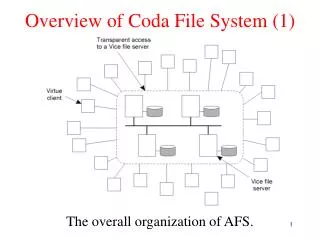
File Access Patterns in Coda Distributed File System
File Access Patterns in Coda Distributed File System. Yevgeniy Vorobeychik. Outline. Terminology Motivation Project Description Related Work Case Analysis Experimental setup DFSTrace Custom Perl library Process Results Analysis Implications Flaws and Limitations Future Work.


File Access Patterns in Coda Distributed File System
E N D
Presentation Transcript
File Access Patterns in Coda Distributed File System Yevgeniy Vorobeychik
Outline • Terminology • Motivation • Project Description • Related Work • Case Analysis • Experimental setup • DFSTrace • Custom Perl library • Process • Results • Analysis • Implications • Flaws and Limitations • Future Work
Terminology • DFS: Distributed File System • CMU: Carnegie Mellon University • Coda: DFS created at CMU • (File) Caching: storing replicas of files locally • Unstable files: files that are frequently updated • Peer-to-peer network: network with no central server • Ousterhout, Baker, Sandhu, Zhou: last names of people
Motivation • File caching has long been used as a technique to improve DFS performance • When a cached copy is updated, it has to be written back to the server at some point • Or does it? • What if you have a peer-to-peer network? • What if there are many unstable files?
Motivation • What if there is a “very small” set of computers that update a file? • Then you can avoid writing back to the server, reducing server load (if there is a server at all) • Members of the “writers” group can synchronize the file amongst themselves • Clients can contact a member of the “writers” group directly for an updated version of the file • What does “very small” mean? • Reduction in server load should justify the amount of intra-group synchronization • I make a very conservative assumption that “very small” = 1
Project Description • In this project I tried to determine access patterns that can be observed in Coda Distributed File System • Used Coda traces collected continuously for over 2 years at CMU • Collected information on “create”, “read”, and “write” system calls • Created several access summary files (discussed later)
Related Work • Ousterhout et al. (1985) • Analyzed UNIX 4.2 BSD File System to determine file access patterns and effects of memory caching • Baker et al. (1991) • Analyzed user-level access patterns in Sprite • Sandhu, Zhou (1992) • Noted that there is a high level of sharing of unstable files in a corporate environment • However, there tends to be one cluster that writes to a file and many that read it • Introduced FROLIC system for cluster-based file replication
What About Access Patterns? • A case analysis of file access: • CASE I: “No Creators” – file was created outside of the trace set • CASE II: “1 Creator” – file was created by one computer and never deleted and recreated by another CREATE AND WRITE CASES • created, but never updated • updated by only one computer Was that computer the creator? • updated by multiple computers Was one of those computers the creator? CREATE AND READ CASES • created, but never read • read by only one computer Was that computer the creator? • read by multiple computers Was one of those computers the creator?
Case Analysis (cont’d) • CASE III: “Many Creators” – file was recreated by multiple computers • CASE IV: “No Writers” – file was never updated • CASE V: “1 Writer” – file was updated by only 1 computer • File was written to but never read • File was read by only one computer Was the reader also the writer? • File was read by many computers Was the writer one of the readers? • CASE VI: “Many Writers” – file was updated by many computers
Experimental Setup • DFSTrace • Library and related programs for analyzing Coda traces • Custom Perl Library • Wrote a small (4 classes) library in Perl for analyzing ASCII Coda Traces generated by DFSTrace • Process • Generated summary files of only creates, reads, and writes for each computer from the original trace files • Used the summary files to tally the access patterns for each file
DFSTrace • Library for writing, reading, and manipulating Coda traces • I used it to convert traces to ASCII for further manipulation with Perl scripts
PERL Library • 4 Classes • Tracefile class • Reads the trace file and outputs the create, read, and write system calls and affected files • Information stored in <computername>.sum.txt file, as each trace file contains information gathered from a specified computer • TracefileSet class • Uses the tracefile class and collects information for all the tracefiles on CD or on the web (as specified by a switch) • File class • This class is used to maintain and manipulate information about a specified file accessed within the traces • ComputerSet class • Uses the file class to maintain information for all files accessed within the traces • Writes the access summary information into the “accesstally.txt” file
PERL Library (cont’d) • 2 scripts that use the above classes • gettracedata.pl uses TracefileSet class to read and summarize all the trace files on a CD or the web • gettracesum.pl uses ComputerSet class to read and summarize information for all the traced files
Results Total: 30126
Analysis • 136 files are updated by only one computer vs. only 3 files that are updated by more than one computer • Thus, even the conservative assumption of “very small” = 1 encompasses 136 of 139 files that were updated • There are very few unstable files • Vast majority of the files are accessed only to be read, as found in earlier studies • It’s very likely that a file will be read by the same computer that created it • In most of the instances when a file has one writer or one creator, it is read by only one computer • The reader group for unstable files tends to be small • It’s likely that a file will be read by a different computer from the one that updated it • Thus, there seems to be a separation between computers that update files and computers that only read them
Analysis • Do the results make sense? • It makes sense that a computer that created a file will subsequently read it • It seems counterintuitive that a computer that updated the file will not be the one reading it in the future • such a scenario is possible in a project oriented environment • indeed, this is similar to the observation made by Sandhu and Zhou that there is typically one cluster that updates a file, while other clusters read it
Implications • Since the “writers” group is “very small” for most files, this group can be contacted directly by other clients, avoiding server write-back • It makes a lot of sense for a computer that creates a file to cache a copy of it • Since unstable files tend to have small “readers” groups, a DFS may maintain a list of “readers” as well as “writers” to optimize file sharing performance
Flaws and Limitations • Traces were collected only at CMU and only for Coda • Only 5 of 38 CD’s of data were analyzed, leaving a lot of questions unanswered • Very little data is analyzed in detail: there is no further analysis on the “No Creators” and “No Writers” cases, into which most of the data falls
Future Work • This follows directly from the “Flaws and Limitations” section • Analyze the rest of the Coda trace data • Analyze other available trace data (Sprite, etc) • Analyze in more detail the “No Creators” and “No Writers” cases