Download

1 / 10
100 likes | 226 Vues
This paper presents a solution for efficiently processing multi-keyword queries using heavy-tailed distributions in inverted indexes. Given the challenge of costly deep traversal in long inverted lists, our approach aims to reduce the worst-case overhead for arbitrary keyword queries. By proposing a novel index structure and processing strategies, we can improve query performance significantly without excessive storage of additional indexes. The results demonstrate speedups in query processing times and offer insights into the intersection size estimation with high accuracy.

E N D
Heavy-Tailed Distribution and Multi-Keyword Queries SurajitChaudhuri, Kenneth Church, Arnd Christian K ö nig, Liying Sui Microsoft Corporation SIGIR 2007 2008. 07. 31. Summarized by JongHeumYeon, IDS Lab., Seoul National University
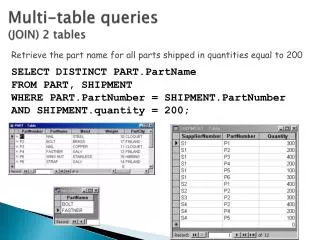
INTRODUCTION • Inverted Index in Information Retrieval • T0 = "it is what it is“, T1 = "what is it“, T2 = "it is a banana“ • "a": {2}, "banana": {2}, "is": {0, 1, 2}, "it": {0, 1, 2}, "what": {0, 1} • Search “what”, “is”, “it” • {0,1} ∩{0,1,2} ∩{0,1,2} = {0,1} • Some queries require costly deep traversal into long lists in web-sites(Amazon, eBay, …) with large catalogs of products • The challenge is to reduce the worst-case overhead required to process arbitrary keyword queries
Motivating Scenario • More frequent terms have relatively long inverted lists • Intersections of long inverted indexes are very slow relative to other queries • Figure • 20 million products • Frequency : F(>900K)-M(50K)-L(<1K)
Problem Statement Given a document collection, propose a set of indexes to materialize Time for intersecting keywords does not exceed a given threshold Δ Additional indexes should not be larger than k(small factor) times the size of the original inverted index
INDEX STRUCTURE AND USAGE • Notation • Query Q • words(Q) = {w1, … , wl} • kmax : maximum number of terms in query • γ : global vocabulary • π : global ordering • Given keyword-combination C = {w1, … , wl}, sort words by global ordering for avoiding permutations of keyword-combination • size(Q) : number of items(=document) whose text contains all keyword of a query Q • size(w) : single word w, number of documents containing w • |Q| : number of keywords a query Q contains
Cost Model • Cost • Disk seeks to the beginning of posting lists + • Scanning postings • Unit of cost : scanning a single posting in an inverted index • Δ : Cost bound
Processing Strategies • Execution Strategies • ID-intersection • Retrieves all inverted indexes of the queried keywords and intersects them • |Q| seeks accesses to disk, reading their contents entirely • Post-filtering • When wi in Q is very rare, • Reading text of wi by inverted index, then verifying the remaining keyword constraints using text
Index Structure materialize combinations of frequent keywords and a small fraction of them For each vocabulary items w, a list of all keyword combinations containing w for which they have materialized the corresponding inverted index
Query Processing Query Q = {w1, … , wl} Q contains rare keyword : post-filtering strategy Otherwise : retrieve all match-list entries
EXPERIMENTS • Evaluation of Query Cost • Materialized the index structure : 10K frequent words • Kmax = 4, CostSeek = 1000 • Δ : cost of scanning 20% of the number of postings • Speed-ups • 18x (2 keywords) • 14x (4 keywords) • Evaluation of Index Sizes • 899M postings • No additional indexes for keywords occurring in less than 50 documents • 141K keywords for indexing • Multi-keyword index structures contained 734M postings • Accuracy of Intersection-size Estimation • Match list covers 99.3%