O ptimzing mysql
O ptimzing mysql. I feel the need....the need for speed. 壮志凌云( top gun ). 性能监控 10 分 性能优化 20 分 常见的架构 10 分 Tools and tips 10 分. 性能监控. 操作系统级别的 Mysql 级别. 操作系统. vmstat iostat free top sar mpstat uptime, netstat strace. mysql. Show processlist


O ptimzing mysql
E N D
Presentation Transcript
I feel the need....the need for speed. 壮志凌云(top gun)
性能监控 10分 性能优化 20分 常见的架构 10分 Tools and tips 10分
性能监控 操作系统级别的 Mysql级别
操作系统 vmstat iostat free top sar mpstat uptime, netstat strace
mysql Show processlist Mysqlreport http://hackmysql.com/mysqlreportguide Mysqladmin -uxxx –p -i 1 -r extendedstatus|grep -v “| 0” Innotop http://www.xaprb.com/blog/2006/07/02/innotop-mysql-innodb-monitor/ Show global status,show inondb status show session status; Mytop Explain Profiling Mysqldumpslow mysqlsla sysbench
vmstat 基本的物理和虚拟内存的使用和一些基本的系统统计信息 Vmstat –S M Vmstat 5 5 Swap颠簸现象 Top ps axl
iostat 度量磁盘i/o,cpu和设备io使用 Iostat -c iostat –dx 5 %iowait 并发请求的数量 并发=(r/s+w/s)*(svctm/1000)(从头到尾服务请求时间)
谁可能导致高的cpu usage query ,joins,every 进程切换, 锁表 内存排序 临时表 加密算法 谁可能导致高的disk usage 临时表 硬盘上排序 start with an idea ,then look for infromation support it
netstat 服务链接状态 netstat -nat |awk '{print $6}' | sort | uniq -c | sort -n 是否被dos:netstat -atun | awk '{print $5}' | cut -d: -f1 | sed -e '/^$/d' |sort | uniq -c | sort -n /bin/netstat -na|grep ESTABLISHED|awk '{print $5}'|awk -F: '{print $1}'|sort|uniq -c|sort -rn|grep -v -E '172.16|127.0'|awk '{if ($2!=null && $1>10) {print $1,$2}}'
其它 Top: Ps: ps aux|awk '{ if ($6 >(1024*15)){print $2}}'|grep -v PID ………………
分析服务器 Mysqlreport Mysqladmin mysqladmin extended -r -i 10| grep –v “| 0 ” -uroot –p Innotop …. Show global status Show innodb status
分析查询 Show processlist Flush status Show session status like ‘Select%’ Show session status like ‘Handler%’ Show session status like ‘Sort%’ Show session status like ‘Create%’ Set profiling
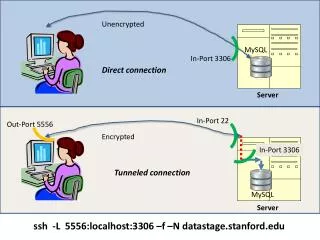
分析mysql连接 netstat -ntp| grep :40327 netstat -ntp| grep 10940/mysqld grep 3306 /etc/services ps -eaf| grep 'UID\|10940' lsof -i -P| grep 10942
性能优化 操作系统 mysql 应用程序
操作系统 不要交换区。如果内存不足,增加更多的内存或配置你的系统使用较少内存。 flick:echo 0 > /proc/sys/vm/swappiness innodb_flush_method=O_DIRECT 不要使用NFS磁盘(会有NFS锁定的问题)。 增加系统和MySQL服务器的打开文件数量。(在safe_mysqld脚本中加入ulimit -n #)。 增加系统的进程和线程数量。 选择使用哪种文件系统。在Linux上的Reiserfs对于打开、读写都非常快。文件检查只需几秒种。
Mysql配置 Mysiam 缓存 key_buffer_size key_buffer_1.key_buffer_size=1G show variables like 'key_buffer_size'; show global status like 'key_read%'; key_cache_miss_rate = Key_reads / Key_read_requests * 100% du –sch `find /mysqldatapath/ -name “*.MYI”` Innodb 缓冲池 innodb_bufer_pool_size 80% show status like 'Innodb_buffer_pool_read%' Innodb_buffer_pool_read_requests/Innodb_buffer_pool_reads show innodb status\G BUFFER POOL AND MEMORY Total memory allocated 4668764894;
查询缓存 show global status like 'Qcache%'; show variables ‘like query_cache%'; 查询缓存利用率 = (query_cache_size – Qcache_free_memory) / query_cache_size * 100% 查询缓存命中率 = (Qcache_hits – Qcache_inserts) / Qcache_hits * 100% http://www.day32.com/MySQL/
innodb 刷写日志缓冲 Innodb_flush_log_at_trx_commit 0 1 2 打开并清写日志和文件 innodb_flush_method
myisam 初始化: initial =key_buffer_size + query_cache_size 连接 per_connection=(sort_buffer_size +read_rnd_buffer_size + join_buffer_size + read_buffer_size + thead_stack ) 总和: initial + max_connections * per_connection initial + ((max_connections * per_connection)/3)
