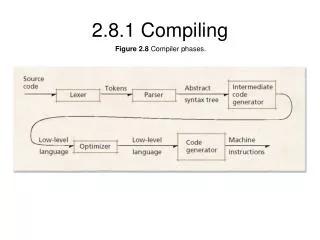
Compiling for VIRAM
Learn about the VIRAM Compiler by UC Berkeley, its current status, frontends, optimizer, code generators, testing results, kernel performance, future features, and more. Stay informed on the development of this versatile compiler for C and C++ programming languages with a focus on vectorization and performance enhancements.


Compiling for VIRAM
E N D
Presentation Transcript
Compiling for VIRAM Dave Judd Kathy Yelick Computer Science Division UC Berkeley
VIRAM Compiler • Based on Cray Inc production compiler • Used on the T90, C90, as well as the T3D and T3E • Being ported by Cray Inc to the SV2 architecture • C, C++, and Fortran 95 front-ends • Fortran not supported in VIRAM • Extensive vectorization, restructuring capability • VIRAM code generator based on new SV2 code generator • SV2 code gen being developed in parallel w/ VIRAM • SV2 vector architecture similar to VIRAM
VIRAM Compiler Status Frontends Optimizer Code Generators • VIRAM vector & MIPS scalar support • Compiles & executes C & C++ commercial test suites • Compiles and executes several Cray vector C test suites C T3D/T3E C++ PDGCS C90/T90/SV1 Fortran95 SV2/VIRAM
Progress Since Winter Retreat • “-n32” ABI implemented, replacing “–64” • C++ support, modena test suite • Code scheduler • Code cleanup for vl, mvl, vbase, vinc registers • Sync support partially implemented • Addl. “vector4” test suite executes correctly • Eliminate dependency on Cray include files • Vectorize loops w/ 8, 16 bit data • A “few” bugs fixed
Compiler Testing • C regression test suite (commercial test suite) • Scalar emphasis, C conformance • All tests pass except: • Small numerical differences due to lack on 128 f.p. support • C++ test suite • 1167 of 1183 tests execute correctly. • 12 failures in compilation: “undefined variables” • 4 failures in execution: bad answers
Compiler Testing • Vector regression test suites (CRAY) • Specifically tests for vectorization • Compares vector and scalar results • Easy to isolate problems • “vector” status: • 59 of 62 tests pass • Some minor numerical differences • 1 bad answer, 2 integer overflow • “vector4” status • 163 of 165 tests execute correctly • 1 bad anwer, 1 illegal use of vector inst.
Kernel Performance: mvmmatrix-vector multiplication 64x64, 32 bit floating pt.
Mods to mvm code /* Original code mvm.c */ /* Modified code */ void mvm (float * A, void mvm (float * restrict A, float * X, float * restrict X, float * Y, float * restrict Y, int n, int n, int acol ) { int acol ) { int i,j; int i,j; float x_elem < if ( n <= 64 ) { if ( n <= 64 ) { for (i = 0; i < n; i++) { for (i = 0; i < n; i++) {#pragma shortloop for (j = 0; j < n; j++) { for (j = 0; j < n; j++) { Y[j] += A[j*acol+i] * x_elem; Y[j] += A[j*acol+i] * X[i]; } } } } } }} }
Kernel performance: mm_mulmatrix –matrix multiplication • 64x64x64, 32 bit float, 1.6 gigaflop theoretical peak
Kernel performance: saxpy • 32 bit floating point ops
Kernel performance: motion_estimate 32 bit integer ops, finding the minimum sum of absolute differences for a reference block and a region in an image. *No improvement because of spilling.
Dongarra loops • 100 loops to test compiler vectorization capability • Rewritten in C by Cray (?) • vcc vectorizes 74 loops • vcc partially vectorizes 3 loops • vcc conditionally vectorizes 3 loops • 1 loop not vectorized because vector sin/cos not currently available on viram. • 19 other loops not vectorized • Data provided by Sam Williams
Features Remaining: • Support version 3 isa and version 4 isa: • Isa changes required by Mips Inc. scalar core • Performance simulator only supports “old”isa • Finish sync support • take advantage of Cray implementation • VIRAM machine “target” • Allow easier maintainence of frontend and optimizer mods for viram • User documentation • Summary of differences w/Cray compiler • Useful options, hints for vector code
Performance Features Remaining • Additional tuning: instruction scheduler • Support new SV2 inliner for C/C++ • Shortloop enhancements • Reduce spilling • Scheduler concern with registers • Ordering of blocks for register assignment within “priority groups” • Special vector registers carried across calls • Loop unrolling for vector loops • Tune for key benchmarks
Other Future Compiler Features ? • Support for speculative execution • Compiler extensions for fixed point hardware • Support for vector functions; vector mlib
Summary • vcc is a reasonably robust compiler for VIRAM • Performance on kernels is good w/appropriate directives, some effort for optimum vectorization • Need to prioritize remaining work
Virtual Processors (vl) VP0 VP1 VPvl-1 vr0 vr1 Data Registers vr31 vpw Vector Architectural State • Number of VPs given by the Vector Length register vl • Width of each VP given by the register vpw • vpw is one of {8b,16b,32b,64b} • Maximum vector length is given by a read-only register mvl • mvl depends on implementation and vpw: {128,128,64,32} in VIRAM-1
Codegen/optimizer issues for VIRAM • Variable virtual processor width (VPW) • Variable maximum vector register length (MVL) • Vector flag registers treated as 1 bit wide vector register • Multiple base, incr, stride regs. + autoincrement • Fixed point arithmetic (saturating add, etc.) • Memory consistency • New vector instructions not available on SV2
Generating Code for Variable VPW • Strategy: vectorizer determines minimum correct vpw for each loop nest • Vectorizer assumes vpw=64 initially • At end of vectorization, discard vectorized copy of loop if greatest width encountered is less than 64 and start vectorization over with new vpw. • Code gen checks vpw for each loop nest. • Limitation: a single loop nest will run at the speed of the widest type. • Reason: simplicity & performance of the common case • No attempt to split/combine loops based on vpw
Generating Code for Variable MVL • Maximum vector length is not specified in IRAM ISA. • However, compiler assumes mvl at compile time • mvl based on vpw • mvl assumption dependent on VIRAM-1 hardware implementation • Recompiling required for future hardware versions if mvl changes • MVL knowledge useful for code gen and vectorizer: • register spilling • short loop vectorization • length-dependent vectorization ( and may eliminate safe vector length computation at run time) for (i = 0; i < n; i=++) a[i] = a[i+32]
Memory consistency • Sync instructions: SaV VaS VaV vp RaW WaR WaW
VIRAM Tools • vas: assembler • vdis: disassembler • vsim-isa: simulator • vsim-db: debugger • vsim-p: performance simulator • vsim-sync:memory consistency simulator
vsim-sync • Intended for debugging and optimizing sync’s • Tells you when there is a data hazard (sync needed) • Tells you when a sync executed that didn’t prevent a hazard; • sync may not be needed • according to dynamic execution • sync may be needed on some other execution path