GENE,STRUCTURE,FUNCTION
explain gene,DNA,


GENE,STRUCTURE,FUNCTION
E N D
Presentation Transcript
UNEVIRSITY OF GAZIANTEP DEPERTMENT OF BIOCHEMISTRY SCEINCE AND TECHNOLOGY PRESENTATION ABOUT GENES, STRUCTURE AND FUNCTIONS BY: MUSTFA TALIB SALEEM APRIL|2020 Prof: CANAN CAN
content • genes, structure and functions • DNA • RNA • mutation • Chromosome • allele • genotype • phenotype • summary
What is the gene • a gene is a sequence of nucleotides in DNA or RNA that encodes the synthesis of a gene product, either RNA or protein. • During gene expression, the DNA is first copied into RNA. The RNA can be directly functional or be the intermediate template for a protein that performs a function. The transmission of genes to an organism's offspring is the basis of the inheritance of phenotypic trait. • These genes make up different DNA sequences called genotypes. Genotypes along with environmental and developmental factors determine what the phenotypes will be. Most biological traits are under the influence of polygenes (many different genes) as well as gene–environment interactions.
Structure and function • The structure of a gene consists of many elements of which the actual protein coding sequence is often only a small part. These include DNA regions that are not transcribed as well as untranslated regions of the RNA. • Flanking the open reading frame, genes contain a regulatory sequence that is required for their expression. First, genes require a promoter sequence • The promoter is recognized and bound by transcription factors that recruit and help RNA polymerase bind to the region to initiate transcription • The recognition typically occurs as a consensus sequence like the TATA box. A gene can have more than one promoter, resulting in messenger RNAs (mRNA) that differ in how far they extend in the 5' end.
Figure [2] Regulatory sequence controls when and where expression occurs for the protein coding region (red). Promoter and enhancer regions (yellow) regulate the transcription of the gene into a pre-mRNA which is modified to remove introns (light grey) and add a 5' cap and poly-A tail (dark grey). The mRNA 5' and 3' untranslated regions (blue) regulate translation into the final protein product
Additionally, genes can have regulatory regions many kilobases upstream or downstream of the open reading frame that alter expression. • These act by binding to transcription factors which then cause the DNA to loop so that the regulatory sequence (and bound transcription factor) become close to the RNA polymerase binding site. • For example, enhancers increase transcription by binding an activator protein which then helps to recruit the RNA polymerase to the promoter; conversely silencers bind repressor proteins and make the DNA less available for RNA polymerase
Functional definitions • Defining exactly what section of a DNA sequence comprises a gene is difficult • Regulatory regions of a gene such as enhancers do not necessarily have to be close to the coding sequence on the linear molecule because the intervening DNA can be looped out to bring the gene and its regulatory region into proximity. • Similarly, a gene's introns can be much larger than its exons. Regulatory regions can even be on entirely different chromosomes and operate in trans to allow regulatory regions on one chromosome to come in contact with target genes on another chromosome. • Early work in molecular genetics suggested the concept that one gene makes one protein. This concept (originally called the one gene-one enzyme hypothesis) emerged from an influential 1941 paper by George Beadle and Edward Tatum on experiments with mutants of the fungus Neurospora.
Figure[3]Genetic Drift / Population Bottleneck Effect. OpenStax, Rice University/Wikimedia Commons
Gene expression • is the process by which information from a gene is used in the synthesis of a functional gene product. • These products are often proteins, but in non-protein coding genes such as transfer RNA (tRNA) or small nuclear RNA (snRNA) genes, the product is a functional RNA. • Gene expression is summarized in the Central Dogma first formulated by Francis Crick in 1958, further developed in his 1970 article, and expanded by the subsequent discoveries of reverse transcription and RNA replication. • The process of gene expression is used by all known life—eukaryotes (including multicellular organisms), prokaryotes (bacteria and archaea), and utilized by viruses—to generate the macromolecular machinery for life. • In genetics, gene expression is the most fundamental level at which the genotype gives rise to the phenotype, i.e. observable trait. • The genetic information stored in DNA represents the genotype, whereas the phenotype results from the "interpretation" of that information.
