Download

1 / 25
250 likes | 314 Vues
Explore a new approach, Segmentation Conditional Random Fields (SCRFs), for predicting structural motifs and protein folds, addressing challenges like long-range interactions and hard-to-generalize cases. Learn about the framework and inference algorithms for accurate predictions.

E N D
Segmentation Conditional Random Fields (SCRFs)A New Approach for Protein Fold Recognition Yan Liu1, Jaime Carbonell1, Peter Weigele2,Vanathi Gopalakrishnan3 1. School of Computer Science, Carnegie Mellon University 2. Biology Department, Massachusetts Institute of Technology 3. Center for Biomedical Informatics, University of Pittsburgh Biological Language Modeling Project
Structural motif recognition • Structural motif • Regular arrangement of secondary structural elements, which commonly appears in a variety of protein families • Super-secondary structure, or protein fold • Example • Structural motif recognition • Given a structural motif and a protein sequence, predict the presence of the motif and the exact location in the protein, based on sequences only β-α-β(2CMD) Leucine-rich repeats (1A4Y) Biological Language Modeling Project
Previous work on structural motif recognition • General approaches for structural motif recognition • Sequence similarity searches, e.g. PSI-BLAST [Altschul et al, 1997] • Profile HMM, .e.g. HMMER [Durbin et al, 1998] and SAM [Karplus et al, 1998] • Homology modeling or threading, e.g. Threader [Jones, 1998] • Methods of careful design for specific structure motifs • Example: αα- and ββ- hairpins, β-turn and β-helix Major challenges: structural similarity without clear sequence similarity Long-range interactions, such as β-sheets Hard to generalize Our goal is to have a general probabilistic framework to address all these problems for structural motif prediction Biological Language Modeling Project
Outline • Introduction • Conditional random fields • Segmentation conditional random fields • Case study on β-helix fold recognition • Conclusion Biological Language Modeling Project
Graphical models for protein structure prediction • Graphical models for protein structure prediction • Probabilistic causal networks [Delcher et al, 1993] • Markov random fields [White et al, 1994] • Hidden Markov model [Bystroff et al, 2000] • Bayesian segmentation model [Schmidler and Liu, 2000] • Protein structure prediction can be generalized as learning problems for structured data • Structured data: observation with internal or external structures • Conditional graphical models are successful in various applications Biological Language Modeling Project
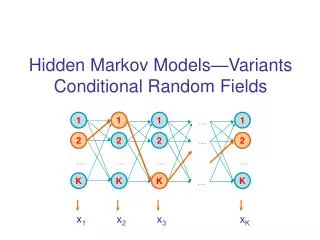
Condition random fields • Condition random fields (CRFs) [lafferty et al, 2001] • A conditionalundirected graphical model • The conditional probability is defined as • Flexible feature definition • Convex optimization function guarantees the globally optimal solution • Efficient inference algorithms • Kernel CRFs permits the use of implicit feature spaces via kernels [Lafferty et al, 2004] HMMs CRFs Biological Language Modeling Project
Graphical models for Structural Motif detection • Structural motif detection • Structural components • Secondary structural elements instead of individual residues • Informative features • Indicator for conserved regions • Length of each component • Propensities to form hydrogen bond in β-sheet Segmented Markov Models Biological Language Modeling Project
Segmentation conditional random fields (I) • Protein structural graph G = <V, E> • V: nodes for the secondary structural elements of variable lengths • E1 edges between adjacent nodes for peptide bonds • E2 edges between distant nodes for hydrogen bonds or disulfide bonds • Example: β-α-β motif • Tradeoff between fidelity of the model and graph complexity Biological Language Modeling Project
Segmentation conditional random fields (II) • Segmentation conditional random fields (SCRFs) • Given a protein structure graph G, we define a segmentation of the sequence W = (M, S), where Si = <pi, qi, yi> • The conditional probability of the segmentation W given the observation x is defined as • If each subgraph of the resulting graph is a tree or a chain, we can simplify the model to be Biological Language Modeling Project
Training and Testing for SCRFs • Training phase : learn the model parameters • Minimizing regularized log loss • Seek the direction whose empirical values agrees with the expectation • Iterative searching algorithm have to be applied • Testing phase: search the segmentation that maximize P(w|x) Biological Language Modeling Project
Inference algorithm • Backward-forward algorithm* • Viterbi algorithm* Biological Language Modeling Project