innodb 初始化: initial =innodb_buffer_pool_size+ query_cache_size 连接 per_connection = (sort_buffer_size + join_buffer_size + thead_stack + binlog_cache_size + read_buffer_size + read_rnd_buffer_size) 总和: initial + max_connections * per_connection initial + ((max_connections * per_connection)/3)
数据类型选择 更小通常更好,慷慨并不明智 简单就好 使用mysql内建的类型保存日期和时间,使用timestamp 保存,空间是datetime一半 使用整数保存ip 15 bytes for char(15) vs. 4 bytes for the integer ip2long() 和 long2ip() inet_aton 3 尽量避免null 4 Char /varcha的选择 对于MyISAM而言,如果没有VARCHAR,TEXT等变长类型,那么每行数据所占用的空间都是定长的(Fixed),俗称静态表,相对应的就是动态表。当执行一次查询时,MySQL可以通过索引文件找到所需内容的实际行号,此时,由于每行数据所占用的空间都是定长的(Fixed),所以可以通过查询到的实际行号直接定位到数据文件的具体位置, 对于InnoDB而言,数据行是没有所谓定长与否的概念的,这是由其结构所决定的:在InnoDB中,数据就位于Primary Key的B-Tree叶节点之上而除Primary Key之外的索引被称为Secondary Index,它们直接指向Primary Key。 用char来代替varchar,MyISAM是这样,InnoDB则相反 5 使用enum 代替字符串类型 select internet + 0 from hotel_info group by internet;
索引 • 隔离列 select * from tablename where id+1=5 Select * where TO_DAYS(CURRENT_DATE) – TO_DAYS(data_col) < =10 Select * where data_col >=date_sub(current_date,interval 10 day) Select * where data_col >= date_sum(‘2010-04-12’,interval 10 day) EXPLAIN SELECT * FROM film WHERE title LIKE 'Tr%'\G EXPLAIN SELECT * FROM film WHERE LEFT(title,2) = 'Tr' \G • 组合索引 前缀索引 • 覆盖索引 • 合并索引 • 去除多余索引和重复索引 create table test (id int not null primary key, unique(id), index(id) )
合并索引 索引合并方法用于通过range扫描搜索行并将结果合成一个。合并会产 生并集、交集或者正在进行的扫描的交集的并集。 在EXPLAIN输出中,该方法表现为type列内的index_merge。 在这种情况下,key列包含一列使用的索引,key_len包含这些索引的最长的关键元素 SELECT * FROM tbl_name WHERE key_part1 = 10 OR key_part2 = 20;
前缀索引 Key(a,b,c) Order by a ,order by a,b order by a,b,c order by a desc ,b desc,c desc Where a = const order by b,c,where a=const and b =const order by c Where a = const order by b,c where a = const and b > const order by,c Order by a asc,b desc,c desc Where g = const oder by b ,c Where a = const order by c Where a = const order by a ,d Where a>’xx’ order by b,c Where a>’xx’ order by a,b Where a=const order by b desc ,a asc
覆盖索引 Select * from products where actor=‘sean carrey’ and and title like ‘%apollo%’ Select * from products join (select prod_id from products where actor= ‘sean carrey’ and title like ‘%apollo%’) as t1 on (t1.prod_id = products.pro_id)
逆范式化 适当的冗余 分拆表
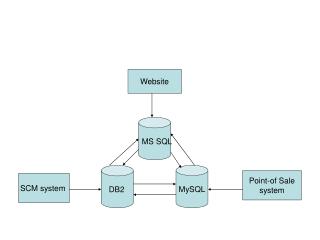
产品设计 产品设计->数据交互->mysql Antoine de Saint—Exupery是法国作家兼飞机设计师,他曾经说过:“设计者确定其设计已经达到了完美的标准不是不能再增加任何东西,而是不能再减少任何东 西。” 分页的实现
http://www.douban.com/group/BigBangTheory/discussion?start=25http://www.douban.com/group/BigBangTheory/discussion?start=25
1 explain select SQL_NO_CACHE * from page_test force index(idx_b_c) where b=1 order by c desc limit 2000,10; +----+-------------+-----------+------+---------------+---------+---------+-------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-----------+------+---------------+---------+---------+-------+------+-------------+ | 1 | SIMPLE | page_test | ref | idx_b_c | idx_b_c | 4 | const | 2222 | Using where | +----+-------------+-----------+------+---------------+---------+---------+-------+------+-------------+ 2 mysql> explain select SQL_NO_CACHE * from page_test, (select SQL_NO_CACHE id from page_test force index(idx_b_c) where b=1 order by c desc limit 2000,10) temp where page_test.id=temp.id; +----+-------------+------------+--------+---------------+---------+---------+---------+------+--------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+------------+--------+---------------+---------+---------+---------+------+--------------------------+ | 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | NULL | 10 | | | 1 | PRIMARY | page_test | eq_ref | PRIMARY | PRIMARY | 8 | temp.id | 1 | | | 2 | DERIVED | page_test | ref | idx_b_c | idx_b_c | 4 | | 2222 | Using where; Using index | +----+-------------+------------+--------+---------------+---------+---------+---------+------+--------------------------+ 3 explain select SQL_NO_CACHE * from page_test force index(idx_b_id) where b=1 and id<187796 order by id desc limit 10; +----+-------------+-----------+-------+---------------+----------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-----------+-------+---------------+----------+---------+------+------+-------------+ | 1 | SIMPLE | page_test | range | idx_b_id | idx_b_id | 12 | NULL | 190 | Using where | +----+-------------+-----------+-------+---------------+----------+---------+------+------+-------------+ 5 select SQL_NO_CACHE * from page_test force index(idx_b_c) where b=1 order by c desc 870,10 select SQL_NO_CACHE * from page_test force index(idx_b_c) where b=1 order by c asc 9120,10 ./tuning-primer.sh all
优化count(*) Mysiam: select sql_no_cache count(*) from statistic_go where id > 10; select sql_no_cache (select count(*) from statistic_go) - count(*) from statistic_go where id <=10; Innodb : 在缺少where字句的情况下,InnoDB不对count(*)查询进行优化–这个是事实。 SELECT COUNT(*) FROM sbtest1 WHERE id>=0; 建立计数器触发器 对同一个表的select 和update update hotel_image inner join (select count(*) as cnt from hotel_image) as der set hotel_image.size = der.cnt;
其它一些 Group by 不进行排序,可以ordery by null 能够快速缩小结果集的WHERE条件写在前面,如果有恒量条件,也尽量放在前面 使用 UNION 来取代 IN 和 OR 定期执行optimize / analyze table 往innoDB表导入数据时,先关闭autocommit模式,否则会实时刷新数据到磁盘 对于频繁更改的MyISAM表,应尽量避免更新所有变长字段(VARCHAR、BLOB和TEXT) 分表 分库 汇总表 十大热门话题 create table hotel_infonew like hotel_info; rename table hotel_info to hotel_info_old ,hotel_infonew to hotel_info 放弃关系型数据库 key=>value ,计数表
常见架构方案 Replication 双master 集群。。。。。
replication 1 数据分发 ,scale out,sacle up 2 负载均衡 load balance 3 备份,一般不会用作备份,一旦执行delete操作,replication也不会保留 4 高可用 5 可以在不同的主从库上使用不同的存储引擎
简单的讲就是master记录其变化到binlog,slave接收到变化后会记录到他的Relay log,slave通过重放relay log,然后就写进自己的log1)、Slave上面的IO进程连接上Master,并请求从指定日志文件的指定位置(或者从最开始的日志)之后的日志内容;2)、Master接收到来自Slave的IO进程的请求后,通过负责复制的IO进程根据请求信息读取制定日志指定位置之后的日志信息,返回给Slave 的IO进程。返回信息中除了日志所包含的信息之外,还包括本次返回的信息已经到Master端的bin-log文件的名称以及bin-log的位置;3)、Slave的IO进程接收到信息后,将接收到的日志内容依次添加到Slave端的relay-log文件的最末端,并将读取到的Master端的 bin-log的文件名和位置记录到master-info文件中,以便在下一次读取的时候能够清楚的高速Master“我需要从某个bin-log的哪 个位置开始往后的日志内容,请发给我”;4)、Slave的Sql进程检测到relay-log中新增加了内容后,会马上解析relay-log的内容成为在Master端真实执行时候的那些可执行的内容,并在自身执行
常见问题 延迟 主从不同步 命令复制 基于行复制
高可用 通过Heartbert2 让Mysql Replication 具有HA
工具 Innotop Maatkit mk-table-checksum mk-table-sync mk-parallel-dump mk-parallel-restore mk-find Optimize table 脚本
Tools and tips \h命令 大批量数据的导入 load data infile ‘/path/to/file’ into table tbl_name; alter table tbl_name disable keys; alter table tbl_name enable keys; 快速复制表结构: create table clone_tbl select * from tbl_name limit 0 Gdb更改mysql配置 show variables like 'log_slave_updates'; set global log_slave_updates=1; system gdb -p $(pidof mysqld) -ex "set opt_log_slave_updates=1" -batch gdb -p $(pidof mysqld) \ -ex "set max_connections=5000" \ -ex "call resize_thr_alarm(5030)" -batch truncate table 不能复制到从库 perl -ne ‘m/^([^#][^\s=]+)\s*(=.*|)/ && printf(“%-35s%s\n”, $1, $2)’ /etc/mysql/my.cnf 美化my.cnf 加快alter table Dump文件中找出create table sed -e '/./{H;$!d;}' -e 'x;/CREATE TABLE `hotel_info`/!d;q' hotel_new2010-3-1117.sql
同一个团队,同一个梦想 Thanks!