Common Errors in Data Labeling and How to Avoid Them
As businesses increasingly rely on artificial intelligence, the demand for top-notch data labeling <br>services has soared. Yet, even slight errors in this process can lead to significant setbacks. In this <br>post, weu2019ll explore common pitfalls in data labeling and share effective strategies to mitigate them.


Common Errors in Data Labeling and How to Avoid Them
E N D
Presentation Transcript
Common Errors in Data Labeling and How to Avoid Them Introduction to Data Labeling In today’s data-driven world, the success of your machine learning models hinges on one critical process: data labeling. This essential step transforms raw information into structured datasets that machines can understand. But what happens when this crucial task goes awry? The accuracy and consistency of labeled data are paramount for achieving reliable outcomes in analysis and decision- making. As businesses increasingly rely on artificial intelligence, the demand for top-notch data labeling services has soared. Yet, even slight errors in this process can lead to significant setbacks. In this post, we’ll explore common pitfalls in data labeling and share effective strategies to mitigate them. Whether you’re new to the field or looking to refine your existing processes, understanding these challenges is key to leveraging your data effectively. Let’s dive into the intricacies of accurate data labeling!
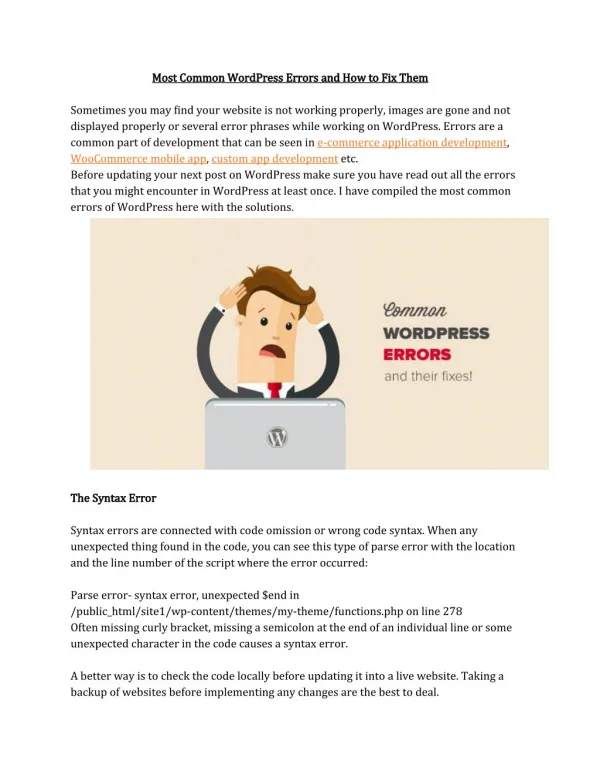
The Importance of Accurate Data Labeling Accurate data labeling is a cornerstone of effective machine learning and artificial intelligence. When your labels are precise, the algorithms learn better and produce more reliable outcomes. This accuracy directly affects the performance of AI models in real-world applications. In industries ranging from healthcare to finance, mislabeling can lead to grave consequences. Incorrect data can skew analyses, resulting in misguided strategies or even harm to individuals. Moreover, accurate labeling fosters trust between stakeholders and technology providers. Companies need confidence that their systems will deliver valid insights based on dependable input. Investing time and resources into quality data labeling enhances project success rates significantly. It ensures that every piece of information contributes positively towards achieving desired results. Common Errors in Data Labeling: •Data labeling service is crucial for machine learning and AI, but errors can creep in easily. One of the most common mistakes is incorrect labels. This happens when data points are labeled inaccurately, leading to flawed models that misinterpret information. •Inconsistent labeling also poses a significant challenge. When different team members apply varying standards or definitions, it creates confusion and reduces data quality. •Human error is another factor that can't be overlooked. Labelers may unintentionally introduce bias based on their perspectives or experiences, affecting the dataset's integrity. •These issues might seem minor at first glance but can significantly derail your projects over time. Identifying these common pitfalls early will set you up for success in any data labeling initiative. Incorrect Labels Incorrect labels are one of the most common pitfalls in data labeling. When a dataset is labeled inaccurately, it can lead to serious consequences down the line. Machine learning models trained on flawed data may produce unreliable results. Imagine training an image recognition system with misidentified categories. A cat labeled as a dog could throw off predictions and undermine user trust. These errors often stem from rushed processes or unclear guidelines. Without proper instructions, labelers may interpret tasks differently, leading to inconsistencies in categorization. Moreover, incorrect labels can skew analytics efforts. Decisions based on faulty insights might not align with actual trends or behaviors within your target population.
