Download

1 / 20
200 likes | 288 Vues
The system aims to offer access, ease of use, data manipulation, and search capabilities for in-depth linguistic research, addressing multiple linguistic structures and features. Linguists can search, extract, annotate, and share linguistic resources efficiently. It provides detailed documentation, meta-information, and enhanced search tools for linguistic analysis.

E N D
What Linguists Want (we think) Helen Aristar Dry & Anthony Aristar LINGUIST List & E-MELD
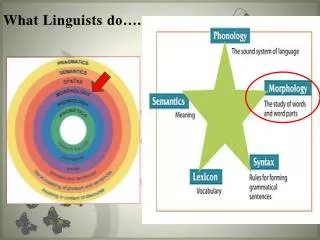
Language Documentation Used • Research: • Historical / comparative Ling • Typology • Language description • Phonology & phonetics • Syntax • Psycholinguistics • Discourse Analysis • Anthropological linguistics • Ethnomusicology • Teaching of all of the above
So they want • Access • Central index of available material that supports flexible searching • Ability to preview material • Clear indication of access rights • Fast permissions (24-hour turnaround) • Stability • Cited versions of resources still available • Assembled sub-corpora available for a specified period of time, e.g., for the duration of a course
Ease of use • Single interface — things work the same way in different archives (hard to misunderestimate the technical skill of academics) • Registration that persists—i.e., they don’t have to keep filling out registration forms These desiderata addressed in Scenarios 4 and 5
And they would like • Ability to manipulate the data • To annotate corpus & share annotations with co-researchers • To track their own annotations & additions (as opposed to those of others) • To use a concordance program or other text processing program on the corpus • To extract relevant portions of texts and create a sub-sub-corpus; to share this sub-corpus with co-researchers or students
They would REALLY like • Ability to identify resources by searching for linguistic structures, e.g. • Morphosyntactic categories (classifiers) • Morphosyntactic features (paucal) • Phonetic features (nasalization)* • Supersegmentals (tone)* • E.g. to search, not just the metadata, but the annotations and transcriptions of the archived material. *transcriptions, not sound — though search by sound would be even better
Structures central to: • Research: • Historical / comparative Ling • Typology • Language description • Phonology & phonetics • Syntax • Teaching of all of the above
Want to answer Qs like: • Do all IE languages have a contrast between voiced and unvoiced consonants? • Which languages have a distinction between trial and paucal number? • Where can I find examples of voiceless nasals (e.g., for a phonology problem)?
Need to search for… • Morphemes representing morphosyntactic categories and features • Phonetic segments • Co-occurrences of segments, categories, & features
Need to search by • Language families and subgroups • Feature classes (e.g. “stops”, not [ b ] ) • Morphosyntactic concepts (not just terminology, as this varies)
Requires enhanced • Documentation • Meta-information • Search tools
Documentation • Complete & transparent phonetic transcription • Detailed & transparent morphosyntactic annotation • Unambiguous language identification & classification
Meta-Information • Unambiguous language identification system (language codes) • Language classification system, organizing languages into families and subgroups • Structured (graphic) taxonomy of phonetic features
Meta-Information • Structured taxonomy of morphosyntactic categories and features (concepts and definitions) • Lists of morphosyntactic terminology in use by various groups • Mapping of the different terminology sets to the concepts and definitions
Search tools that can • Interpret meta-information • Use it to construct intelligent searches • Search • Annotation & Transcription • OR Language profiles • OR Annotation indexes
What we have • New Documentation • Audio / video recordings w/ translation • Phonetic transcription • Little morphosyntactic annotation (sometimes) • Legacy documentation • Detailed morphosyntactic annotation • Complete phonetic transcription • Non-transparent (idiosyncratic) markup • Inaccessible format (e.g., paper)
What we have • Meta-information • Ontology of morphosyntactic concepts (GOLD —and others?) • Terminology sets (DatCat Registry) • Ontology of phonetic features • Language codes & associated family trees (Ethnologue based)
What we have • Search • Prototype search of phonetic transcription using ontology of phonetic features, e.g. “Find all voiceless stops.” • Steps toward search of morphosyntactic features: • Language profiles which give the morphosyntactic categories and features used in a language (in XML) • Conversion path for • mapping idiosyncratic markup to the GOLD ontology (metaschemas + XSLT) • Converting GOLD compliant markup into RDF for searching via semantic web
What we have: Tools • For ontology-based morphosyntactic annotation • OntoElan (MPI’s Elan + ontology-based terminology mapper) • OntoGloss (ontology-aware stand-off annotation of web documents) • For creating language profiles • FIELD
What we need • Comprehensive, integrated system that supports this kind of searching • “Architecture, not just tools”