Efficient Strategies in High-Throughput Screening and Compound Analysis Workshop
Join us for a workshop on sequential screening paradigms focusing on corporate and virtual compound collections. Delve into various statistical methods, chemical descriptors, and data sets to enhance your analysis of initial, selected, and active compounds. The workshop will include sessions on design and analysis, pooling discussions, and general discussions led by experts Will and Stan. Participants will explore software needs and the integration of statistical and machine learning techniques to optimize bioactivity, minimize costs, and diversify chemical classes in drug discovery.


Efficient Strategies in High-Throughput Screening and Compound Analysis Workshop
E N D
Presentation Transcript
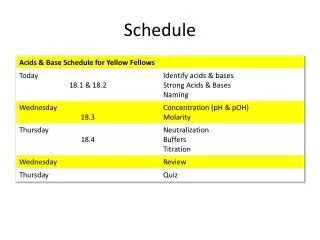
Schedule 8:30-9:30 Introduction 9:40- 10:45 Analysis Methods 10:55-12:00 Design and Analysis 12:00 Lunch 1:00-2:05 Design and Analysis I (Will and Stan) 2:15-3:15 Pooling 3:25-4:00 Pooling Discussion 4:00-4:30 General Discussion
HTS Directions NISS Affiliates Workshop 25 October 2002
Sequential Screening Paradigm Corporate Collection Commercial Compounds Virtual Compounds Stat Methods Chem Descriptors Model Data Sets Filters Statistical Model Statistical Analysis Initial Compounds Screen Compounds Selected Compounds Active Compounds
Data / Descriptors / Stat Method Data : Protein binding Cell-based Whole Animal, e.g. Toxicology Descriptors : BCUT, Atom Type Counts, Topological, 3D, etc. Analysis : LR, PLS, RP, NN, Latent Class, SVM, etc. Combined (e.g. RP and LR)
Data Sets –Need for benchmarking data sets Binding : NCI Cell-based: none Tox : Mutagenicity, others Pooled : none
Software Needs Compound viewer/editor: MolViewer : JMP/smiles Descriptor Calculations: Dragon? Environment to code new algorithms: R, MatLab, MOE Standard stat methods: SAS, S, R, JMP Special Data Mining Code : ChemTree, CompChem vendors LeadScope, BioReason, etc.
Sequential Screening Paradigm Corporate Collection Commercial Compounds Virtual Compounds Stat Methods Chem Descriptors Model Data Sets Filters Statistical Model Statistical Analysis Initial Compounds Screen Compounds Selected Compounds Active Compounds
Focused, knowledge-based No knowledge => Diverse Redundant to support analysis Large enough to start process Random is generally OK! Initial Sample
Rational Screening Goals • Optimize bioactivity, (increase selectivity) • Reduce the cost of experimental data • Increase the number of “active” classes • Increase speed of knowledge acquisition
Find all active compounds. Cost is no object. Time is no object. Find every active class. Irrational Screening Goals
Literature DM Hawkins, SS Young and A Rusinko. “Analysis of a Large Structure-Activity Data Set Using Recursive Partitioning”QSAR 16:296-302 (1997). MJ Valler and D Green. “Diversity screening versus focussed screening in drug discovery”Drug Discovery Today 5:286-293 (2001). MFM Engels and P Venkatarangan. “Smart screening: Approaches to efficient HTS”Current Opinions in Drug Discovery&Development 4:275-283 (2001)