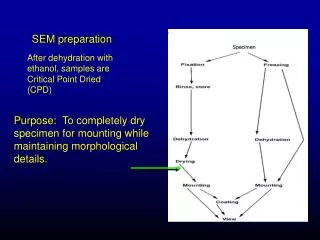
SEM
SEM. 12. Přednáška Petr Soukup. SEM - podstata. Soustava rovnic pro manifestní a latentní proměnné a pro kovarianční matici manifestních proměnných Odhadujeme parametry - zpravidla korelační a regresní koeficienty (kovariance) a rozptyly


SEM
E N D
Presentation Transcript
SEM 12. Přednáška Petr Soukup
SEM - podstata • Soustava rovnic pro manifestní a latentní proměnné a pro kovarianční matici manifestních proměnných • Odhadujeme parametry - zpravidla korelační a regresní koeficienty (kovariance) a rozptyly • Snažíme se, aby náš model byl co nejjednodušší (tj. měl co nejméně parametrů a přesto byl co nejvhodnější pro naše data – viz dále testy a kritéria)
SEM – vstupní data • Kovarianční matice manifestních proměnných – tj. rozptyly a kovariance mezi nimi • Lze vyjít i z korelační matice ale obecně se preferuje kovarianční matice (zachytí se odlišnost proměnných díky jejich různému rozptylu) • Nemusíme mít původní data, stačí získat kovarianční či korelační matici a počet respondentů (obdobně např. pro faktorovou analýzu exploračního typu v SPSS – viz např. kap 17 v Norusis) • Poznámka: Jako vstup lze mít i matici jiných než Pearsonovských korelací (tetrachorické, polychorické) a lze tak korektně pracovat s proměnnými dichotomické či ordinální povahy!!!
SEM – rovnice • Dva typy rovnic: (1. pro proměnné) • Nepřipomíná to něco?
SEM – rovnice • Dva typy rovnic: (2. pro kovariance) • Co to znamená?
SEM – rovnice • 2. typ rovnic pro kovariance je základem výpočtu • Co známe: kovarianční matici pro výběrová data u manifestních proměných (Σ) • Co chceme znát: kovarianční matici latentních proměnných (Ψ), náhodných chyb (Θ) a dále faktorové zátěže (Λ) • Problém: často máme méně prvků kovarianční matice než je odhadovaných parametrů (problém identifikovatelnosti – viz dále)
SEM – postup výpočtu • Kovarianční či korelační matici se snažíme reprodukovat modelem • Používá se různých technik odhadu – běžně v několika krocích, tzv. iterace • Nevážená metoda nejmenších čtverců:
SEM – metody odhadu I • Zobecněná metoda nejmenších čtverců: • Metoda maximální věrohodnosti:
SEM – metody odhadu II • Vážená metoda nejmenších čtverců (ADF): • Robustní metody • AMOS i MPlus umí ULS, GLS, WLS
SEM – typy parametrů • volné • pevné • omezené • ukázky
SEM – vyhodnocení modelu I • Lze vyhodnotit model jako celek – testy a kritéria • Lze vyhodnotit jednotlivé parametry – testy a intervaly spolehlivosti • Lze zjistit, zda některý parametr do modelu není vhodné přidat (ze stat. hlediska) – modification indeces
Hodnocení celkové kvality SEM modelů (model fit) • Chí-kvadrát test • Kritéria založená na měření podobnosti napozorované kovarianční matice a namodelované kovarianční matice: AGFI – cca nad 0,95 velmi dobré NNFI – opět nad 0,95 velmi dobré TLI – nad 0,9 CFI - nad 0,9 • Kritéria založená na měření chyby RMSEA – hodnoty do cca 0,05 (0,08) jsou považovány za dobré Vzorce lze nalézt např. zde: http://davidakenny.net/cm/fit.htm
Hodnocení kvality SEM modelů (model fit) • Poměr Χ2 a df – doporučená hodnota ze shora se blíží 1 (pod 1 model má moc parametrů) • Informační kritéria: Založena na věrohodnostní funkci, počtu parametrů a případně i počtu respondentů Penalizují modely s vyšším počtem parametrů (složitější) Nejužívanější je AIC a BIC AIC = Χ2 + k(k - 1) - 2df
Hodnocení kvality SEM modelů (model fit) • Doporučení pro informační kritéria U BIC rozdíl o 5 či více modely se nejspíše liší, o více než 10 téměř jistě se liší, vybíráme model s nižším BIC (platí i pro AIC) BIC lze použít i pro srovnání modelů, které nejsou tzv. nested (Exkurz o nested) Více viz: Raftery, A.E. (1995), Bayesian model selection in social research. In P.V.Marsden (Ed.), Sociological Methodology 1995. Oxford: Blackwell Diskuse AIC vs. BIC: http://emdbolker.wikidot.com/forum/t-81139/
Hodnocení parametrů • Každý parametr je odhadován společně s jeho standardní chybou • Poměrem odhadu parametru a jeho st. chyby získáme veličinu s t-rozdělením (lze testovat nulovost parametru – nepřítomnost vazby, nulovost rozptylu) • Lze konstruovat interval spolehlivosti – Jak?
