Comprehensive Text Organization Solution for Document Corpus
This tool provides a structured hierarchy from digital media to individual terms, aiding in document categorization and concept extraction. Incorporating Latent Semantic Indexing (LSI) principles, it establishes semantic relationships and enhances search accuracy. Overcoming limitations of traditional Boolean queries, LSI improves retrieval by correlating semantically related terms latent in text collections. Automatic document categorization based on conceptual analysis is a key feature.

Comprehensive Text Organization Solution for Document Corpus
E N D
Presentation Transcript
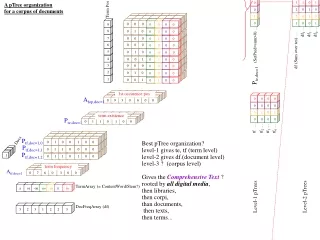
3 0 A pTree organization for a corpus of documents 2 0 Term Pos 2 1 1 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 df (Sum over tes) ... 0 1 0 0 0 0 0 Pte,doc=1(SetPred=sum>0) ... 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 9 7 1 1 1 1 6 0 1 1 3 1 0 0 0 0 0 0 6 1 3 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 1st occurence pos 0 0 0 1 1 0 0 Afop,doc=1 0 0 0 0 1 0 0 1 0 0 1 1 0 3 term existence 0 0 0 0 1 0 0 Pte,doc=1 in 2 it 2 Docs Ptf,doc=1,0 tf2 ... tf0 ... df2 ... tf1 ... df0 ... tf ... df1 ... Ptf,doc=1,1 Ptf,doc=1,2 1 1 1 Atf,doc=1 9 6 3 TermArray (= ContentWord/Stem?) 5 2 8 DocFreqArray (df) 7 1 4 term frequency 3 to a 3 or 2 on 3 1 no Best pTree organization? level-1 gives te, tf (term level) level-2 gives df.(document level) level-3 ? (corpus level) Gives the Comprehensive Text ? rooted by all digital media, then libraries, then corpi, than documents, then texts, then terms... Level-1 pTrees Level-2 pTrees
book1 I Heard a Little Baa 22 words book2 Mr. Grumpy's Outing 32 words book3 The Very Hungry Caterpillar 28 words book4 Pat The Bunny 32 words book5 Goodnight Moon 14 words book6 Moo Baa La La La 24 words book7 Clap hands 18 words this lively rhyming book gives readers a chance to practice animal sounds identify animals and guess what animal is coming up next on a perfect summer day mr grump decides to take a ride on the river in his small boat a goats kick causes a cumulative effect and everyone lands in the water a very hungry caterpillar works his way through holes cut into pages as he eats a variety of foods spins his cocoon and emerges as a beautiful butterfly the classic touch and feel book in which a boy and girl experience the world around them by patting a bunny looking in a mirror smelling flowers and touching daddys scrathy face a young rabbit says goodnight to everything in his room before bedtime the animals in this rhyming board book demonstrate the very different and amusing sounds that they make the humor is just right for toddlers clap hands dance and spin open wide and pop it in sweet babies go through various rhymed activities
book8 Spots, Feathers and Curly Tails 31 words book9 Baby Bathtime 13 words book10 Higher, Higher 29 words book11 Rhymes Round the World 19 words book12 Shades of People 18 words book13 The Sleepy Little Alphabet 32 words book14 Ten Tiny Babies 14 words who does that curly tail belong to what animal has black and white spots just turn the page to reveal the familiar farm animals that match the verbal and visual clues this lift the flap board book helps babies explore the world around them when her dad pushes a young girl in a swing she goes higher higher until she reaches fantastical heights and meets an airplane a rocket and even an alien rhymes and songs from across the globe will delight young children full page illustrations dramatize the sense of play beautiful full color photographs of children along with a simple text highlight the many shades of skin color parents try to round up the letters of the alphabet as they skitter scatter helter skelter rhyming text and humorous illustrations highlight each letter until they are all finally asleep in bed babies enjoy a bouncy noisy day until they are finally fast asleep at night
Latent semantic indexing (LSI) is an indexing and retrieval method that uses Singular value decomposition to identify patterns in the relationships between the terms and concepts contained in an unstructured collection of text. LSI is based on the principle that words that are used in the same contexts tend to have similar meanings. LSI feature: ability to extract conceptual content of a body of text by establishing assoc between those terms that occur in similar contexts.[1] Called Latent Semantic Indexing because of its ability to correlate semantically related terms that are latent in a collection of text. It uncovers the underlying latent semantic structure in the usage of words in a body of text and how it can be used to extract the meaning of the text in response to user queries, commonly referred to as concept searches. Queries against a set of docs that have undergone LSI will return results that are conceptually similar in meaning to search criteria even if results don’t share specific word or words with the search criteria. Benefits of LSI: LSI overcomes two of the most problematic constraints of Boolean keyword queries: multiple words that have similar meanings (synonymy) and words that have more than one meaning (polysemy). Synonymy and polysemy are often the cause of mismatches in the vocabulary used by authors of docs and users of info retrieval systems.[3] As a result, Boolean keyword queries often return irrelevant results and miss information that is relevant. LSI is also used to perform automated document categorization. Doc categorization is assignment of docs to one or more predefined categories based on their similarity to conceptual content of the categories.[5] LSI uses example documents to establish the conceptual basis for each category. During categorization, the concepts contained in the docs being categorized are compared to the concepts contained in the example items, and a category (or categories) is assigned to the docs based on similarities between concepts they contain and the concepts contained in ex docs Dynamic clustering based on the conceptual content of docs uses LSI. Clustering is a way to group docs based on their conceptual similarity to each other without using example docs to establish the conceptual basis for each cluster - useful with an unknown collection of unstructured text. Because it uses a strictly mathematical approach, LSI is inherently independent of language. This enables LSI to elicit the semantic content of information written in any language without requiring the use of auxiliary structures, such as dictionaries and thesauri. LSI is not restricted to working only with words. It can also process arbitrary character strings. Any object that can be expressed as text can be represented in an LSI vector space.[6] e.g., tests with MEDLINE abstracts have shown that LSI is able to effectively classify genes based on conceptual modeling of the biological information contained in the titles and abstracts of the MEDLINE citations.[7] LSI automatically adapts to new and changing terminology, and has been shown to be very tolerant of noise (i.e., misspelled words, typographical errors, unreadable characters, etc.).[8] This is especially important for applications using text derived from Optical Character Recognition (OCR) and speech-to-text conversion. LSI also deals effectively with sparse, ambiguous, and contradictory data. Text does not need to be in sentences. It can work with lists, free-form notes, email, Web-based content, etc. As long as a collection of text contains multiple terms, LSI can be used to identify patterns in relationships between important terms and concepts contained in the text. LSI has proven to be a useful solution to a number of conceptual matching problems.[9][10] LSI used to capture key relationship information, including causal, goal-oriented, and taxonomic information.[11] LSI Timeline Mid-1960s – Factor analysis technique first described and tested (H. Borko and M. Bernick) 1988 – Seminal paper on LSI technique published (Deerwester et al.) 1989 – Original patent granted (Deerwester et al.) 1992 – First use of LSI to assign articles to reviewers[12] (Dumais and Nielsen) 1994 – Patent granted for the cross-lingual application of LSI (Landauer et al.) 1995 – First use of LSI for grading essays (Foltz, et al., Landauer et al.) 1999 – First implementation of LSI technology for intelligence community for analyzing unstructured text (SAIC). 2002 – LSI-based product offering to intelligence-based government agencies (SAIC) 2005 – First vertical-specific application – publishing – EDB (EBSCO, Content Analyst Company)
Mathematics of LSI (linear algebra techniques to learn the conceptual correlations in a collection of text). Construct a weighted term-document matrix, do Singular Value Decomposition on it. Use that to identify the concepts contained in the text. Term Document Matrix, A: Each (of m) term is represented by a row, and each (of n) doc is represented by a column, with each matrix cell, aij, initially representing number of times the associated term appears in the indicated document, tfij. This matrix is usually large and very sparse. Once a term-document matrix is constructed, local and global weighting functions can be applied to it to condition the data. The weighting functions transform each cell, of , to be the product of a local term weight, , which describes the relative frequency of a term in a document, and a global weight, , which describes the relative frequency of the term within the entire collection of documents. Some common local weighting functions [13] are defined in the following table. Binary if the term exists in the document, or else TermFrequency , the number of occurrences of term in document LogAugnorm Some common global weighting functions are defined in the following table. BinaryNormalGfIdf , where is the total number of times term occurs in the whole collection, and is the number of documents in which term occurs.IdfEntropy , where Empirical studies with LSI report that the Log Entropy weighting functions work well, in practice, with many data sets.[14] In other words, each entry of is computed as: