Understanding Transport Layer Services: Multiplexing, Reliability, and Protocols in Internet Communication
This document explores the fundamental principles of transport layer services, focusing on multiplexing, demultiplexing, reliable data transfer, flow control, and congestion control. It delves into the transport layer protocols used on the Internet, specifically UDP (connectionless) and TCP (connection-oriented), highlighting their characteristics, segment formats, and the mechanisms for reliable data transfer. Key concepts include the importance of checksums, error detection, and acknowledgment systems within TCP and UDP, which facilitate effective communication between processes on different hosts.


Understanding Transport Layer Services: Multiplexing, Reliability, and Protocols in Internet Communication
E N D
Presentation Transcript
Our goals: understand principles behind transport layer services: multiplexing/demultiplexing reliable data transfer flow control congestion control learn about transport layer protocols in the Internet: UDP: connectionless transport TCP: connection-oriented transport TCP congestion control Chapter 3: Transport Layer
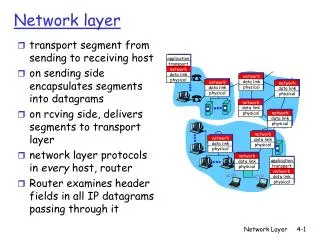
provide logical communication between app processes running on different hosts transport protocols run in end systems reliable, in-order delivery (TCP) unreliable, unordered delivery: UDP application transport network data link physical application transport network data link physical network data link physical network data link physical network data link physical network data link physical network data link physical logical end-end transport Transport services and protocols
application application application transport transport transport P4 P2 P1 P1 P3 network network network link link link physical physical physical Multiplexing at send host: Demultiplexing at rcv host: host 3 host 2 host 1 Multiplexing/demultiplexing delivering received segments to correct socket gathering data from multiple sockets, enveloping data with header (later used for demultiplexing) = socket = process
host receives IP datagrams host uses IP addresses & port numbers to direct segment to appropriate socket UDP socket identified by two-tuple: (dest IP address, dest port number) TCP socket identified by 4-tuple: source IP address source port number dest IP address dest port number How demultiplexing works 32 bits source port # dest port # other header fields application data (message) TCP/UDP segment format
P2 P1 P1 P3 SP: 9157 client IP: A DP: 6428 Client IP:B server IP: C SP: 5775 SP: 6428 SP: 6428 DP: 6428 DP: 9157 DP: 5775 Connectionless demux (cont) DatagramSocket serverSocket = new DatagramSocket(6428); SP provides “return address”
SP: 5775 SP: 9157 P1 P1 P2 P4 P3 P6 P5 client IP: A DP: 80 DP: 80 Connection-oriented demux (cont) S-IP: B D-IP:C SP: 9157 DP: 80 Client IP:B server IP: C S-IP: A S-IP: B D-IP:C D-IP:C
“no frills,” “bare bones” Internet transport protocol “best effort” service, UDP segments may be: lost delivered out of order to app connectionless: no handshaking between UDP sender, receiver each UDP segment handled independently of others Why is there a UDP? no connection establishment (which can add delay) simple: no connection state at sender, receiver small segment header no congestion control: UDP can blast away as fast as desired UDP: User Datagram Protocol [RFC 768]
often used for streaming multimedia apps loss tolerant rate sensitive other UDP uses DNS SNMP reliable transfer over UDP: add reliability at application layer application-specific error recovery! UDP: more 32 bits source port # dest port # Length, in bytes of UDP segment, including header checksum length Application data (message) UDP segment format
Sender: treat segment contents as sequence of 16-bit integers checksum: addition (1’s complement sum) of segment contents sender puts checksum value into UDP checksum field Receiver: compute checksum of received segment check if computed checksum equals checksum field value: NO - error detected YES - no error detected. But maybe errors nonetheless? More later …. UDP checksum Goal: detect “errors” (e.g., flipped bits) in transmitted segment