Figure[4]The extended Central Dogma of molecular Biology includes all the cellular processes involved in the flow of genetic information
Gene Expression and Life Expectancy • Manipulating TFs to reverse the cell differentiation process is the basis of methods for deriving stem cells from adult tissues. • The ability to control gene expression, along with knowledge obtained from studying the human genome and genomics in other organisms, has led to the theory that we can prolong our lives if we just control the genes that regulate the aging process in our cells.
What Is CRISPR? • CRISPR (pronounced "crisper") is the acronym for Clustered Regularly Interspaced Short Repeats, a group of DNA sequences found in bacteria that act as a defense system against viruses that could infect a bacterium. • CRISPRs are a genetic code that is broken up by "spacers" of sequences from viruses that have attacked a bacterium. If the bacteria encounter the virus again, a CRISPR acts as a sort of memory bank, making it easier to defend the cell.
Figure[4]The CRISPR-CAS9 gene editing complex from Streptococcus pyogenes: The Cas9 nuclease protein uses a guide RNA sequence (pink) to cut DNA at a complementary site (green). MOLEKUUL/SCIENCE PHOTO LIBRARY / Getty Images
Uses of CRISPR • Applying CRISPR to prevent and treat HIV, cancer, sickle-cell disease, Alzheimer's, muscular dystrophy, and Lyme disease. Theoretically, any disease with a genetic component may be treated with gene therapy. • Developing new drugs to treat blindness and heart disease. CRISPR/Cas9 has been used to remove a mutation that causes retinitis pigmentosa. • Extending the shelf life of perishable foods, increase the resistance of crops to pests and diseases, and increase nutritional value and yield. For example, a Rutgers University team has used the technique to make grapes resistant to downy mildew.
Figure[5]CRISPR can be used to develop new drugs used for gene therapy. DAVID MAC
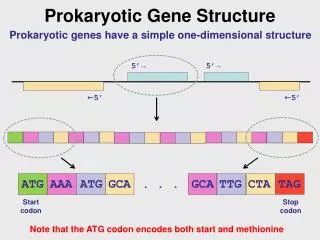
Genetic code • The nucleotide sequence of a gene's DNA specifies the amino acid sequence of a protein through the genetic code. • Sets of three nucleotides, known as codons, each correspond to a specific amino acid. The principle that three sequential bases of DNA code for each amino acid was demonstrated in 1961 using frameshift mutations in the rIIB gene of bacteriophage T4 • Additionally, a "start codon", and three "stop codons" indicate the beginning and end of the protein coding region. • There are 64 possible codons (four possible nucleotides at each of three positions, hence 43 possible codons) and only 20 standard amino acids; hence the code is redundant and multiple codons can specify the same amino acid. The correspondence between codons and amino acids is nearly universal among all known living organisms.
Figure [6] Schematic of a single-stranded RNA molecule illustrating a series of three-base codons. Each three-nucleotide codon corresponds to an amino acid when translated to protein
DNA • The building blocks of nucleic acids are nucleotides. • Nucleotides that compose DNA are called deoxyribonucleotides. • The three components of a deoxyribonucleotide are a five-carbon sugar called deoxyribose, a phosphate group, and a nitrogenous base, a nitrogen-containing ring structure that is responsible for complementary base pairing between nucleic acid strands • (Figure 4). The carbon atoms of the five-carbon deoxyribose are numbered 1ʹ, 2ʹ, 3ʹ, 4ʹ, and 5ʹ (1ʹ is read as “one prime”). A nucleoside comprises the five-carbon sugar and nitrogenous base. • DNA) is responsible for carrying and retaining the hereditary information in a cell
Figure [ 7] (a) Each deoxyribonucleotide is made up of a sugar called deoxyribose, a phosphate group, and a nitrogenous base—in this case, adenine. (b) The five carbons within deoxyribose are designated as 1ʹ, 2ʹ, 3ʹ, 4ʹ, and 5ʹ.