Modifikační indexy a ECPI • Pro každý potenciálně zahrnutelný parametr (vazbu či rozptyl) lze zjistit, zda by se model jeho přidáním zlepšil • Toto řeší tzv. modifikační indexy • Doporučení – je-li hodnota indexu větší než 4, je ze statistického pohledu dobré parametr do modelu přidat • Praktická rada – parametry přidáváme vždy po jednom, ne tedy všechny s MI větším než 4
Problém identifikovatelnosti modelů • Teoreticky si lze představit libovolný model, ale ne vše lze spočítat • Existují nejrůznější pravidla, která je třeba dodržovat, aby bylo možné model odhadnout • Uvedeme jen ta nejjednodušší – více viz Urbánek (kap. 4) a tam zmíněná literatura, plus dále 6 pravidel (viz dále)
Identifikovatelnost - pomůcky • Model měření by měl mít pro každou latentní proměnnou alespoň tři indikátory (manifestní proměnné) • Aspoň jedna vazba indikátoru a latentní proměnné se fixuje (zpravidla na jednotku)
Jednoduchý příklad • Vychází se z kovarianční matice měřených proměnných • Počet jedinečných prvků této matice udává maximální možný počet odhadovaných parametrů • Kolik parametrů lze tedy odhadovat u dvoufaktorového modelu založeného na 6 indikátorech?
Strukturní modely - připomenutí • Zpravidla se skládají ze dvou částí: • Model měření (CFA) • Úseková analýza či její modifikace • Poznámka: nejjednodušími strukturními modely jsou kovariance, jednoduchá regrese a jednofaktorový model
Strukturní modely - ukázka • Budování modelu sociální stratifikace – viz Matějů (2005)
Strukturní modely – Model 1 Varování: Následující obrázky nedodržují zavedenou symboliku, proč?
Šest pravidel pro budování modelů (viz SEM.pdf) • Pravidlo 1. Rozptyly nezávislých veličinjsou odhadované parametry (jde zejména o latentní proměnné v modelech měření a dále chybové složky) • Poznámka: Ke každé závislé veličině zpravidla patří chybová složka, její rozptyl určuje co se nedaří vysvětlit za pomoci našeho modelu • Pravidlo 2. Kovariance nezávislých proměnnýchjsou odhadované parametry (pokud teorie nepředpokládá nezávislost či určitou velikost této vazby)
Šest pravidel pro budování modelů (viz SEM.pdf) • Pravidlo 3. Všechny možné faktorové zátěže v modelech měřeníjsou odhadované parametry (opět pokud teorie nepředpokládá, že některé vazby jsou vyloučeny) • Poznámka: Běžně jsou např. ve dvoufaktorovém modely některé indikátory pro první faktor a jiné pro druhý a vzájemné křížení se nepřipouští • Pravidlo 4. Regresní koeficienty mezi latentními nebo pozorovanými proměnnýmijsou odhadované parametry (opět toto neplatí, pokud teorie nepředpokládá nezávislost či určitou velikost této vazby)
Šest pravidel pro budování modelů (viz SEM.pdf) • Pravidlo 5. Rozptyly a kovariance mezi závislými proměnnými a kovariance mezi závislými a nezávislými proměnnými nejsou nikdy odhadované parametry (bez výjimek, vyplývá z logiky modelování) • Pravidlo 6. U každé latentní proměnné v modelu je nutno nastavit její škálu. Důvod: žádnou přirozenou škálu na rozdíl od manifestních proměnných nemá. Dvě možnosti: fixovat rozptyl (typicky na 1), nebo fixovat vazbu z ní vycházející k proměnné (typicky na 1).
Aplikace pravidel na jednoduchý model • Aplikujte pravidla 1-6 na dvoufaktorový model • Kolik maximálně parametrů se bude odhadovat? • Jaká pravidla se použijí a která se nepoužijí? • Jak bude vypadat realistický model měření, kolik parametrů se bude odhadovat?