important in app., transport, link layers characteristics of unreliable channel will determine complexity of reliable data transfer protocol (rdt) Principles of Reliable data transfer
underlying channel perfectly reliable no bit errors no loss of packets Rdt1.0: reliable transfer over a reliable channel
underlying channel may flip bits in packet checksum to detect bit errors the question: how to recover from errors: acknowledgements (ACKs) negative acknowledgements (NAKs) sender retransmits pkt on receipt of NAK new mechanisms in rdt2.0 error detection receiver feedback Rdt2.0: channel with bit errors
What happens if ACK/NAK corrupted? sender doesn’t know what happened at receiver! can’t just retransmit: possible duplicate Handling duplicates: sender adds sequence number to each pkt sender retransmits current pkt if ACK/NAK garbled receiver discards (doesn’t deliver up) duplicate pkt stop and wait rdt2.0 has a fatal flaw! Sender sends one packet, then waits for receiver response
Sender: seq # added to pkt two seq. #’s (0,1) will suffice. must check if received ACK/NAK corrupted Receiver: must check if received packet is duplicate note: receiver can not know if its last ACK/NAK received OK at sender rdt2.1
same functionality as rdt2.1, using ACKs only instead of NAK, receiver sends ACK for last pkt received OK duplicate ACK at sender results in same action as NAK: retransmit current pkt rdt2.2: a NAK-free protocol
New assumption: underlying channel can also lose packets (data or ACKs) checksum, seq. #, ACKs, retransmissions will be of help, but not enough Approach: sender waits “reasonable” amount of time for ACK retransmits if no ACK received in this time if pkt (or ACK) just delayed (not lost): retransmission will be duplicate, but use of seq. #’s already handles this receiver must specify seq # of pkt being ACKed requires countdown timer rdt3.0: channels with errors and loss
Pipelining: sender allows multiple, “in-flight”, yet-to-be-acknowledged pkts range of sequence numbers must be increased buffering at sender and/or receiver Two generic forms of pipelined protocols: go-Back-N, selective repeat Pipelined protocols
Sender: k-bit seq # in pkt header “window” of up to N, consecutive unack’ed pkts allowed Go-Back-N • ACK(n): ACKs all pkts up to, including seq # n - “cumulative ACK” • timer for each in-flight pkt • timeout(n): retransmit pkt n and all higher seq # pkts in window
Go-Back-N Receiver: • ACK-only: always send ACK for correctly-received pkt with highest in-order seq # • may generate duplicate ACKs • need only remember expectedseqnum • out-of-order pkt: • discard (don’t buffer) -> no receiver buffering! • Re-ACK pkt with highest in-order seq #
receiver individually acknowledges all correctly received pkts buffers pkts, as needed, for eventual in-order delivery to upper layer sender only resends pkts for which ACK not received sender timer for each unACKed pkt sender window N consecutive seq #’s again limits seq #s of sent, unACKed pkts Selective Repeat
data from above : if next available seq # in window, send pkt timeout(n): resend pkt n, restart timer ACK(n) in [sendbase,sendbase+N]: mark pkt n as received if n smallest unACKed pkt, advance window base to next unACKed seq # receiver sender Selective repeat pkt n in [rcvbase, rcvbase+N-1] • send ACK(n) • out-of-order: buffer • in-order: deliver (also deliver buffered, in-order pkts), advance window to next not-yet-received pkt pkt n in [rcvbase-N,rcvbase-1] • ACK(n) otherwise: • ignore
full duplex data: connection-oriented: flow controlled: point-to-point: reliable, in-order byte steam: pipelined: send & receive buffers TCP: OverviewRFCs: 793, 1122, 1323, 2018, 2581
32 bits source port # dest port # sequence number acknowledgement number head len not used Receive window U A P R S F checksum Urg data pnter Options (variable length) application data (variable length) TCP segment structure URG: urgent data (generally not used) counting by bytes of data (not segments!) ACK: ACK # valid PSH: push data now (generally not used) # bytes rcvr willing to accept RST, SYN, FIN: connection estab (setup, teardown commands) Internet checksum (as in UDP)
