Scheduling for OFDMA
180 likes | 204 Vues
This study delves into the intricate world of OFDMA packet scheduling, uncovering the dark side of Tetris-inspired motivation for split-tier systems. The exploration compares QoS and performance trade-offs, emphasizing the need for specialized and economical scheduling systems. Scalability and performance management are crucial aspects tackled, with a focus on client requests, frame mapping, and scheduling algorithms. Implementing Yonni's scheduling approach, the study reveals insights on prioritization and future testable features for optimal system performance. From smart mappers to synchronized queues, the implementation details shed light on the successful operation of a 2-tiered producer/consumer model. Conclusions drawn from the study highlight synchronization challenges, complex priority calculations, and the balance between performance and QoS. The analysis also delves into the significance of different methods for retrieving requests from the scheduler, drawing comparisons and optimal configurations for bunch and payload retrieval methods. The study concludes with findings on the most stable and reliable method, while also uncovering anomalies that may challenge existing conclusions in the realm of packet scheduling.

Scheduling for OFDMA
E N D
Presentation Transcript
Scheduling for OFDMA The dark side of Tetris
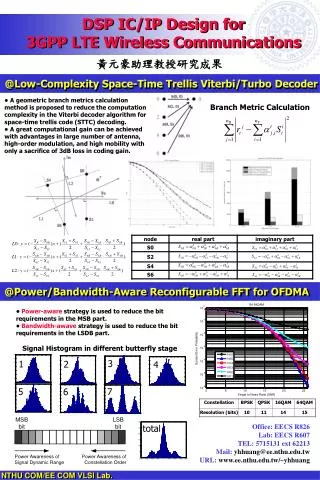
Motivation for split tier system Break apart interests • QoS vs. Performance. • Specialize and economize systems • Scalability and Performance management Client Client Requests frame mapper Scheduling Mechanism Client Client
Scheduling Algorithms • Scheduling algorithms generally boil down to sorting. • Size/ordering dependant: • Smallest first • Largest first • Weighted nodes • Dependency guided – A before B. • Iterative scheduling – constantly improve the scheduling solution towards an optimum.
Available Parameters • Packet Priority: • Age • TTL • Payload size (Stacked priority) • Client Priority • Priority rating • Queue load • Packet bouncing (Stacked priority)
Scheduling ala Yonni • Variation of Weighted ASAP algorithm. • Priority 10 – 0, lower is better. • Expired requests are tossed. • Undersized requests are postponed, to be stacked and resubmitted in the next cycle by the client, with a higher priority. • Future testable features: • Whenever possible, Clients with several packets in the queue should be “joined up”. • Use “consultant queues”. • Prioritize by-client queues. • Backdrop learning scheme: burst clients vs. streaming stable clients.
Implementation • Simple mapper • Sleep for 1ms, popRequestBunch or popRequestPayload • Scheduler • Synchronized, capped queue • Client • Sleep for 5ms, pushRequest with random parameters • Request • TTL and age sensitive ordering • Threading solution • Clients & Mapper run as threads • 2 tiered Producer / Consumer model
Implementation Producers (Clients, not Mel Brooks) create packets and cycle them into the scheduler every 5ms. The scheduler is polled by the frame mapper and grants access to it’s internal queue for frame retrieval. Requests frame mapper Scheduling Mechanism Client Client Clients index Payload index Requests Queue Client Client
Implementation costs • Ran on an AMD64 3000, 1GB DDR machine • Carried a steady and easy queue of 14 clients without expiring any packets. • Cost 9MB of RAM, with fluctuations above and below. • CPU usage was extremely low (5%-7%)
Conclusions • Synchronization is the main bottleneck, but can be eased by “squeezing” retrievals. • Complete resolution is difficult and may cost too much to be useful. • 2nd bottle neck – complex priority calculus. • Simulation may be inadequate without split resources. • “Smarter” schedulers are bogged down by data and become less effective. • It is surprising just how ineffective ring styled queues and other solutions were ineffective. • Too much overhead associated with queue management only increased congestion instead of fragmenting it. • Our scheduling problem is not simply about performance: it is about Quality of service and (reverse) load balancing.
Pop bunch vs. pop payload • Two main methods for popping requests out of the scheduler • By batch: Mapper passes a number representing the number of requests to retrieve • By payload: Mapper passes a number representing the total payload of requests to retrieve
Pop bunch vs. pop payload cont’d… • Both methods were tested against themselves with different values to determine optimum • Optimal configurations were then tested against each other The optimums found: • Bunch method liked the 30x12 mapper frame and pulled the best results with a bunch of 50 requests. • Payload method liked the 12x30 mapper frame and pulled the best results with 0.9 modifier to the payload size
Pop bunch vs. pop payload Results 1. 2. 3. 4.
Pop bunch vs. pop payloadResults explained • Figure 1 shows a comparison between per-client performance records of the two methods • Figure 2 shows a comparison between Mapper performance records • Figure 3 shows a comparison between total throughput • Figure 4 shows a comparison of Mapper tracked request average age (just before delivery)
Pop bunch vs. pop payloadConclusions • These comparisons demonstrate that for the tested parameters, the Payload method is the most stable and reliable, while keeping good QoS. • However, there’s one graph that stands out as a possible question mark to this conclusion and may show that Bunch retrieval still has its uses.
Bunch method anomaly, Cont’d • Of all bunch configurations, only the 20 clients 30x12 configuration showed a near-linear progression. • Pushing the client count to 30 clients shows that linear progression reached a stable peak because the frame was saturated. • Passing an optimal value (30 for 30 clients, and >80 for 20 clients only caused the mapper to return more requests to the scheduler, for failing their delivery. • While Average age was higher than the optimal Payload method configuration (~7ms), the overall performance of this configuration was stable. • This may point out that bunch requests have the ability to withstand heavy loads while gently degrading performance for all clients equally. • Performance degradation such as this may point at scalability.
Conclusions for method comparison • Payload method prefers many small rows for frame configuration as this allows a better resolution for fitting requests together. • Bunch method prefers few large rows since it has more variety of packet sizes to choose from. • Both methods are relevant, in different machine states and may require a smarter scheduler-mapper combination to take full advantage of. • Both methods work around the synchronization bottleneck.
Scheduling for Tetris • Scheduling eventually boils down to sorting an array. • Mappers and schedulers need not be combined • Schedulers should choose Requests that are important to them (for their own reasons) • Mappers should choose from amongst these Requests, the ones most suitable for frame construction • These are two completely different problems that only a fast interface can bridge. • Interfacing the two systems eventually falls upon shared resources which must be synchronized. • I think that a thread safe data structure, capable of sharing or instancing information effectively will increase performance much more than any fancy programming will ever achieve.