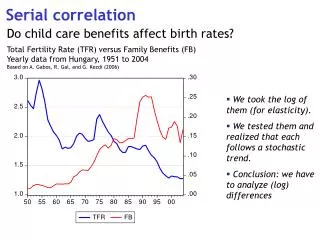
Serial Correlation
Serial Correlation. Serial Correlation. Refers to a violation of the classical linear regression model’s key assumption that the error terms are uncorrelated across different observations.


Serial Correlation
E N D
Presentation Transcript
Serial Correlation • Refers to a violation of the classical linear regression model’s key assumption that the error terms are uncorrelated across different observations. • It occurs most frequently in time series data sets, where the error from one period may be related to the error terms in the previous or subsequent periods.
Example: Labour Demand Model • Consider the following firm level labour demand model based on a time series data. lt =β0 +β1wt +β2 yt + εt t=1,…,T In this equation t indexes year, l is log of labour demand, w is the log wage faced by the, y is log of its expected output, and ε represents the usual disturbance/error term.
If the ε’s are independently, identically and normally distributed, we can estimate the β’s using OLS and use the t and F statistics for inference, just like we did in the cross section models • But in time series data the assumption that the errors are independent of one another should not be taken for granted
Usually the sign of last period’s ε could be a good indicator of the sign of this period’s ε. • We can write the relationship between current and past disturbance terms as εt = εt-1 + u • The random variable u represents a classical error term with mean zero and variance σ2, and ρ denotes the first-order autocorrelation coefficient. It is assumed that | ρ |<1
This functional form is sometimes called a first-order Markov scheme or a first-order autoregressive process - AR (1) for short.
A positive value of ρ indicates that the error term tends to have the same sign from one observation to the next (positive serial correlation). • A negative value indicates that the error term tends to have the opposite sign from one observation to the next.
There are other forms of serial correlation. • For example, if we are looking at quarterly time-series data, the current quarter’s error term might be functionally related to the observation of the error term from the same quarter of the previous year, in which case we would have a seasonal serial correlation: εt = ρεt-4 + u
Some Sources of Serial Correlation 1. The use of incorrect functional form (e.g., a linear form when a nonlinear one should be used) 2. Factors omitted from the time-series regression that are correlated across periods.
Some Sources of Serial Correlation • Another significant cause of serial is that there is usually momentum built into most time series. For instance, data for the GNP can have high interdependence in between successive values. Because of this, a regression involving GNP could result in error terms that are also highly interdependent.
WHY does autocorrelation occur? Certain economic time series data such as GDP, employment, money supply, inflation etc., exhibit business cycles. Starting at the bottom of a recession once economic recovery starts most of these variables start to ↑ Hence in time series data successive observations are likely to be interdependent i.e. correlated – correlated error terms.
4. Data manipulation Time series data can often have the frequency of intervals manipulated.
Such averaging – smooths the data by dampening monthly fluctuations – can lead to systematic pattern in disturbances. 5. Model specification errors • autocorrelation can occur due to model mis-specification rather than correlation between successive observations.
Mis-specification could be due to omitted variables, or incorrect functional form. If such model mis-specification occurs then the residuals will exhibit a systematic pattern.
Consequences of Serial Correlation 1. Estimates remain unbiased Regardless of autocorrelation the estimates of the β’s will still be centred around the true population β’s. 2. Variance The property of minimum variance no longer holds i.e. not efficient. This means that the variance and SE will generally be biased – no longer BLUE. 3. Hypothesis testing The usual confidence intervals and hypothesis tests based upon the t and F distribution are no longer reliable
Detecting Serial Correlation • In terms of detection we face the same problems as when trying to detect heteroscedasticity • ⇒ in that we do not know the true error variance σ2 since the error terms ε are unobservable. • We only have proxies the e’s.
Detecting Serial Correlation Graphical approach • This approach is useful as a starting point. • After running an OLS model it is always useful to investigate the residuals i.e. ε.
If autocorrelation exists - Cov (i j)≠ 0 • This says that the disturbance related to the ith observation is related to or influenced by the disturbance related to any other observation i.e. j
However, the graphical approaches are simply a diagnostic tool and not a formal procedure for identifying serial correlation
Testing for Serial Correlation • One way to detect for the presence of serial correlation would be to examine a plot of the residuals. But it bears to remember that residuals are not the same as the true disturbances, so this approach might be misleading. • And even if we did appear to see indications of serial correlation, these just might represent errors in model specification.