Seq. #’s: byte stream “number” of first byte in segment’s data ACKs: seq # of next byte expected from other side time TCP seq. #’s and ACKs Host B Host A User types ‘C’ Seq=42, ACK=79, data = ‘C’ host ACKs receipt of ‘C’, echoes back ‘C’ Seq=79, ACK=43, data = ‘C’ host ACKs receipt of echoed ‘C’ Seq=43, ACK=80 simple telnet scenario
Q: how to set TCP timeout value? longer than RTT too short: premature timeout too long: slow reaction to segment loss Q: how to estimate RTT? SampleRTT: measured time from segment transmission until ACK receipt SampleRTT will vary, want estimated RTT “smoother” TCP Round Trip Time and Timeout EstimatedRTT = (1- )*EstimatedRTT + *SampleRTT
Setting the timeout EstimtedRTT plus “safety margin” large variation in EstimatedRTT -> larger safety margin first estimate of how much SampleRTT deviates from EstimatedRTT: TCP Round Trip Time and Timeout DevRTT = (1-)*DevRTT + *|SampleRTT-EstimatedRTT| (typically, = 0.25) Then set timeout interval: TimeoutInterval = EstimatedRTT + 4*DevRTT
TCP creates reliable data transfer service on top of IP’s unreliable service Pipelined segments Cumulative acks Retransmissions are triggered by: timeout events duplicate acks TCP reliable data transfer
data rcvd from app: Create segment with seq # seq # is byte-stream number of first data byte in segment start timer if not already running (think of timer as for oldest unacked segment) expiration interval: TimeOutInterval timeout: retransmit segment that caused timeout restart timer Ack rcvd: If acknowledges previously unacked segments update what is known to be acked start timer if there are outstanding segments TCP sender events:
Host A Host B Seq=92, 8 bytes data ACK=100 Seq=92 timeout timeout X loss Seq=92, 8 bytes data ACK=100 time time lost ACK scenario TCP: retransmission scenarios Host A Host B Seq=92, 8 bytes data Seq=100, 20 bytes data ACK=100 ACK=120 Seq=92, 8 bytes data Sendbase = 100 SendBase = 120 ACK=120 Seq=92 timeout SendBase = 100 SendBase = 120 premature timeout
Host A Host B Seq=92, 8 bytes data ACK=100 Seq=100, 20 bytes data timeout X loss ACK=120 time Cumulative ACK scenario TCP retransmission scenarios (more) SendBase = 120
TCP ACK generation[RFC 1122, RFC 2581] TCP Receiver action Delayed ACK. Wait up to 500ms for next segment. If no next segment, send ACK Immediately send single cumulative ACK, ACKing both in-order segments Immediately send duplicate ACK, indicating seq. # of next expected byte Immediate send ACK, provided that segment startsat lower end of gap Event at Receiver Arrival of in-order segment with expected seq #. All data up to expected seq # already ACKed Arrival of in-order segment with expected seq #. One other segment has ACK pending Arrival of out-of-order segment higher-than-expect seq. # . Gap detected Arrival of segment that partially or completely fills gap
Time-out period often relatively long Detect lost segments via duplicate ACKs. If sender receives 3 ACKs for the same data, it supposes that segment after ACKed data was lost Fast Retransmit event: ACK received, with ACK field value of y if (y > SendBase) { SendBase = y if (there are currently not-yet-acknowledged segments) start timer } else { increment count of dup ACKs received for y if (count of dup ACKs received for y = 3) { resend segment with sequence number y } a duplicate ACK for already ACKed segment fast retransmit
receiver speed-matching service: matching the send rate to the receiving app’s drain rate flow control sender won’t overflow receiver’s buffer by transmitting too much, too fast TCP Flow Control • Rcvr advertises spare room by including value of RcvWindow in segments • Sender limits unACKed data to RcvWindow
Three way handshake: Step 1:client host sends TCP SYN segment to server specifies initial seq # no data Step 2:server host receives SYN, replies with SYNACK segment server allocates buffers specifies server initial seq. # Step 3: client receives SYNACK, replies with ACK segment, which may contain data TCP Connection Management
client server close FIN ACK close FIN ACK timed wait closed TCP Connection Management (cont.)