Addressing incorrect labeling requires diligence and attention to detail. Implementing structured workflows helps maintain accuracy across datasets while enhancing overall reliability in analyses and applications. Inconsistent Labeling Inconsistent labeling can create chaos in data sets. When labels fluctuate between categories, the results become unreliable. This inconsistency leads to confusion during analysis. For instance, if one dataset labels images of cats as “felines” while another uses “cats,” it complicates training machine learning models. Such discrepancies hinder model performance and accuracy. Moreover, inconsistent labeling often arises from different team members interpreting guidelines differently. A lack of clear definitions contributes significantly to this issue. Establishing a standardized set of rules for labeling is crucial. Regular training sessions can also align everyone’s understanding and approach, minimizing variations over time. Consistency is key in ensuring that your data remains reliable and useful for analysis and decision- making processes. Human Error and Bias Human error and bias are significant challenges in data labeling. Despite our best intentions, mistakes can happen. A labeler might misinterpret an image or overlook a crucial detail. Such errors can lead to inaccurate datasets. Bias is another concern. Labelers bring their perspectives, which may not align with the objective requirements of the task. This subjectivity can skew results and affect machine learning models' performance. For instance, if certain demographics are underrepresented during labeling, algorithms trained on this biased data will reflect those gaps. The consequence? Inequitable outputs that further entrench existing disparities. Addressing these issues requires vigilance and awareness throughout the labeling process. Training sessions focused on understanding biases can help mitigate human shortcomings in this critical stage of data preparation. How These Errors Can Impact Your Data Analysis Errors in data labeling can lead to significant misinterpretations. Incorrect labels skew the analysis, resulting in misguided conclusions and poor decision-making.
Inconsistent labeling creates confusion within datasets. This inconsistency complicates machine learning processes, making it harder for algorithms to learn effectively. Human error introduces bias that clouds the insights drawn from data. Such biases can amplify existing stereotypes or overlook important trends, further distorting results. These impacts ripple through your entire project, affecting everything from strategy development to resource allocation. Poor quality data undermines trust among stakeholders and may derail future initiatives altogether. Addressing these errors is crucial for ensuring reliable outcomes in any analytical endeavor. Investing time and resources into accurate data labeling services pays off significantly when it comes to deriving actionable insights from your findings. Strategies to Avoid Data Labeling Errors: Implementing quality control measures is essential for minimizing errors in data labeling. Regular audits can help identify discrepancies early on. By reviewing samples of labeled data, you can ensure that standards are being met consistently. Incorporating automation and technology solutions enhances accuracy significantly. Machine learning tools can assist in reducing human workload and provide preliminary labels, allowing humans to focus on fine-tuning the results. Training your team regularly cannot be overlooked. Continuous education keeps labelers updated on best practices and evolving methodologies, ensuring a higher level of proficiency. Fostering an environment where open communication thrives encourages feedback among team members. This collaboration leads to shared knowledge and a collective commitment to excellence in data labeling processes. Quality Control Measures •Quality control measures are vital in ensuring data labeling company accuracy. A well- defined process helps catch errors before they impact the final dataset. •Implementing a review system can be beneficial. This involves having multiple reviewers cross-check labels for consistency and correctness. Peer reviews foster collaboration and reduce individual biases, enhancing overall quality. •Utilizing checklists is another effective strategy. These guides remind labelers of key requirements and standards to follow during the labeling process. •Regular audits of labeled data also play a crucial role. Analyzing samples periodically can uncover patterns of mistakes that need addressing, leading to continuous improvement. •Training sessions further strengthen your team’s skills in identifying common pitfalls in labeling practices, fostering attention to detail across all members involved in the project.
Automation and Technology Solutions Automation is transforming the landscape of data labeling services. By integrating advanced technologies, organizations can reduce human error and enhance efficiency. Machine learning algorithms are a key player in this shift. They can learn from large volumes of data, identifying patterns that may be too complex for manual processing. This capability allows for quicker label assignments without sacrificing accuracy. Another important tool is natural language processing (NLP). NLP technology aids in understanding context within text data, ensuring labels are relevant and precise. This reduces the chances of mislabeling content based on ambiguous interpretations. Moreover, automated workflows streamline collaboration between teams. When everyone accesses the same platform with real-time updates, consistency improves significantly across datasets. Investing in these automation solutions not only boosts productivity but also allows teams to focus more on strategic tasks rather than repetitive ones. Embracing technology in data labeling opens new avenues for innovation and quality assurance. The Role of Communication and Collaboration in Data Labeling Effective communication is vital in the world of data labeling. Clear instructions ensure that everyone on the team understands what is required. This clarity reduces confusion and minimizes errors. Collaboration between data scientists, labelers, and stakeholders can enhance quality. Regular check-ins allow teams to share insights and address issues promptly. When different perspectives come together, they lead to more accurate labeling. Utilizing collaborative tools helps streamline workflows. These platforms facilitate real-time feedback and updates, promoting a unified approach to projects. Encouraging an open dialogue fosters a culture of continuous improvement. Team members feel empowered to voice concerns or suggest enhancements, ultimately leading to better outcomes in data labeling services. When teams work together harmoniously, they not only improve efficiency but also elevate the overall quality of their labeled data. This synergy creates a strong foundation for successful data analysis in various applications.
Conclusion Data labeling is a crucial process in today’s data-driven world. As organizations increasingly rely on machine learning and artificial intelligence, the need for accurate data labeling services becomes paramount. Errors in this area can lead to significant setbacks. Understanding the common pitfalls—such as incorrect labels and human bias—is essential for anyone involved in data handling. These mistakes could distort analysis, leading teams astray from their objectives. Implementing quality control measures and leveraging automation tools can significantly reduce errors. Moreover, fostering open communication among team members enhances collaboration and aligns everyone towards a shared goal of accuracy. Investing time and resources into perfecting your data labeling processes pays off greatly. It not only boosts efficiency but also strengthens outcomes across various projects, ensuring that your organization remains competitive in an ever-evolving landscape. Reach out to us understand how we can assist with this process - sales@objectways.com