(1) Durbin-Watson test. • This is the most common formal method of testing for autocorrelation. The null hypothesis in this test is that ρ = 0 (no serial correlation). The alternative hypothesis will depend on the situation, but could be 0 < ρ < 1 (positive serial correlation) or –1 < ρ < 0 (negative serial correlation)
The Durbin-Watson test can only be performed under the following conditions: (i) The regression model includes an intercept term. (ii) The serial correlation is first-order in nature. (iii) The observations have been ordered from 1 to T corresponding to the passage of time. (iv) The regression model does not include a lagged dependent variable
The Mechanics of the Durbin-Watson test: • Run the OLS regression to obtain the residuals (εt) • Calculate the test statistic, d, as • The d statistic is approximately equal to 2(1-r), where r is the correlation between εtand εt-1 . Hence it varies from 0 (extreme positive serial correlation) to 4 (extreme negative serial correlation), with a value of 2 indicating no serial correlation.
3. Compare the test statistic with the appropriate critical values and determine whether to accept or reject the null hypothesis of no serial correlation.
The Durbin-Watson test is unusual in that it has an inconclusive region. One cannot look at a table for the critical value of d but can find only upper and lower bounds for the critical value (dU and dL, respectively). Hence if the calculated value of d falls within those bounds, the test will be inconclusive.
The Following labour demand model is estimated on the basis of 30 observations
Eviews give a d statistics of 0.534, also indicating that there are 3 regressors and 30 observations in the model • The number of regressors without the intercept is of course 2, and at 5% level of significance the tabulated critical values are dL = 1.284 and dU = 1.567. Thus there is evidence of positive serial correlation.
The Durbin-Watson test is restrictive because (i) it depends on the data matrix, (ii) its inconclusive region, (iii) it may not be very as accurate if the error term is not AR(1), and (iv) it does not allow for lagged dependent variables.
(2) Breusch-Godfrey Test • The Breusch-Godfrey test is a less restrictive alternative. • To perform a Breusch-Godfrey test of the hypothesis
The computed BG statistic (13.953) exceeds the tabulated chi-squared value with 2 degrees of freedom (5.99 at 5% level). There is evidence of serial correlation, a result that is consistent with the D-W test.
Dealing with serial correlation • If serial correlation is detected we can transform the equation using the method of generalised least squares (GLS). • With AR(1) error we can rewrite the labour demand equation as lt = β1+ β2wt + β3yt + ρεt-1+ ut • The above equation is obviously not a basis for estimation: the second-to-last term is unobservable.
We obtain an estimable model by multiplying the original equation by the AR(1) coefficient and then lagging the new equation by one time period. Then subtract this from the original model to obtain: • where an asterisk indicates that a variable zt has been transforme .
This “quasi-differenced” equation has a non-serially correlated • error (by assumption), and the slope coefficient on the quasi differenced variable is the same as in the original equation. • But there is a catch (no free lunch in econometrics!). We need an estimate of ρ to get us going.
There are several methods of dealing with this problem. Here we follow the Prais-Winsten procedure: (i) Estimate the equation using OLS to get the residuals. (ii) Regress the residuals on their lagged values to get an estimate of ρ. (iii) Then use this estimate of ρ to run the GLS regression.
Instead of stopping at this point, use the residuals from step (iii) to redo step (ii), the results of which would then be used to redo step (iii) and so forth. • This iteration would continue until there was “convergence” in the estimate of ρ; i.e., it did not change much after an additional iteration of steps (ii) and (iii).
Fortunately EVIEWs can so this for you, but you have to understand the logic of this technique! • The transformed DW is 2.164, and it is within the no autocorrelation region.
But a word of caution , to get a good estimate for ρ, GLS requires a large sample size as it relies on asymptotic properties (can this explain the “odd” result that that wage rates don’t matter for labour demand?)
Analogous to White standard errors for heteroskedasticity, there are Newey-West errors standard errors that adjust conventionally measured standard errors to account for serial correlation and heteroskedasticity. • For our labour demand model we present two examples on how to generate results with Newey-West errors, the first with an assumed AR(1) error structure, the second with an AR(2) structure.
Notice that the coefficients are the same as the OLS coefficients, but the standard errors are different, and they are valid for making inference. • Notice that the standard errors are sensitive to the assumed AR structure. For example in the second model, the wages coefficient turns out to be insignificant at 5% level.
Serial correlation in dynamic models • Models with lagged dependent variables (also known as dynamic models) arise naturally in many economic problems. • For example the presence of adjustment costs (hiring and firing costs) means that it takes time for firms to reach their optimal level of labour demand. This means there is persistence (or inertia) in the system, and current labour demand depends on previous level of demand.