TCP Connection Management (cont) TCP server lifecycle TCP client lifecycle
Congestion: informally: “too many sources sending too much data too fast for network to handle” different from flow control! manifestations: lost packets (buffer overflow at routers) long delays (queueing in router buffers) Principles of Congestion Control
two senders, two receivers one router, infinite buffers no retransmission large delays when congested maximum achievable throughput lout lin : original data unlimited shared output link buffers Host A Host B Causes/costs of congestion: scenario 1
one router, finite buffers sender retransmission of lost packet l l l > = l l l in in in out out out • always: (goodput) • “perfect” retransmission only when loss: • retransmission of delayed (not lost) packet makes larger (than perfect case) for same lout lin : original data finite shared output link buffers Host B Host A Causes/costs of congestion: scenario 2 l'in : original data, plus retransmitted data “costs” of congestion: • more work (retrans) for given “goodput” • unneeded retransmissions: link carries multiple copies of pkt
lout lin : original data l'in : original data, plus retransmitted data finite shared output link buffers Host A Host B Causes/costs of congestion: scenario 3 • four senders • multihop paths • timeout/retransmit • when packet dropped, any “upstream transmission capacity used for that packet was wasted!
End-end congestion control: no explicit feedback from network congestion inferred from end-system observed loss, delay approach taken by TCP Network-assisted congestion control: routers provide feedback to end systems Approaches towards congestion control Two broad approaches towards congestion control:
end-end control (no network assistance) sender limits transmission: LastByteSent-LastByteAcked CongWin Roughly, CongWin is dynamic, function of perceived network congestion How does sender perceive congestion? loss event = timeout or 3 duplicate acks TCP sender reduces rate (CongWin) after loss event three mechanisms: AIMD slow start conservative after timeout events CongWin rate = Bytes/sec RTT TCP Congestion Control
multiplicative decrease: cut CongWin in half after loss event TCP AIMD additive increase: increase CongWin by 1 MSS every RTT in the absence of loss events: probing Long-lived TCP connection
When connection begins, increase rate exponentially until first loss event: double CongWin every RTT done by incrementing CongWin for every ACK received Summary: initial rate is slow but ramps up exponentially fast time TCP Slow Start Host A Host B one segment RTT two segments four segments
After 3 dup ACKs: CongWin is cut in half window then grows linearly (congestion avoidance) But after timeout event: CongWin instead set to 1 MSS; window then grows exponentially (slow start) to a threshold, then grows linearly (congestion avoidance) Refinement
Summary: TCP Congestion Control • When CongWin is below Threshold, sender in slow-start phase, window grows exponentially. • When CongWin is above Threshold, sender is in congestion-avoidance phase, window grows linearly. • When a triple duplicate ACK occurs, Threshold set to CongWin/2 and CongWin set to Threshold. • When timeout occurs, Threshold set to CongWin/2 and CongWin is set to 1 MSS.
TCP throughput • What’s the average throughout of TCP as a function of window size and RTT? • Ignore slow start • Let W be the window size when loss occurs. • When window is W, throughput is W/RTT • Just after loss, window drops to W/2, throughput to W/2RTT. • Average throughout: .75 W/RTT
TCP Futures • Example: 1500 byte segments, 100ms RTT, want 10 Gbps throughput • Requires window size W = 83,333 in-flight segments • Throughput in terms of loss rate: • ➜ L = 2·10-10 Wow • New versions of TCP for high-speed needed!