Probability Sampling
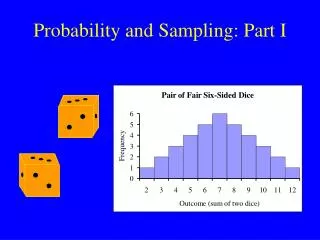
Probability Sampling. uses random selection N = number of cases in sampling frame n = number of cases in the sample N C n = number of combinations of n from N f = n/N = sampling fraction. Variations. Simple random sampling based on random number generation Stratified random sampling


Probability Sampling
E N D
Presentation Transcript
Probability Sampling • uses random selection • N = number of cases in sampling frame • n = number of cases in the sample • NCn = number of combinations of n from N • f = n/N = sampling fraction
Variations • Simple random sampling • based on random number generation • Stratified random sampling • divide pop into homogenous subgroups, then simple random sample w/in • Systematic random sampling • select every kth individual (k = N/n) • Cluster (area) random sampling • randomly select clusters, sample all units w/in cluster • Multistage sampling • combination of methods
Nonprobability sampling • accidental, haphazard, convenience sampling ... • may or may not represent the population well
Measurement • ... topics in measurement that we don’t have time to cover ...
Research Design • Elements: • Samples/Groups • Measures • Treatments/Programs • Methods of Assignment • Time
Internal validity • the approximate truth about inferences regarding cause-effect (causal) relationships • can observed changes be attributed to the program or intervention and NOT to other possible causes (alternative explanations)?
Establishing a Cause-Effect Relationship • Temporal precedence • Covariation of cause and effect • if x then y; if not x then not y • if more x then more y; if less x then less y • No plausible alternative explanations
Single Group Example • Single group designs: • Administer treatment -> measure outcome X -> O • assumes baseline of “0” • Measure baseline -> treat -> measure outcome 0 X -> O • measures change over baseline
Single Group Threats • History threat • a historical event occurs to cause the outcome • Maturation threat • maturation of individual causes the outcome • Testing threat • act of taking the pretest affects the outcome • Instrumentation threat • difference in test from pretest to posttest affects the outcome • Mortality threat • do “drop-outs” occur differentially or randomly across the sample? • Regression threat • statistical phenomenon, nonrandom sample from population and two imperfectly correlated measures
Addressing these threats • control group + treatment group • both control and treatment groups would experience same history and maturation threats, have same testing and instrumentation issues, similar rates of mortality and regression to the mean
Multiple-group design • at least two groups • typically: • before-after measurement • treatment group + control group • treatment A group + treatment B group
Multiple-Group Threats • internal validity issue: • degree to which groups are comparable before the study • “selection bias” or “selection threat”
Multiple-Group Threats • Selection-History Threat • an event occurs between pretest and posttest that groups experience differently • Selection-Maturation Threat • results from differential rates of normal growth between pretest and posttest for the groups • Selection-Testing Threat • effect of taking pretest differentially affects posttest outcome of groups • Selection-Instrumentation Threat • test changes differently for the two groups • Selection-Mortality Threat • differential nonrandom dropout between pretest and posttest • Selection-Regression Threat • different rates of regression to the mean in the two groups (if one is more extreme on the pretest than the other)
Social Interaction Threats • Problem: • social pressures in research context can lead to posttest differences that are not directly caused by the treatment • Solution: • isolate the groups • Problem: in many research contexts, hard to randomly assign and then isolate
Types of Social Interaction Threats • Diffusion or Imitation of Treatment • control group learns about/imitates experience of treatment group, decreasing difference in measured effect • Compensatory Rivalry • control group tries to compete w/treatment group, works harder, decreasing difference in measured effect • Resentful Demoralization • control group discouraged or angry, exaggerates measured effect • Compensatory Equalization of Treatment • control group compensated in other ways, decreasing measured effect
Intro to Design/ Design Notation • Observations or Measures • Treatments or Programs • Groups • Assignment to Group • Time
Observations/Measure • Notation: ‘O’ • Examples: • Body weight • Time to complete • Number of correct response • Multiple measures: O1, O2, …
Treatments or Programs • Notation: ‘X’ • Use of medication • Use of visualization • Use of audio feedback • Etc. • Sometimes see X+, X-
Groups • Each group is assigned a line in the design notation
Assignment to Group • R = random • N = non-equivalent groups • C = assignment by cutoff
Time • Moves from left to right in diagram
Types of experiments • True experiment – random assignment to groups • Quasi experiment – no random assignment, but has a control group or multiple measures • Non-experiment – no random assignment, no control, no multiple measures
Design Notation Example Pretest-posttest treatment versus comparison group randomized experimental design
Design Notation Example Pretest-posttest Non-Equivalent Groups Quasi-experiment
Design Notation Example Posttest Only Non-experiment
Goals of design .. • Goal:to be able to show causality • First step: internal validity: • If x, then y AND • If not X, then not Y
Two-group Designs • Two-group, posttest only, randomized experiment Compare by testing for differences between means of groups, using t-test or one-way Analysis of Variance(ANOVA) Note: 2 groups, post-only measure, two distributions each with mean and variance, statistical (non-chance) difference between groups
To analyze … • What do we mean by a difference?
