Download

1 / 1
40 likes | 260 Vues
Mining Genotype-Phenotype Associations from Electronic Health Records and Biorepositories using Semantic Web Technologies

E N D
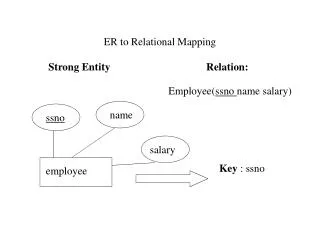
Mining Genotype-Phenotype Associations from Electronic Health Records and Biorepositories using Semantic Web Technologies Jyotishman Pathak, PhD Richard C. Kiefer, Robert R. Freimuth, PhD Suzette J. Bielinski, PhD Christopher G. Chute, MD, DrPHDivision of Biomedical Statistics and Informatics, Department of Health Sciences Research Mayo Clinic, Rochester, MN Background and Aims From Relational Data Model to RDF Mapping to Querying via SPARQL • The Linked Clinical Data (LCD) project at aims to develop a semantics-driven framework for high-throughput phenotype representation, extraction, integration, and querying from electronic medical records using emerging Semantic Web technologies, such as the W3C’s Linking Open Data project . • The main goals of the LCD project are to: • Investigate ontology-based techniques for representing and encoding phenotype data derived from EHRs; • Develop a framework for publishing and integrating ontology-encoded structured phenotype data for federated querying using Linked Data principles and technologies, and • Propose and validate semantic reasoning techniques to support rapid cohort identification in chronicdiseases. • Linked Data refers to a set of best practices for publishing and linking pieces of data, information and knowledge in the Web. • Core technologies supporting Linked Data: • URIs for identifying entities or concepts, • RDF data model and RDFS/OWL ontologies for representing, structuring and linking descriptions of entities as resources, • An endpoint providing access to the resources through SPARQL queries and • HTTP for retrieving resources or descriptions of the resources. • W3C Linked Open Data project • 2007 - 2 billion RDF triples, 2 million links • 2011 - 31 billion RDF triples, 504 million links SELECT ?ClinicNumber ?Diagnosis WHERE { SERVICE <http://edison.mayo.edu:8890/sparql> { ?s1 snomedct:3982250 ?clinicId . ?s1 gc:mayogcid ?mayogcId . ?s2 snomedct:3982250 ?patientId . ?s2 so:SO_0000694 ?rsId . ?s2 so:SO_0001027 ?genotype . FILTER (?patientId =?clinicId ) } SERVICE <http://hsrdev02:8890/sparql> { ?s3 mclss: internalKey ?table1Key . ?s3 tmo:TMO_0031 ?Diagnosis . ?s4 mclss: internalKey ?table2Key . ?s4 snomedct:3982250 ?ClinicNumber. FILTER (?table1Key = ?table2Key ) . } FILTER(?ClinicNumber = ?mayogcid) . FILTER(regex(str(?rsId), "rs5219", "i")) . FILTER(regex(str(?genotype), “T:T", "i")) . } @prefix rr: <http://www.w3.org/ns/r2rml#>. @prefix mayogc: <http://mayogc/>. @prefix snomedct: <http://purl.bioontology.org/ontology/SNOMEDCT#>. @prefix so: <http://purl.org/obo/owl/SO#>. mayogc:PatientsMap a rr:TriplesMapClass; rr:tableName "patients_hypothyroidism"; rr:subjectMap [ rr:template "http://patients/{clinicId}" ]; rr:predicateObjectMap [ rr:predicateMap [ rr:predicate snomedct:3982250]; rr:objectMap [ rr:column "clinicId" ] ]; rr:predicateObjectMap [ rr:predicateMap [ rr:predicate mayogc:mayogid ]; rr:objectMap [ rr:column "mayogid" ] ]. mayogc:GenesMap a rr:TriplesMapClass; rr:tableName "patient_genotypes"; rr:subjectMap [ rr:template "http://genes/{patientId}" ]; rr:predicateObjectMap [ rr:predicateMap [ rr:predicate snomedct:3982250]; rr:objectMap [ rr:column "patientId" ] ]; rr:predicateObjectMap [ rr:predicateMap [ rr:predicate so:SO_0000694 ]; rr:objectMap [ rr:column "rsId" ] ]; rr:predicateObjectMap [ rr:predicateMap [ rr:predicate so:SO_0001027 ]; rr:objectMap [ rr:column "genotype" ] ]. patient_genotypes For more information – http://informatics.mayo.edu/LCD rsID rs5219 patientId 18299403 genotype T:T patient_demographics clinicId 18299403 MayogcId 17297 wh_demographics ClinicNumber 17297 table1Key RK4748 wh_diagnosis diagnosis Type2 diabetes table2Key RK4748 • Map the model to express the relationship between nodes/edges • Write a SPARQL query based on the mapping • Workflow diagram of how the data is traversed • Use an ontology to describe the columns of the relational database • Sample query results Architecture Methods Results: Type 2 Diabetes Mellitus SNP-disease associations for T2DM SNP rs5219 within the gene KCNJ11 • The work proposed in this study is an attempt to use Semantic Web technologies for integrating patient clinical data derived from Electronic Health Records (EHRs) with large-scale genomics data to study genotype-phenotype associations. This aim is achieved via: • RDF-based representation of clinical data from Mayo Clinic EHR systems exposed via multiple SPARQL endpoints • Patient demographics, diagnoses, procedures and medications • Coded with Meaningful Use terminologies • RDF-based representation of genetic data from Mayo Clinic biobank repository exposed via a SPARQL endpoint • Patient single nucleotide polymorphism (SNP) genotype data • Coded with gene and sequence ontologies • Federated SPARQL 1.1 queries integrating genotype data with patient clinical data • Perform a Phenome-Wide Association Study (PheWAS) that allows a systematic study of associations between a number of common genetic variations and variety of large number of clinical phenotypes Linked Data • A query determines all the individuals having a SNP associated with Type 2 Diabetes Mellitus and retrieves the clinical diagnoses (represented as ICD-9-CM codes) for each eligible subject • Using AHRQ’s Clinical Classification Software, clustering is done for creating a manageable number of clinically meaningful categories • Client applications send query requests • Using the Linked Data API, the request is translated into a federated SPARQL 1.1 query • Patient data stored in RDBMS are surfaced as an endpoint • SPARQL queries are automatically translated into SQL statements using applications, such as Spyder • Results are returned in XML, RDF or JSON formats