The deoxyribonucleotide is named according to the nitrogenous bases (Figure 5). The nitrogenous bases adenine (A) and guanine (G) are the purines; they have a double-ring structure with a six-carbon ring fused to a five-carbon ring. The pyrimidines, cytosine (C) and thymine (T), are smaller nitrogenous bases that have only a six-carbon ring structure. Figure[ 8] Nitrogenous bases within DNA are categorized into the two-ringed purines adenine and guanine and the single-ringed pyrimidines cytosine and thymine. Thymine is unique to DNA.
Individual nucleoside triphosphates combine with each other by covalent bonds known as 5ʹ-3ʹ phosphodiester bonds • or linkages whereby the phosphate group attached to the 5ʹ carbon of the sugar of one nucleotide bonds to the hydroxyl group of the 3ʹ carbon of the sugar of the next nucleotide. • Phosphodiester bonding between nucleotides forms the sugar-phosphate backbone, the alternating sugar-phosphate structure composing the framework of a nucleic acid strand (Figure 6). • During the polymerization process, deoxynucleotide triphosphates (dNTP) are used. To construct the sugar-phosphate backbone, the two terminal phosphates are released from the dNTP as a pyrophosphate. The resulting strand of nucleic acid has a free phosphate group at the 5ʹ carbon end and a free hydroxyl group at the 3ʹ carbon end. • The two unused phosphate groups from the nucleotide triphosphate are released as pyrophosphate during phosphodiester bond formation
Figure [9] Phosphodiester bonds form between the phosphate group attached to the 5ʹ carbon of one nucleotide and the hydroxyl group of the 3ʹ carbon in the next nucleotide, bringing about polymerization of nucleotides in to nucleic acid strands. Note the 5ʹ and 3ʹ ends of this nucleic acid strand.
DNA Structure • Watson and Crick proposed that DNA is made up of two strands that are twisted around each other to form a right-handed helix. • The two DNA strands are antiparallel, such that the 3ʹ end of one strand faces the 5ʹ end of the other (Figure9 ). • The 3ʹ end of each strand has a free hydroxyl group, while the 5ʹ end of each strand has a free phosphate group. The sugar and phosphate of the polymerized nucleotides form the backbone of the structure, whereas the nitrogenous bases are stacked inside • These nitrogenous bases on the interior of the molecule interact with each other, base pairing.
Figure [ 10] Watson and Crick proposed the double helix model for DNA. (a) The sugar-phosphate backbones are on the outside of the double helix and purines and pyrimidines form the “rungs” of the DNA helix ladder. (b) The two DNA strands are antiparallel to each other. (c) The direction of each strand is identified by numbering the carbons (1 through 5) in each sugar molecule. The 5ʹ end is the one where carbon #5 is not bound to another nucleotide; the 3ʹ end is the one where carbon #3 is not bound to another nucleotide.
Base pairing takes place between a purine and pyrimidine. • In DNA, adenine (A) and thymine (T) are complementary base pairs, and cytosine (C) and guanine (G) are also complementary base pairs, explaining Chargaff’s rules (Figure 8). • The base pairs are stabilized by hydrogen bonds; adenine and thymine form two hydrogen bonds between them, whereas cytosine and guanine form three hydrogen bonds between them.
Figure [11] Hydrogen bonds form between complementary nitrogenous bases on the interior of DNA.
RNA • Structurally speaking, ribonucleic acid (RNA), is quite similar to DNA. • However, whereas DNA molecules are typically long and double stranded, RNA molecules are much shorter and are typically single stranded. • RNA molecules perform a variety of roles in the cell but are mainly involved in the process of protein synthesis (translation) and its regulation. • RNA is typically single stranded and is made of ribonucleotides that are linked by phosphodiester bonds. • A ribonucleotide in the RNA chain contains ribose (the pentose sugar), one of the four nitrogenous bases (A, U, G, and C), and a phosphate group. • The subtle structural difference between the sugars gives DNA added stability, making DNA more suitable for storage of genetic information, whereas the relative instability of RNA makes it more suitable for its more short-term functions • The RNA-specific pyrimidine uracil forms a complementary base pair with adenine and is used instead of the thymine used in DNA.
Figure [12] (a) Ribonucleotides contain the pentose sugar ribose instead of the deoxyribose found in deoxyribonucleotides. (b) RNA contains the pyrimidine uracil in place of thymine found in DNA
Figure [13] (a) DNA is typically double stranded, whereas RNA is typically single stranded. (b) Although it is single stranded, RNA can fold upon itself, with the folds stabilized by short areas of complementary base pairing within the molecule, forming a three-dimensional structure.
Types of RNA • RNA molecules are produced in the nucleus of our cells and can also be found in the cytoplasm. The three primary types of RNA molecules are messenger RNA, transfer RNA and ribosomal RNA. 1-Messenger RNA (or mRNA) • sequence to the DNA found there. • The enzyme that puts this strand of mRNA together is called RNA polymerase • Three has the main role in transcription, or the first step in making a protein from a DNA blueprint. • The mRNA is made up of nucleotides found in the nucleus that come together to make a complementary adjacent nitrogen bases in the mRNA sequence is called a codon and they each code for a specific amino acid that will then be linked with other amino acids in the correct order to make a protein.
There many regions of DNA that do not code for any genetic information. • These non-coding regions are still transcribed by mRNA. • This means the mRNA must first cut out these sequences, called introns, before it can be coded into a functioning protein. • The parts of mRNA that do code for amino acids are called exons. The introns are cut out by enzymes and only the exons are left.
Figure [14] mRNA is translated into a polypeptide
2-Transfer RNA (tRNA) • Transfer RNA (or tRNA) has the important job of making sure the correct amino acids are put into the polypeptide chain in the correct order during the process of translation. • It is a highly folded structure that holds an amino acid on one end and has what is called an anticodon on the other end. • The tRNA anticodon is a complementary sequence of the mRNA codon. • The tRNA is therefore ensured to match up with the correct part of the mRNA and the amino acids will then be in the right order for the protein • More than one tRNA can bind to mRNA at the same time and the amino acids can then form a peptide bond between themselves before breaking off from the tRNA to become a polypeptide chain that will be used to eventually form a fully functioning protein.
Figure [15] tRNA will bind an amino acid to one end and has an anticodon on the other.
Figure[16]mRNA, tRNA, and rRNA are associated with translation of genetic information into proteins. Fancy Tapis / Getty Images
3-Ribosomal RNA (rRNA) • Ribosomal RNA (or rRNA) is named for the organelle it makes up. • The ribosome is the eukaryotic cell organelle that helps assemble proteins. • Since rRNA is the main building block of ribosomes, it has a very large and important role in translation. • It basically holds the single stranded mRNA in place so the tRNA can match up its anticodon with the mRNA codon that codes for a specific amino acid. • There are three sites (called A, P, and E) that hold and direct the tRNA to the correct spot to ensure the polypeptide is made correctly during translation • These binding sites facilitate the peptide bonding of the amino acids and then release the tRNA so they can recharge and be used again.
Figure [17] Ribosomal RNA (rRNA) helps facilitate the bonding of amino acids coded for by the mRNA.
4-Micro RNA (miRNA) • Also involved in gene expression is micro RNA (or miRNA) • miRNA is a non-coding region of mRNA that is believed to be important in the either promotion or inhibition of gene expression. • These very small sequences (most are only about 25 nucleotides long) seem to be an ancient control mechanism that was developed very early in the evolution of eukaryotic cells. • Most miRNA prevent transcription of certain genes and if they are missing, those genes will be expressed. miRNA sequences are found in both plants and animals, but seem to have come from different ancestral lineages and are an example of convergent evolution.
Figure [18] miRNA is thought to be a control mechanism leftover from evolution.