Three ways to estimate effect • Independent t-test • One-way Analysis of Variance (ANOVA) • Regression Analysis (most general) • equivalent
The t-test • appropriate for posttest-only two-group randomized experimental design • See also: paired student t-test for other situations.
Computing standard deviation • standard deviation is the square root of the sum of the squared deviations from the mean divided by the number of scores minus one • variance is the square of the standard deviation
ANOVA • One-way analysis of variance
ANOVA • Analysis of variance – tests hypotheses about differences between two or more means • Could do pairwise comparison using t-tests, but can lead to true hypothesis being rejected (Type I error) (higher probability than with ANOVA)
Between-subjects design • Example: • Effect of intensity of background noise on reading comprehension • Group 1: 30 minutes reading, no background noise • Group 2: 30 minutes reading, moderate level of noise • Group 3: 30 minutes reading, loud background noise
Experimental Design • One factor (noise), three levels(a=3) • Null hypothesis: 1 =2 =3
Notation • If all sample sizes same, use n, and total N = a * n • Else N = n1 + n2 +n3
Assumptions • Normal distributions • Homogeneity of variance • Variance is equal in each of the populations • Random, independent sampling • Still works well when assumptions not quite true(“robust” to violations)
ANOVA • Compares two estimates of variance • MSE – Mean Square Error, variances within samples • MSB – Mean Square Between, variance of the sample means • If null hypothesis • is true, then MSE approx = MSB, since both are estimates of same quantity • Is false, the MSB sufficiently > MSE
MSB • Use sample means to calculate sampling distribution of the mean, = 1
MSB • Sampling distribution of the mean * n • In example, MSB = (n)(sampling dist) = (4) (1) = 4
Is it significant? • Depends on ratio of MSB to MSE • F = MSB/MSE • Probability value computed based on F value, F value has sampling distribution based on degrees of freedom numerator (a-1) and degrees of freedom denominator (N-a) • Lookup up F-value in table, find p value • For one degree of freedom, F == t^2
Factorial Between-Subjects ANOVA, Two factors • Three significance tests • Main factor 1 • Main factor 2 • interaction
Example Experiment • Two factors (dosage, task) • 3 levels of dosage (0, 100, 200 mg) • 2 levels of task (simple, complex) • 2x3 factorial design, 8 subjects/group
Summary table SOURCE df Sum of Squares Mean Square F p Task 1 47125.3333 47125.3333 384.174 0.000 Dosage 2 42.6667 21.3333 0.174 0.841 TD 2 1418.6667 709.3333 5.783 0.006 ERROR 42 5152.0000 122.6667 TOTAL 47 53738.6667 • Sources of variation: • Task • Dosage • Interaction • Error
Results • Sum of squares (as before) • Mean Squares = (sum of squares) / degrees of freedom • F ratios = mean square effect / mean square error • P value : Given F value and degrees of freedom, look up p value
Results - example • Mean time to complete task was higher for complex task than for simple • Effect of dosage not significant • Interaction exists between dosage and task: increase in dosage decreases performance on complex while increasing performance on simple