Process recovery
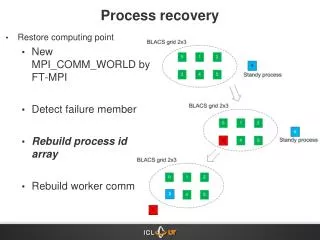
Process recovery. Restore computing point New MPI_COMM_WORLD by FT-MPI Detect failure member Rebuild process id array Rebuild worker comm. Communicator Issue. Working communicator Used by ScaLAPACK and BLACS Standby communicator Used by standup processes MPI_COMM_WORLD Checkpointing.

Process recovery
E N D
Presentation Transcript
Process recovery • Restore computing point • New MPI_COMM_WORLD by FT-MPI • Detect failure member • Rebuild process id array • Rebuild worker comm
Communicator Issue • Working communicator • Used by ScaLAPACK and BLACS • Standby communicator • Used by standup processes • MPI_COMM_WORLD • Checkpointing
Where is the lost data? • Diskless Checkpointing and Checksum Standby process, local view • Participation • Checksum: MPI_Reduce(…,MPI_SUM…) 14x14 matrix, nb=2, 2x3 grid, global view
Restart computation i • Reverse computation i B C A
Restart computation f i i i i f i
Optimization Attempt • Too many MPI_Reduce on small data blocks • 4 MPI_Reduce • 0 memcpy • MPI user defined datatype • MPI user defined opt in commutative mode • 12 MPI_Reduce • 49+ memcpy
Issues with FT-MPI • 14x14, nb=2, pxq=1x4, ok • 140x140, nb=20, pxq=1x4 => “snipe_lite.c:490 Problem, connection on socket [19] has failed. This connect has been closed.” Problem disappeared if all 1x4 processes are on one node • 1400x1400 => “conn 5 chan 4 pending send before flctrl 9999 = 1”
Some ideas from the workshop • Asynchronous checkpointing (if i don't have a failure, why do i need to stop and do checkpointing?) • Variable checkpointing interval, because failure tends to occur till the end...reduce checkpointing overhead (t = sqrt (2* (time to save satte)*AMTTI)) • Silent data corruption: • how do we know we are getting the right answer on large system and large problem? • different failure model • failure guard system • how to do it for the hybrid system failure (FT for stan‘s MAGMA code)
Init Checkpointing Before the loop starts
Rolling i>=0
Rolling ? i==k
Algorithm • At every step i: • Do the rank-k update • At every K steps: • Check for silent error by comparing the checksum on checkpointing processes and the one freshly computed by reduction • On the checkpointing processors, shadow checkpoints • At silent error • Identify the ill process • Checkpoint processors roll back to shadowed checkpoints • Kill the ill process, spawn a new one, and put it in the grid • Surviving process reverse computing to the last healthy step • Recover the data on the new process through checksum
Question • Are we using too many processes for checkpointing? • What if checkpointing process starts to fail when a working process has gone wrong silently?
STRSM for GPU • Why? • Needed in hybrid routine like sgetrf • The one from cublas is too slow • So current we have to transfer data back from GPU to CPU to do strsm, wasting time
Design -1 2 3 1 A x b 6 4 5
Improvement • Strsm_kernel is always on the critical path • 3 strsm_kernel = 3 strtri_kernel + 3 strmv_kernel • All 3 strtri_kernel can be done in one shot on GPU • So now 3 strsm_kernel > 1 strtri_kernel + 3 strmv_kernel • Critical path is reduced
Design -2 2 3 1 4 5 ……
A few thoughts • Julien & George’s code is • trying to build pblas/scalapack from scratch to enable FT • Using m+n extra processes to babysit m*n process • What if we could: • Being able to reuse pblas/scalapack • As less checkpointing processors as possible
Multiplication A x B = C
Checkpointing • Get to reuse Pblas/scalapack • Require 1 extra process for 6 processes, instead of 5 for 6
Locate sick process • What could go wrong? • Network card -> sending out wrong data via mpi • Memory -> doing computation on wrong data • ALU -> giving wrong result • Disk -> providing wrong data • etc… • Old checksum is good for detect errors, but is not process specific • We could: • Recompute the local checksum • Keep a local-only checksum, like the sum of all local matrices • Or …
A little update with clapack • Keith’s f2c applied to lapack3.2 • Problems solved: • Substring issue with maxloc • Malloc on the fly problem • Status • Passing the LAPACK test suite • Extended to lapack3.2.1