Minimum Expected Loss in Decision Theory
Explore decision theory concepts such as loss matrices, expected value, and conditional expectation in regression analysis. Learn to minimize loss and make optimal predictions using the squared loss function.


Minimum Expected Loss in Decision Theory
E N D
Presentation Transcript
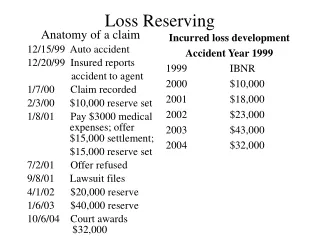
Minimum Expected Loss/Risk • If we want to consider more than zero-one loss, then we need to define a loss matrix with elements Lkjspecifying the penalty associated with assigning a pattern belonging to class Ck as class Cj (i.e. Read kj as k-> j or ‘’k classified as j’’) • Example: classify medical images as ‘cancer’ or ‘normal’ • Then, to compute the minimum expected loss, we need to look at the concept of expected value. Decision Truth
Expected Value • The expected value of a function f(x), where x has the probability density/mass p(x) is Discrete Continuous • For a finite set of data pointsx1 , . . . ,xn, drawn from the distribution p(x),the expectation can be approximated by the average over the data points:
Reminder: Minimum Misclassification Rate Illustration with more general distributions, showing different error areas.
Minimum Expected Loss/Risk For two classes: Expected loss= ∫R2 L12p(x,C1)dx + ∫R1 L21p(x,C2)dx In general: Regions are chosen to minimize:
Regression • For regression, the problem is a bit more complicated and we also need the concept of conditional expectation. E[t|x] = S p(t|x) t(x) t
MultiVariable and Conditional Expectations Rememberthedefinition of theexpectation of f(x) wherex has theprobability p(x) : Conditional Expectation (discrete) E[t|x] = S p(t|x) t(x) t
Decision Theory for Regression Inference step Determine . Decision step For given x, make optimal prediction, y(x). Loss function:
The Squared Loss Function If we used the squared loss as loss function: Advanced After some calculations (next slides...), we can show that:
ADVANCED - Explanation: • Consider the first term inside the loss: • This is equal to: since p(x,t)=p(t|x)p(x) since p(x) doesn’t depend on t, we can move out of the integral; then the integral ∫p(t|x)dt amounts to 1 as we are summing prob.s through all possible t
Advanced: Explanation • Consider the second term inside the loss: • This is equal to zero: since doesn’t depend on t, we can move out of the integral
ADVANCED: Explanation for last step • E[t|x] does not vary with different values of t, so it can be moved out. • Notice that you could also immediately see that the expected value of differences from the mean for the random variable t is 0 (first line of the formula).
Important • Hence we have: • The first term is minimized when we select y(x) as • The second term is independent of y(x) and represents the intrinsic variability of the target • It is called the intrinsic error.
Alternative approach/explanation • Using the squared error as the loss function: • We want to choose y(x) to minimize the expected loss: