
Revolutionizing Embedded Systems with Vector-Thread Architecture for Enhanced Performance
The Vector-Thread (VT) architecture integrates vector and multithreaded compute models to optimize modern embedded systems, such as smartphones, servers, and IoT devices. By utilizing a control processor interacting with a vector of virtual processors (VPs), VT achieves competitive performance and energy efficiency. Featuring unified software programming and dynamic memory access, it supports various applications, from wireless transmission to multimedia processing. This architecture addresses inefficiencies in traditional designs and introduces flexible options for scalable embedded solutions with improved instruction fetching and data management.

Revolutionizing Embedded Systems with Vector-Thread Architecture for Enhanced Performance
E N D
Presentation Transcript
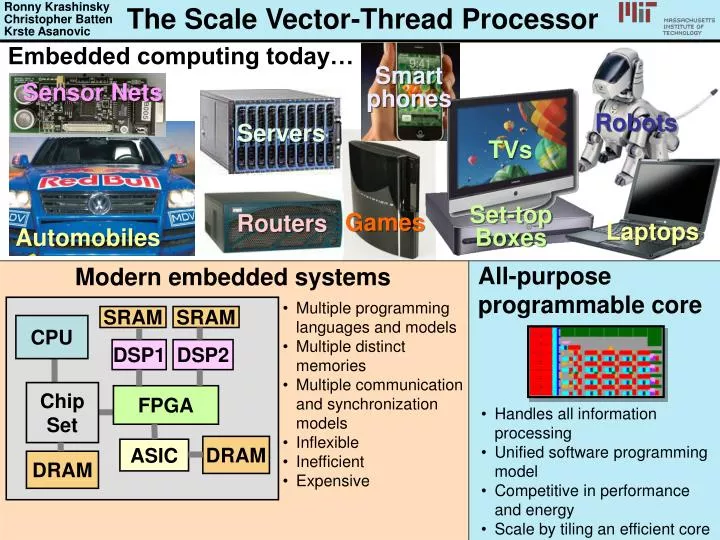
Ronny Krashinsky Christopher Batten Krste Asanovic The Scale Vector-Thread Processor Embedded computing today… Smart phones Sensor Nets Robots Servers TVs Set-top Boxes Games Routers Laptops Automobiles Modern embedded systems All-purpose programmable core • Multiple programming languages and models • Multiple distinct memories • Multiple communication and synchronization models • Inflexible • Inefficient • Expensive SRAM SRAM CPU DSP1 DSP2 ChipSet FPGA • Handles all information processing • Unified software programming model • Competitive in performance and energy • Scale by tiling an efficient core DRAM ASIC DRAM
Vector-Thread Architecture vector-fetch Control Processor thread- fetch VP0 VP1 VP2 VP3 VPN Memory • VT unifies the vector and multithreaded compute models • A control processor interacts with a vector of virtual processors (VPs) • Vector-fetch: control processor fetches instruction blocks for all VPs in parallel • Thread-fetch: a VP fetches its own instruction blocks • VT allows a seamless intermixing of vector and thread control Vector Execution Threaded Execution VP3 VP3 Control Proc. VP1 VPN Control Proc. VP1 VPN VP2 VP2 VP0 VP0 vector-load vector-load vector-fetch vector-fetch vector-store vector-load vector-fetch vector-store vector-store
Control Processor (CP) – scalar RISC core • Vector-Thread Unit – 4 lanes, 16 decoupled clusters, instruction fetch, load/store, and command management units, up to 128 VP threads • Vector-Memory Unit – unit-stride, strided, and segment loads and stores, refill/access decoupling • Cache – 4-port, non-blocking, 32-way set-associative, 32 KB Lane 0 Lane 1 Lane 2 Lane 3 CMU CMU CMU CMU C3 C3 C3 C3 C2 C2 C2 C2 • Automatic synthesis, place & route • Preplaced standard cells, RAM blocks • Aggressive clock-gating • Iterative design flow • Verification: formal equiv. check + sim. Register File 32x32-bit Cache Tags Cache Control C1 C1 C1 C1 Instr. cache 32x46-bit Control Logic Datapath 32-bit C0 C0 C0 C0 • TSMC 180 nm, 6 layers Al • 7.1 M trans., 1.4 M gates, 397 K cells, 300 k RAM bits • 16.6 mm2 core area, 23.1 mm2 chip area • 260 MHz at 1.8 V, 600 mW typical • 24 person-months design effort SD SD SD SD CP Vector-Mem Unit Read/Write Crossbars • Vectorizable data processing applications, • e.g. 802.11a wireless transmitter: 9.7 ops per cycle • Non-vectorizable encoder/decoder algorithms, • e.g. ADPCM speech decompression: 6.5 ops per cycle • Threaded IP routing table lookups: 6.1 ops per cycle 32 KB SRAM 3mm





