SCRFs for β-helix fold recognition (I) • Right-handedβ-helix fold • A regular structural fold with an elongated helix-like structures whose successive rungs composed of three parallel β-strands (B1, B2, B3 strands) • T2 turn: a unique two-residue turn • Perform important functions such as the bacterial infection of plants, binding the O-antigen and etc. • Computational challenges • Long insertions in T1 and T3 turn • Structural similarity with low sequence similarity • Previous work • BetaWrap [Bradley et al 2001, Bradley et al. 2001, Cowen et al 2002] • BetaWrapPro [McDonnell et al] Pectate Lyase C (Yoder et al. 1993) Biological Language Modeling Project
SCRFs for β-helix fold recognition (II) • Protein structure graph • 5 states: B1, B23, T1, T3, I • Length constraints • B1, B23: fixed length as 3 and 9 • T1, T3: 1 – 80 • Long-range interactions between B23 • Prediction scores • Log-ratio scores Biological Language Modeling Project
Features • Node features • Regular expression template, HMM profiles • Secondary structure prediction scores • Segment length • Inter-node features • β-strand Side-chain alignment scores • Preferences for parallel alignment scores [Steward & Thonton, 2002] • Distance between adjacent B23 segments • Features are general and easy to extend Biological Language Modeling Project
Experiments (I) • Cross-family validation for known β-helix proteins • PDB select dataset: non-homologous proteins in PDB removing β-helix proteins • SCRFs can score all known β-helices higher than non β-helices Biological Language Modeling Project
Experiments (II) • Predicted Segmentation for known Beta-helices Biological Language Modeling Project
Experiments (III) • Histograms for known β-helices against PDB-minus dataset • 18 non β-helix proteins have a score higher than 0 • 13 from β-class and 5 from α/β class • Most confusing proteins: β-sandwiches and left-handed β-helix 5 Biological Language Modeling Project
Discovery of potential β-helices • Verification on recently crystallized structures • Successfully identify gp14 of Shigella bacteriophage as a β-helix protein with scoring 15.63 • Hypothesize on Uniprot reference databases with less than 50% identity (UniRef50) • 93 sequences were returned with scores above a cutoff of 5 • 48 proteins are homologous with proteins known be β-helices • Full list can be accessed at www.cs.cmu.edu/~yanliu/SCRF.html Biological Language Modeling Project
Conclusion • Segmentation conditional random fields (SCRFs) for protein structural motif detection • Consider the structural characteristics in a general probabilistic framework • Conditional graphical models that considers the long-range interactions directly and conveniently • A case study for β-helix fold recognition • Future work • Computational complexity: O(N2) • Chain graph model: localized SCRFs model • Generality of the model • Leucine-rich repeats, Ankyrin proteins and some virus-spike folds Biological Language Modeling Project
Further Exploration-(I) • Chain graph model • A combination of directed and undirected graph • Local normalization version of segmentation CRFs • Reduce the computational complexity to O(N) • Experiment on β-helix fold and Leucine-rich repeats • Achieve approximate results as SCRFs with only slight difference 1A4Y 1OGQ Biological Language Modeling Project
Further Exploration (II) • Cross-family validation for known LLR by chain graph model • 41 LLR proteins with known structures • 2 super-family and 11 families Biological Language Modeling Project
SCRFs for general graph • For any graph G = <V, E>, the conditional probability of the segmentation W given the observation x is defined as • If there are no E2 edges (long-range interactions) • semi-markov conditional random fields (Sarawagi & Cohen, 2004) Biological Language Modeling Project
SCRFs for general graph • For any graph G = <V, E>, the conditional probability of the segmentation W given the observation x is defined as • If there are no E2 edges (long-range interactions) • semi-markov conditional random fields (Sarawagi & Cohen, 2004) • Efficient algorithms for inference • If the state transition is deterministic and the resulting graph consists of trees or chains Biological Language Modeling Project
SCRFs for general graph • For any graph G = <V, E>, the conditional probability of the segmentation W given the observation x is defined as • If there are no E2 edges (long-range interactions) • semi-markov conditional random fields (Sarawagi & Cohen, 2004) • Efficient algorithms for inference • If the state transition is deterministic and the resulting graph consists of trees or chains • If the state transition is not deterministic or a complex graph • Approximation methods have to be applied, such as variational methods or sampling Biological Language Modeling Project
Acknowledgement Jonathan King @ MIT Bonnie Berger @ MIT Robert E. Steward and Janet Thornton @ EMBL-EBI John Lafferty @ CMU Biological Language Modeling Project