Download
1 / 9
160 likes | 779 Vues
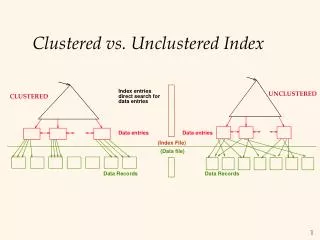
Clustered vs. Unclustered Index. Index entries. UNCLUSTERED. CLUSTERED. direct search for . data entries. Data entries. Data entries. (Index File). (Data file). Data Records. Data Records. B+ Tree Indexes. Non-leaf. Pages. Leaf. Pages (Sorted by search key).

E N D
Clustered vs. Unclustered Index Index entries UNCLUSTERED CLUSTERED direct search for data entries Data entries Data entries (Index File) (Data file) Data Records Data Records
B+ Tree Indexes Non-leaf Pages Leaf Pages (Sorted by search key) • Index leaf pages containdata entries, and are chained (prev & next) • Index non-leaf pages have index entries; only used to direct searches: index entry P K P K P P K m 0 1 2 1 m 2
Example B+ Tree Note how data entries in leaf level are sorted Root 17 • Find: 29*? 28*? All > 15* and < 30* • Insert/delete: Find data entry in leaf, then change it. Entries < 17 Entries >= 17 27 5 13 30 39* 2* 3* 5* 7* 8* 22* 24* 27* 29* 38* 33* 34* 14* 16*
Cost Model for Our Analysis • Notes: • We ignore CPU costs, for simplicity. • Measuring number of page I/Os ignores gains of pre-fetching a sequence of pages • Thus even I/O cost is only approximated. • Average-case analysis; based on simplistic assumptions. • Good enough to show overall trends!
Cost Model for Our Analysis Variables : • B: The number of data pages • R: Number of records per page
Comparing File Organizations • Heap files (random order; insert at eof) • Sorted files, sorted on <age, sal> • Clustered B+ tree file, search key <age, sal> • Heap file with unclustered B + tree index on search key <age, sal> • Heap file with unclustered hash index on search key <age, sal>
Operations to Compare • Scan: Fetch all records from disk • Equality search • Range selection • Insert a record • Delete a record
Assumptions in Our Analysis • Heap Files: • Equality selection on key; exactly one match. • Sorted Files: • Files compacted after deletions. • Indexes: • data entry size/pointers = 10% size of data record • Hash: No overflow buckets. • 80% page occupancy => “File size = 1.25 data size” • Tree: 67% occupancy (this is typical). • “Implies file size = 1.5 data size” • Scans: • Leaf levels of a tree-index are chained. • Index data-entries plus actual file scanned for unclustered indexes. • Range searches: • We use tree indexes to restrict set of data records fetched, but ignore hash indexes.
Cost of Operations • Several assumptions underlie these (rough) estimates!