Statistische Lernmethoden
Statistische Lernmethoden. Bayes‘sches Lernen MAP Maximum Likelihood Hauptquelle: Artificial Intelligence: A Modern Approach Stuart J. Russel, Peter Norvig. Beispiel 1. Gegeben: 2 Arten von Bonbons (Kirsche, Zitrone) 5 Arten von Bonbontüten(äußerlich ununterscheidbar):


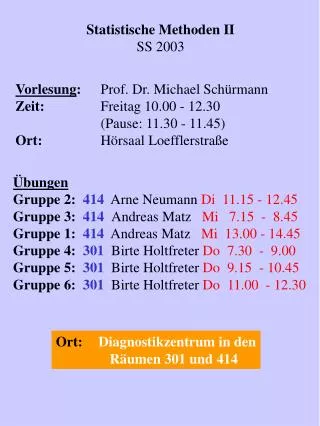
Statistische Lernmethoden
E N D
Presentation Transcript
Statistische Lernmethoden Bayes‘sches Lernen MAP Maximum Likelihood Hauptquelle: Artificial Intelligence: A Modern Approach Stuart J. Russel, Peter Norvig
Beispiel 1 Gegeben: 2 Arten von Bonbons (Kirsche, Zitrone) 5 Arten von Bonbontüten(äußerlich ununterscheidbar): • 100% Kirsche (h1) • 75% Kirsche, 25% Zitrone (h2) • 50% Kirsche, 50% Zitrone (h3) • 25% Kirsche, 75% Zitrone (h4) • 100% Zitrone (h5) Optional: (Vom Hersteller) gegebene Häufigkeitsverteilung der verschiedenen Tütensorten
Beispiel 1 Erhebung von Daten = Herausnehmen einzelner Bonbons und „prüfen“ des Geschmacks d = d1, … , dNsind die Daten di = kirsche oder di = zitrone h1, … , h5 sind die Hypothesen Aufgabe / Problemstellung: Vorhersage des nächsten (bzw. der nächsten) Bonbons
Bayes‘sches Lernen Bayes‘sches Lernen: Berechnen der Wahrscheinlichkeit jeder Hypothese und Vorhersage auf dieser Basis ALLEHypothesen werden (gewichtet nach ihrer jeweiligen Wahrscheinlichkeit) verwendet, nicht nur eine „beste“ Hypothese
Beispiel 1 (1) P(hi|d) = αP( d|hi) P(hi) mit α = P(d)-1 (2) => Vorhersage = gewichteter Mittelwert der Vorhersagen der Einzelhypothesen
Beispiel 1 Grundannahme bei diesem Beispiel: Das Auswerten von Daten verändert nicht die Bonbonanteile in der untersuchten Bonbontüte, d.h. die einzelnen „Bonbonziehungen“ sind voneinander (stochastisch) unabhängig Dann gilt: P(d|hi) = P(d1|hi) P(d2|hi)…P(dn|hi)
Beispiel 1 Die (a-priori-) Wahrscheinlichkeiten für h1,…,h5 seien z.B. ( 0,1 ; 0,2 ; 0,4 ; 0,2; 0,1 ) Die ersten 10 gezogenen Bonbons seien allesamt Zitronenbonbons: d = (d1,…,dn) = (zitrone,…,zitrone) Unter der Annahme einer jeden Hypothese hat eine solche Ziehung dann eine bestimmte Wahrscheinlichkeit, so z.B. P(d|h3) = 0,510
Entwicklung der a-posteriori-Wahrscheinlichkeiten der Hypothesen und der Vorhersage P(hi|d) = αP(d|hi) P(hi)
Dominanz der wahren Hypothese bei der Bayes‘schen Vorhersage Typischer Effekt: wahre Hypothese dominiert nach einer bestimmten Datenmenge die Bayes‘sche Vorhersage „Grund: Die Wahrscheinlichkeit, durch Zufallsziehungen uncharakteristische Daten zu produzieren, wird mit zunehmender Datenmenge verschwindend gering.“
Bewertung des Bayes‘schen Lernens Bayes‘sches Lernen ist insofern optimal, als dass jede andere Vorhersagemethode weniger oft richtig liegen würde. Der Preis dafür: in realen Situationen gibt es meist zuviele Hypothesen und die Summenbildung (im kontinuierlichen Fall: Integration) in Gleichung (2) ist nicht (oder nicht effizient) durchführbar => Notwendigkeit einer sinnvollen Approximation
MAP-Approximation Populäre Approximationsmöglichkeit: Vorhersage auf Basis EINER wahrscheinlichsten Hypothese D.h., bei gegebenen Daten wird diejenige Hypothese hi zur Vorhersage herangezogen, die P(hi|d) maximiert („maximum a posteriori hypothesis“, hMAP)
MAP-Approximation Im obigen Beispiel 1 wäre damit nach 3 geprüften Bonbons die Vorhersage aller folgenden Bonbons durch MAP, dass mit Wahrscheinlichkeit 1,0 Zitronenbonbons folgen werden ( sicherlich eine viel gefährlichere Prognose als die vom reinen Bayesverfahren zu diesem Zeitpunkt berechnete Wahrscheinlichkeit von 0,8 für Zitronenbonbons )
Vergleich MAP & Bayes Vorhersagen des reinen Bayesverfahrens und MAP nähern sich mit zunehmender Datenmenge an In vielen realen Situationen ist die Vorhersage durch hMAP deutlich einfacher bestimmbar
Weitere Vereinfachung Eine weitere populäre Vereinfachung wird angewendet, wenn alle Ausgangshypothesen gleich wahrscheinlich sind bzw. keine genaueren Vorkenntnisse vorhanden sind. Dadurch reduziert sich MAP, also die Maximierung von P(hi|d) = αP(d|hi) P(hi) auf eine Maximierung von P(d|hi)
