Download

1 / 14
140 likes | 357 Vues
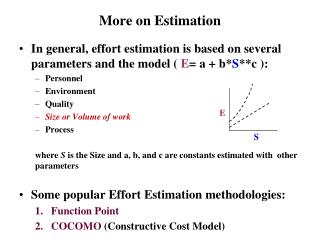
On Synopses for Distinct-Value Estimation Under Multiset Operations. Kevin Beyer Peter J. Haas Berthold Reinwald Yannis Sismanis IBM Almaden Research Center Rainer Gemulla Technische Universität Dresden. Introduction. Estimating # Distinct Values (DV) crucial for:

E N D
On Synopses for Distinct-Value Estimation Under Multiset Operations Kevin Beyer Peter J. Haas Berthold Reinwald Yannis Sismanis IBM Almaden Research Center Rainer Gemulla Technische Universität Dresden
Introduction • Estimating # Distinct Values (DV) crucial for: • Data integration & cleaning • E.g. schema discovery, duplicate detection • Query optimization • Network monitoring • Materialized view selection for datacubes • Exact DV computation is impractical • Sort/scan/count or hash table • Problem: bad scalability • Approximate DV “synopses” • 25 year old literature • Hashing-based techniques SIGMOD 07
Motivation: A Synopsis Warehouse Full-Scale Warehouse Of Data Partitions Synopsis • Goal: discover partition characteristics & relationships to other partitions • Keys, functional dependencies, similarity metrics (Jaccard) • Similar to Bellman [DJMS02] • Accuracy challenge: small synopses sizes, many distinct values Synopsis Synopsis Warehouse of Synopses S1,1 S1,2 Sn,m combine etc S*,* S1-2,3-7 SIGMOD 07
Outline • Background on KMV synopsis • An unbiased low-variance DV estimator • Optimality • Asymptotic error analysis for synopsis sizing • Compound Partitions • Union, intersection, set difference • Multiset Difference: AKMV synopses • Deletions • Empirical Evaluation SIGMOD 07
k-min 0 1 U U ... U (1) (2) (k) 1/D hash K-Min Value (KMV) Synopsis Partition a • Hashing = dropping DVs uniformly on [0,1] • KMV synopsis: • Leads naturally to basic estimator [BJK+02] • Basic estimator: • All classic estimators approximate the basic estimator • Expected construction cost: • Space: b a X a X X X X X X X X X … e D distinct values SIGMOD 07
Contributions: New Synopses & Estimators • Better estimators for classic KMV synopses • Better accuracy: unbiased, low mean-square error • Exact error bounds (in paper) • Asymptotic error bounds for sizing the synopses • Augmented KMV synopsis (AKMV) • Permits DV estimates for compound partitions • Can handle deletions and incremental updates Synopsis A SA Combine SAop B Aop B Synopsis SB B SIGMOD 07
Unbiased DV Estimator from KMV Synopsis • Unbiased Estimator [Cohen97]: • Exact error analysis based on theory of order statistics • Asymptotically optimal as k becomes large (MLE theory) • Analysis with many DVs • Theorem: • Proof: • Show that U(i)-U(i-1) approx exponential for large D • Then use [Cohen97] • Use above formula to size synopses a priori SIGMOD 07
Outline • Background on KMV synopsis • An unbiased low-variance DV estimator • Optimality • Asymptotic error analysis for synopsis sizing • Compound Partitions • Union, intersection, set difference • Multiset Difference: AKMV synopses • Deletions • Empirical Evaluation SIGMOD 07
U (k) (Multiset) Union of Partitions k-min k-min LA LB X X X X X X X X 0 … 1 0 … 1 k-min L X X X X X X X X X 0 … 1 • Combine KMV synopses: L=LALB • Theorem: L is a KMV synopsis of AB • Can use previous unbiased estimator: SIGMOD 07
(Multiset) Intersection of Partitions • L=LALB as with union (contains k elements) • Note: L corresponds to a uniform random sample of DVs in AB • K = # values in L that are also in D(AB) • Theorem: Can compute from LA and LB alone • K/k estimates Jaccard distance: • estimates • Unbiased estimator of #DVs in the intersection: • See paper for variance of estimator • Can extend to general compound partitions from ordinary set operations SIGMOD 07
L+E=(LE,cE) AKMV Synopsis E L+G=(LE LF,hop(cE,cF)) G=Eop F Combine AKMV Synopsis F L+F=(LF,cF) Multiset Differences: AKMV Synopsis • Augment KMV synopsis with multiplicity counters L+=(L,c) • Space: M=max multiplicity • Proceed almost exactly as before i.e. L+(E/F)=(LELF,(cE-cF)+) • Unbiased DV estimator: Kg is the #positive counters • Closure property: • Can also handle deletions SIGMOD 07
0.1 0.08 0.06 Average ARE 0.04 0.02 0 SDLogLog Unbiased-KMV Sample-Counting Baseline Accuracy Comparison SIGMOD 07
500 400 300 200 100 0 0 0.10 0.05 0.15 ARE Compound Partitions Unbiased-KMV/Intersections Unbiased-KMV/Unions Unbiased-KMV/Jaccard SDLogLog/Intersections SDLogLog/Unions SDLogLog/Jaccard Frequency SIGMOD 07
Conclusions • DV estimation for scalable, flexible synopsis warehouse • Better estimators for classic KMV synopses • DV estimation for compound partitions via AKMV synopses • Closure property • Theoretical contributions • Order statistics for exact/asymptotic error analysis • Asymptotic efficiency via MLE theory A new spin on an old problem SIGMOD 07