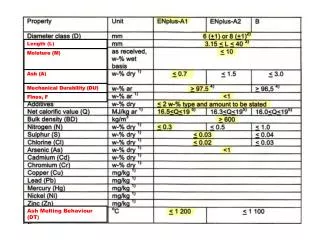
ASH: A Scalable Architecture Leveraging Reconfigurable Hardware and Traditional CPUs
420 likes | 533 Vues
The ASH (Application-Specific Hardware) architecture proposes a hybrid model combining reconfigurable hardware (RH) and traditional CPUs, overcoming limitations like power, global signals, and limited issue windows that affect scalability and performance. This architecture enables unbounded computational bandwidth and facilitates dynamic scheduling, matching program parallelism. ASH scales with clock frequency, hardware capabilities, and program size, enhancing performance through compiler-driven solutions while exploiting application-specific hardware advantages.

ASH: A Scalable Architecture Leveraging Reconfigurable Hardware and Traditional CPUs
E N D
Presentation Transcript
ASH: A Substrate for Scalable Architectures Mihai Budiu Seth Copen Goldstein http://www.cs.cmu.edu/~phoenix CALCM Seminar, March 19, 2002
Resources /32
CPU Problems • Complexity • Power • Global Signals • Limited issue window => limited ILP We propose an architecture with none of these limits /32
Outline • Scalability • Reconfigurable hardware advantages • A hybrid RH + CPU architecture • CPU and RH as peers • Application Specific Hardware /32
Unbounded * a=a+b b=b+c + / RH Computational Bandwidth FU * clock freq CPU /32
i j k l m sp[0] spill Registers Unbounded Fixed eax ebx ecx edx CPU RH /32
Unbounded RH Register Bandwidth Fixed R1 R2 R3 W1 W2 CPU /32
Out-of-Order Execution In-order Fetch Decode Execute Dispatch Commit Limited by window CPU RH Compiler’s window is unbounded /32
Outline • Scalability • Reconfigurable hardware advantages • A hybrid RH + CPU architecture • CPU and RH as peers • Application Specific Hardware /32
Hybrid system: CPU+RH Tight coupling Low ILP + OS + VM generic CPU RH High ILP application-specific Memory /32
CPU RH Memory Problem HLL Program Compiler /32
Our Solution • General: applicable to today’s software • Automatic: compiler-driven [RISC approach] • Scalable: with clock, hardware and program size • Parallelism: exploit application parallelism • bit-level • ILP • pipeline • loop-level /32
Outline • Scalability • Reconfigurable hardware advantages • A hybrid RH + CPU architecture • CPU and RH as peers • Application Specific Hardware /32
Peering Program a( ) { b( ); } b( ) { c( ); } c( ) { d( ) } d( ) { } a CPU RH b c d /32
marshalling, control transfer software procedure call hardware dependent Stubs built automatically. “RPC” CPU RH a b’ b c’ c d’ d /32
Program Partitioning Procedures for CPU Procedures for RH Linker RH Compiler Stubs Executable Configuration Stub Synthesis /32
Outline • Scalability • Reconfigurable hardware advantages • A hybrid RH + CPU architecture • CPU and RH as peers • Application Specific Hardware /32
CPU RH Memory Application-Specific Hardware HLL program HLL Program Compiler Compiler Circuit Reconfigurablehardware /32
Circuits Memory partitioning Interconnection net CASH: Compiling for ASH C Program RH /32
Asynchronous Computation + ack data data ready Can extend to locally synchronous, globally asynchronous /32
Dataflow Graphs int plus(int x, int y) { return x + y; } /32
Conditionals = Speculation int cond(int p, int x, int y) { int z; if (p) z = x; else z = y; return z; } /32
- > Critical Paths b x 0 if (x > 0) y = -x; else y = b*x; * ! y /32
- > Executing Lenient Operators b x 0 if (x > 0) y = -x; else y = b*x; * ! y Up to 40% performance improvement. /32
Pipelining /32
Loop Pipelining /32
Loop Pipelining /32
ASH Features • What you code is what you get • no hidden control logic • really lean hardware (no CAM, decoders, multiported files, etc.) • Compiler has complete control • Dynamic scheduling => latency tolerant • Naturally exploits ILP,even across loop iterations /32
Conclusions • ASH = Compiler-synthesized hardware • ASH matches program parallelism • Dynamically scheduled RH • ASH scales with • clock frequency • transistors • program size /32
Backup Slides /32
Interconnection network Universal gates and/or storage elements Programmable switches Reconfigurable Hardware /32
Main RH Ingredient: RAM Cell 0 0 0 1 a0 data a0 a1 & a2 a1 a1 Universal gate = RAM data in 0 control Switch controlled by a 1-bit RAM cell /32
Stubs a( ) { r = b’(b_args); } a( ) { r = b(b_args); } b(b_args) { } b’(b_args) { send_rh(b_args); invoke_rh(b); r = receive_rh( ); return r;} RH Program /32
Independent of b Dispatcher Stubs a( ) { r = b(b_args); } b(b_args) { if (x) c( ); return r; } c( ) { } b’(b_args) { send_rh(b_args); invoke_rh(b); while (1) { com = get_rh_command( ); if (! com) break; (*com)( ); } r = receive_rh( ); return r;} c’s stub Program /32
C’s Stub a( ) { r = b(b_args); } b(b_args) { if (x) c( ); return r; } c( ) { } c’( ) { receive_rh(c_args); r = c(c_args); send_rh(r); invoke_rh(return_to_rh);} Program back /32
Input to Output int io(int x) { return x; } /32
Loops int loop() { int w = 10; while (w > 0) w--; return w; } /32
Pointers and Arrays int a[10]; void pointer(int *p) { a[2] += a[4] + *p; } /32
Pointers and Loops int sum() { int s = 0; int i; for (i=0; i < 10; i++) s += a[i]; return s; } /32