Maximum Likelihood Diese Methode wird als Maximum-Likelihood-Methode bezeichnet und die auf diese Weise bestimmte und zur Vorhersage verwendete Hypothese hML bzw. ML-Hypothese Die so gewonnene Vorhersage ist in aller Regel eine gute Näherung zur Bayes‘schen und MAP-Vorhersage, sofern die Datenmenge groß genug ist
Beispiel 2 Gegeben: Wie Beispiel 1, aber diesmal gibt der Hersteller keine Proportionen (Tütensorten) an. • Kontinuum von Hypothesen anstatt diskreter Hypothesenmenge • Parameterθ ist Anteil der Kirschbonbons in der untersuchten Tüte, mögliche Hypothesen heißen hθ • A priori sind alle hθ gleich wahrscheinlich, also wird ML-Methode angewendet
Beispiel 2 Daten: N geöffnete Bonbons, c davon Kirsche, l = N-c Zitrone P(d|hθ) = P(d1|hθ)…P(dN| hθ) = θc(1-θ)l ML-Hypothese durch θ gegeben, welches P(d|hθ) maximiert L(d|hθ) = log P(d|hθ) = c log θ+l log (1-θ)
Beispiel 2 Bestimmung des Maximums dieser Funktion: hML ist (wie erwartet) die Hypothese, dass der Anteil der Kirschbonbons in der Tüte gleich dem beobachteten Anteil der Kirschbonbons unter den geprüften Bonbons ist
Allgemeine Vorgehensweise Das Beispiel ist zwar einfach, stellt aber die wesentlichen Schritte der allgemeinen Methode gut dar: • Ausdruck für Wahrscheinlichkeit der Daten als Funktion der Parameter finden • Den Logarithmus dieser Funktion nach jedem Parameter ableiten • Maximierende Parameter als Nullstellen der Ableitung bestimmen(insbesondere dieser letzte Schritt ist in der Praxis häufig der schwierigste)
Probleme der ML-Methode Ebenfalls zeigt das Beispiel schon eines der Hauptprobleme der Methode auf: Bei geringer Datenmenge (wenn z.B. einige mögliche Variablenwerte noch kein einziges mal vorkamen) ergibt die ML-Methode 0-Wahrscheinlichkeiten für diese Ereignisse, was häufig nicht der Realität entspricht Eine mögliche Lösung ist das vorherige Initialisieren aller Ereigniszähler auf 1 (sodass jeder mögliche Variablenwert zumindest ein Mal in die Rechnung einfließt)
Beispiel 3 (mehrere Parameter) Gegeben: Gleiche Situation wie in Beispiel 2, aber als „Hinweis“ färbt der Hersteller das Bonbon-papier eines jeden Bonbons in probabilistischer Abhängigkeit vom Bonbongeschmack: F = Farbe, G = Geschmack P(G = kirsche) = θ P(F=rot|G = kirsche) = θ1, P(F=rot|G = zitrone) = θ2 Dies ist also ein Modell mit 3 Parametern und den möglichen Hypothesen hθ,θ1,θ2
Beispiel 3 (mehrere Parameter) Wie vorher wird wieder von N geöffneten Bonbons ausgegangen, wovon c Kirsch- und l Zitronengeschmack haben. Außerdem sind rc der Kirschbonbons in rotem Bonbonpapier, gc in grünem vorgefunden worden, entsprechend rl bzw. gl für die Zitronenbonbons.
Beispiel 3 (mehrere Parameter) P(d|hθ,θ1,θ2) = θc(1-θ)lθ1rc(1-θ1)gc θ2rl(1-θ2)gl L(d|hθ,θ1,θ2) = c log θ + l log (1-θ) + rc log θ1+ gc log (1-θ1) + rl log θ2 + gl log (1-θ2)
Vollständige Daten => unabhängige Gleichungen Beobachtung an diesem Beispiel (gilt auch im Allgemeinen): Vollständige Daten (d.h. wenn jeder Mess- bzw. Datenpunkt Werte für alle involvierten Variablen enthält) führen zu unabhängigen Gleichungen (und sind daher gut lösbar)
Zusammenfassung • Bayes‘sches Lernen ist in einem bestimmten Sinn optimal, was aber durch eine in der Realität häufig ineffiziente und unpraktikable Rechnung (in Form von Summenbildung über sehr viele Summanden oder schwierige Integration) erkauft wird. • Die MAP-Methode ist eine sinnvolle Näherung an Bayes‘sches Lernen, deren Güte allerdings von der verfügbaren Datenmenge abhängt. Sie ist häufig deutlich leichter berechenbar, kann aber bei geringer Datenmenge ausartende Ergebnisse liefern, was nur teilweise durch Modifikationen an der Methode ausgeglichen werden kann. • Die Maximum-Likelihood-Methode ist ein Spezialfall der MAP-Methode und hat damit weitgehend die gleichen Vor- und Nachteile. Sie ist noch einfacher berechenbar, vernachlässigt allerdings jegliches eventuelle Vorwissen über die a-priori-Wahrscheinlichkeitsverteilung der verfügbaren Hypothesen.