Download
1 / 1
10 likes | 188 Vues
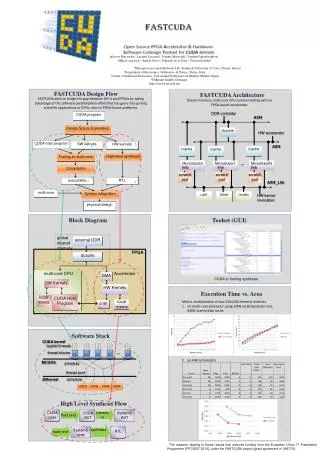
global shared memory . external DDR . CUDA program. FPGA . Design Space Exploration. dcache. CUDA host program. SW kernels. HW kernels. multi-core CPU. Accelerator . DMA. SW Kernels. High-level synthesis . Porting to multi-core . DDR controller . HW Kernels. AXI4 . Compilation.

E N D
global shared memory external DDR CUDA program FPGA Design Space Exploration dcache CUDA host program SW kernels HW kernels multi-core CPU Accelerator DMA SW Kernels High-level synthesis Porting to multi-core DDR controller HW Kernels AXI4 Compilation local mems CUDA Host Program local mems dcache cntrl HW accelerator executable RTL AXI4 CUDA code transform SystemC AST CUDA AST icache icache front end icache multi-core System Integration physical design synthesis Microblaze0 Microblaze1 ... MicroblazeN SystemC code RTL back end lmb lmb lmb scratch pad scratch pad scratch pad AXI4_Lite uart timer mutex HW kernel invocation CUDA kernel logical threads ... thread blocks MCUDA schedule thread pool schedule Xilkernel core core core core Iakovos Mavroidis1, Luciano Lavagno2, Ioannis Mavroidis1, Ioannis Papaefstathiou1, Mihai Lazarescu2, Andrés Otero3, Eduardo de la Torre3, Florian Schäfer4 1Microprocessor and Hardware Lab, Technical University of Crete, Chania, Greece 2Department of Electronics, Politecnico di Torino, Torino, Italy 3Centre of Industrial Electronics, Universidad Politécnica de Madrid, Madrid, Spain 4FSResult GmbH, Germany http://www.fastcuda.eu/ • FASTCUDA Design Flow • FASTCUDA Architecture FASTCUDA aims to bridge the gap between GPUs and FPGAs by taking advantage of the software parallelization effort that has gone into porting scientific applications to GPUs, also on FPGA-based platforms. Shared memory, multi-core CPU communicating with an FPGA-based accelerator. • Block Diagram • Toolset (GUI) CUDA to Verilog synthesis • Execution Time vs. Area Matrix multiplication of two 256x256 element matrices on multi-core processor using 32KB scratchpad per core, 64KB shared data cache on HW accelerator • Software Stack • High Level Synthesis Flow The research leading to these results has received funding from the European Union 7th FrameworkProgramme [FP7/2007-2013], under the FASTCUDA project (grant agreement no 286770).